8.1: Незважена лінійна регресія з помилками у y




- Last updated
- Oct 25, 2022
- Save as PDF
Найбільш поширений метод завершення лінійної регресії робить три припущення:
- різниця між нашими експериментальними даними та обчисленою лінією регресії є результатом невизначеної помилки, що впливають на y
- будь-які невизначені помилки, які впливають на y, зазвичай розподіляються
- що невизначені помилки в y не залежать від значення x
Оскільки ми припускаємо, що невизначені помилки однакові для всіх стандартів, кожен стандарт однаково вносить свій внесок у нашу оцінку нахилу та y -перехоплення. З цієї причини результат вважається незваженою лінійною регресією.
Друге припущення, як правило, вірно через центральну граничну теорему, яку ми розглянули в розділі 5.3. Обґрунтованість двох інших припущень менш очевидна, і ви повинні оцінити їх, перш ніж приймати результати лінійної регресії. Зокрема, перше припущення завжди підозрюється, оскільки, безумовно, є певна невизначена похибка вимірювання x. Коли ми готуємо калібрувальну криву, однак, незвично виявити, що невизначеність у сигналі, S, значно більша, ніж невизначеність концентрації аналітаCA. За таких обставин перше припущення зазвичай є розумним.
Як працює лінійна регресія
Щоб зрозуміти логіку лінійної регресії, розглянемо приклад на малюнку8.1.1, який показує три точки даних і дві можливі прямі лінії, які можуть обґрунтовано пояснити дані. Як ми вирішуємо, наскільки добре ці прямі лінії підходять до даних, і як ми можемо визначити, яка, якщо так, є найкращою прямою лінією?
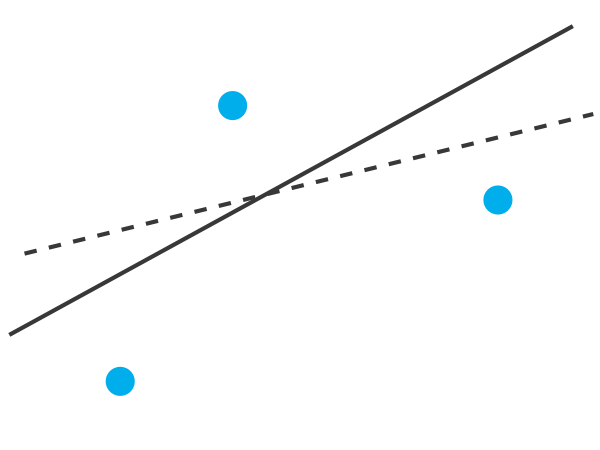
Давайте зосередимося на суцільній лінії на малюнку8.1.1. Рівняння для цього рядка
ˆy=b0+b1x
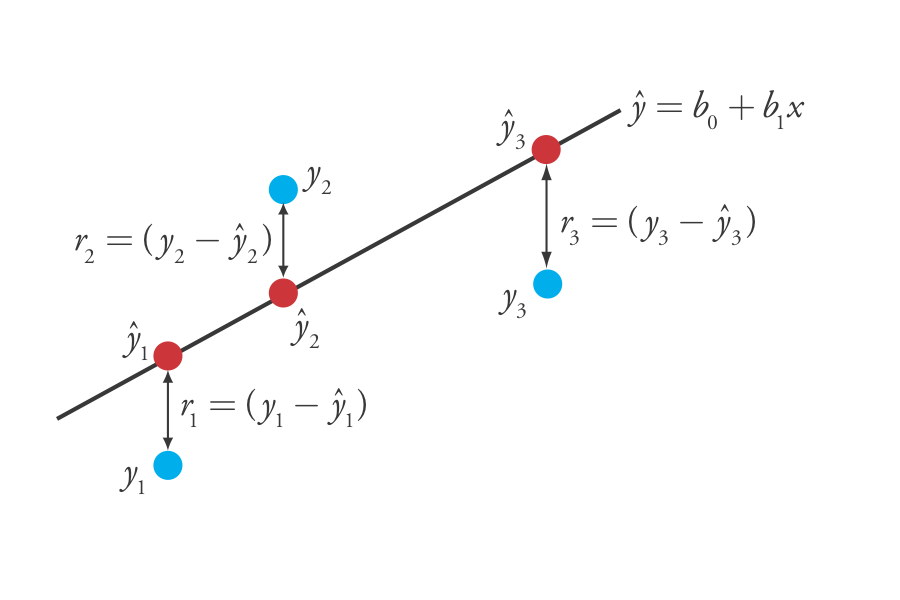
де b 0 і b 1 - оцінки для y -перехоплення та нахилу, іˆy є прогнозованим значенням y для будь-якого значення x. Оскільки ми припускаємо, що вся невизначеність є результатом невизначеної помилки у, різниця між y іˆy для кожного значення x є залишковою похибкою, r, в нашій математичній моделі.
ri=(yi−ˆyi)
8.1.2На малюнку показані залишкові помилки для трьох точок даних. Чим менше загальна залишкова помилка, R, яку ми визначаємо як
R=n∑i=1(yi−ˆyi)2
тим краще прилягання між прямою лінією і даними. У лінійному регресійному аналізі ми шукаємо значення b 0 та b 1, які дають найменшу загальну залишкову похибку.
Причиною квадратизації окремих залишкових помилок є запобігання позитивної залишкової помилки від скасування негативної залишкової помилки. Ви бачили це раніше в рівняннях для вибірки і популяції стандартних відхилень, введені в главі 4. З цього рівняння також видно, чому лінійну регресію іноді називають методом найменших квадратів.
Пошук нахилу та y -перехоплення для регресійної моделі
Хоча формально ми не будемо розробляти математичні рівняння для лінійного регресійного аналізу, ви можете знайти похідні в багатьох стандартних статистичних текстах [Див., наприклад, Draper, Н.Р.; Smith, H. Прикладний регресійний аналіз, 3-е видання; Wiley: Нью-Йорк, 1998]. Отримане рівняння для ухилу, b 1, дорівнює
b1=n∑ni=1xiyi−∑ni=1xi∑ni=1yin∑ni=1x2i−(∑ni=1xi)2
і рівняння для y -перехоплення, b 0, дорівнює
b0=∑ni=1yi−b1∑ni=1xin
Хоча ці рівняння здаються грізними, необхідно лише оцінити наступні чотири підсумовування
n∑i=1xin∑i=1yin∑i=1xiyin∑i=1x2i
Багато калькуляторів, електронних таблиць та інших статистичних програмних пакетів здатні виконувати лінійний регресійний аналіз на основі цієї моделі; докладніше про завершення лінійного регресійного аналізу за допомогою R. наступний приклад.
Використовуючи дані калібрування в наступній таблиці, визначте взаємозв'язок між сигналом та концентрацією аналітаxi, використовуючи незважену лінійну регресію.yi
Рішення
Ми починаємо з налаштування таблиці, яка допоможе нам організувати розрахунок.
| xi | yi | xiyi | x2i |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.00 | \ (x_i y_i\) ">0.000 | \ (x_i ^ 2\) ">0.000 |
| \ (x_i\) ">0.100 | \ (y_i\) ">12,36 | \ (x_i\) ">1.236 | \ (x_i^2\) ">0,010 |
| \ (x_i\) ">0,200 | \ (y_i\) ">24.83 | \ (x_i\) ">4.966 | \ (x_i^2\) ">0,040 |
| \ (x_i\) ">0,300 | \ (y_i\) ">35.91 | \ (x_i\) ">10.773 | \ (x_i^2\) ">0,090 |
| \ (x_i\) ">0,400 | \ (y_i\) ">48.79 | \ (x_i\) ">19.516 | \ (x_i^2\) ">0.160 |
| \ (x_i\) ">0,500 | \ (y_i\) ">60.42 | \ (x_i\) ">30.210 | \ (x_i^2\) ">0,250 |
Додавання значень у кожному стовпці дає
n∑i=1xi=1.500n∑i=1yi=182.31n∑i=1xiyi=66.701n∑i=1x2i=0.550
Підставляючи ці значення в рівняння для нахилу і y -перехоплення дає
b1=(6×66.701)−(1.500×182.31)(6×0.550)−(1.500)2=120.706≈120.71
b0=182.31−(120.706×1.500)6=0.209≈0.21
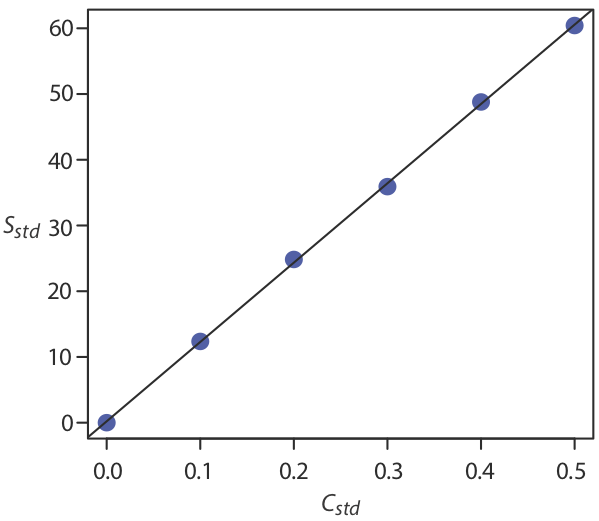
Взаємозв'язок міжS сигналом та концентрацією аналітаCA, отже, становить
S=120.71×CA+0.21
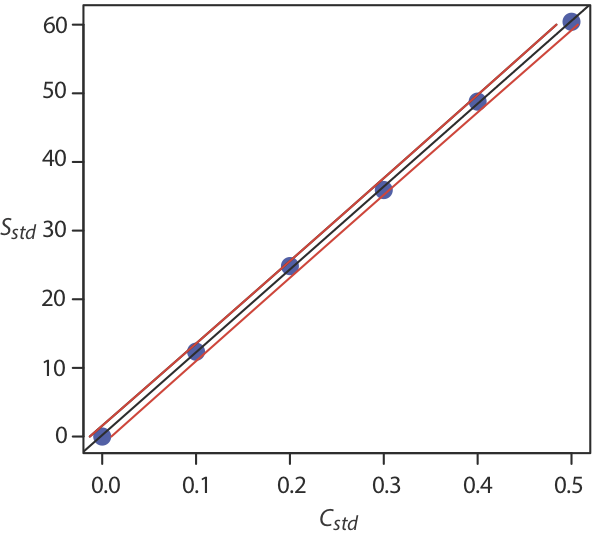
Наразі ми зберігаємо два знака після коми, щоб відповідати кількості десяткових знаків у сигналі. Отримана калібрувальна крива показана на малюнку8.1.3.
Невизначеність у регресійній моделі
Як ми бачимо на малюнку8.1.3, через невизначені помилки в сигналі лінія регресії не проходить через точний центр кожної точки даних. Сукупне відхилення наших даних від лінії регресії - загальна залишкова похибка - пропорційно невизначеності в регресії. Ми називаємо цю невизначеність стандартним відхиленням про регресію, s r, яка дорівнює
sr=√∑ni=1(yi−ˆyi)2n−2
де y i - i експериментальне значення, іˆyi відповідне значення, передбачене рівнянням регресіїˆy=b0+b1x. Зауважте, що знаменник вказує на те, що наш регресійний аналіз має n - 2 ступеня свободи - ми втрачаємо два ступені свободи, оскільки використовуємо два параметри, нахил і y -перехоплення, для обчисленняˆyi.
Більш корисним поданням невизначеності в нашому регресійному аналізі є врахування впливу невизначених помилок на нахил, b 1, і y -перехоплення, b 0, який ми виражаємо як стандартні відхилення.
sb1=√ns2rn∑ni=1x2i−(∑ni=1xi)2=√s2r∑ni=1(xi−¯x)2
sb0=√s2r∑ni=1x2in∑ni=1x2i−(∑ni=1xi)2=√s2r∑ni=1x2in∑ni=1(xi−¯x)2
Ми використовуємо ці стандартні відхилення для встановлення довірчих інтервалів для очікуваного нахилу та очікуваного y -перехоплення,β1β0
β1=b1±tsb1
β0=b0±tsb0
де виділено t для рівня значущості,α а для n — 2 ступенів свободи. Зауважте, що ці рівняння не містять коефіцієнта, що(√n)−1 спостерігається у довірчихμ інтервалах для розділу 6.2; це пов'язано з тим, що довірчий інтервал тут базується на одній лінії регресії.
Обчисліть 95% довірчих інтервалів для нахилу та y -перехоплення з Прикладу8.1.1.
Рішення
Почнемо з розрахунку стандартного відхилення про регресію. Для цього ми повинні обчислити передбачені сигналиˆyi, використовуючи нахил і y -перехоплення з Прикладу8.1.1, і квадрати залишкової похибки,(yi−ˆyi)2. Використовуючи останній стандарт як приклад, ми виявимо, що передбачуваний сигнал
ˆy6=b0+b1x6=0.209+(120.706×0.500)=60.562
і що квадрат залишкової похибки
(yi−ˆyi)2=(60.42−60.562)2=0.2016≈0.202
Наступна таблиця відображає результати для всіх шести рішень.
| xi | yi | ˆyi |
(yi−ˆyi)2 |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.00 | \ (\ hat {y} _i\) ">0.209 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.0437 |
| \ (x_i\) ">0.100 | \ (y_i\) ">12,36 | \ (\ hat {y} _i\) ">12.280 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.0064 |
| \ (x_i\) ">0,200 | \ (y_i\) ">24.83 | \ (\ hat {y} _i\) ">24.350 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.2304 |
| \ (x_i\) ">0,300 | \ (y_i\) ">35.91 | \ (\ hat {y} _i\) ">36.421 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.2611 |
| \ (x_i\) ">0,400 | \ (y_i\) ">48.79 | \ (\ hat {y} _i\) ">48.491 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.0894 |
| \ (x_i\) ">0,500 | \ (y_i\) ">60.42 | \ (\ hat {y} _i\) ">60.562 | \ (\ ліворуч (y_i -\ hat {y} _i\ праворуч) ^2\) ">0.0202 |
Складання даних в останньому стовпці дає чисельник у рівнянні для стандартного відхилення про регресію; таким чином
sr=√0.65126−2=0.4035
Далі обчислюємо стандартні відхилення для ухилу і y -перехоплення. Значення термінів підсумовування взяті з Приклад8.1.1.
sb1=√6×(0.4035)2(6×0.550)−(1.500)2=0.965
sb0=√(0.4035)2×0.550(6×0.550)−(1.500)2=0.292
Нарешті, 95% довірчих інтервалів (α=0.054 ступеня свободи) для нахилу та y -перехоплення є
β1=b1±tsb1=120.706±(2.78×0.965)=120.7±2.7
β0=b0±tsb0=0.209±(2.78×0.292)=0.2±0.80
де t (0,05, 4) з додатка 2 дорівнює 2.78. Стандартне відхилення щодо регресії, s r, говорить про те, що сигнал, S std, точний до одного знака після коми. З цієї причини ми повідомляємо нахил і y -перехоплення до одного знака після коми.
Використання моделі регресії для визначення значення для x, заданого значення для y
Після того, як ми отримаємо наше рівняння регресії, легко визначити концентрацію аналіту в зразку. Наприклад, коли ми використовуємо нормальну калібрувальну криву, ми вимірюємо сигнал для нашого зразка, S samp, і обчислюємо концентрацію аналіта, C A, використовуючи рівняння регресії.
CA=Ssamp−b0b1
Менш очевидним є те, як повідомити про довірчий інтервал для C A, який виражає невизначеність в нашому аналізі. Для обчислення довірчого інтервалу нам потрібно знати стандартне відхилення в концентрації аналітаsCA, яке задається наступним рівнянням
sCA=srb1√1m+1n+(¯Ssamp−¯Sstd)2(b1)2∑ni=1(Cstdi−¯Cstd)2
де m - кількість реплікацій, які ми використовуємо для встановлення середнього сигналу зразка, S samp, n - кількість калібрувальних стандартів, S std - середній сигнал для калібрування стандарти,Cstdi і¯Cstd є індивідуальними та середніми концентраціями для стандартів калібрування. Знаючи значенняsCA, довірчий інтервал для концентрації аналіта становить
μCA=CA±tsCA
деμCA - очікуване значення С А при відсутності детермінантних похибок, а при значенні t базується на бажаному рівні довіри і n — 2 ступеня свободи.
Ретельне вивчення цих рівнянь повинно переконати вас, що ми можемо зменшити невизначеність прогнозованої концентрації аналіту,CA якщо ми збільшимо кількість стандартівn, збільшимо кількість повторюваних зразків, які ми аналізуємоm, і якщо середній сигнал зразка, ¯Ssamp, Прирівнюється до середнього сигналу за стандартами,¯Sstd. Коли це практично, слід спланувати калібрувальну криву так, щоб S samp потрапляла посередині калібрувальної кривої. Для отримання додаткової інформації про ці рівняння регресії див. (а) Міллер, Дж. Аналітик 1991, 116, 3—14; (б) Шараф, М.А.; Іллман, Д.Л.; Ковальський, Б.Р. Хемометрика, Wiley-Interscience: Нью-Йорк, 1986, стор. 126-127; (c) Комітет з аналітичних методів» Невизначеність концентрацій, оцінених в результаті калібрувальних експериментів», Технічний бриф КУА, березень 2006.
Рівняння стандартного відхилення в концентрації аналіта записано в терміні калібрувального експерименту. Тут наведено більш загальну форму рівняння, записаного через x і y.
sx=srb1√1m+1n+(¯Y−¯y)2(b1)2∑ni=1(xi−¯x)2
Три репліковані аналізи для зразка, який містить невідому концентрацію аналіту, дає значення для S samp 29,32, 29.16 та 29.51 (довільні одиниці). Використовуючи результати з8.1.1 Example and Example8.1.2, визначити концентрацію аналіта, C A та його 95% довірчий інтервал.
Рішення
Середній сигнал становить 29.33, який, використовуючи нахил і y -перехоплення з Прикладу8.1.1, дає концентрацію аналіта як¯Ssamp
CA=¯Ssamp−b0b1=29.33−0.209120.706=0.241
Щоб розрахувати стандартне відхилення для концентрації аналіта, ми повинні визначити значення для¯Sstd і за∑2i=1(Cstdi−¯Cstd)2. Перший - це якраз середній сигнал по нормам калібрування, який, використовуючи дані в таблиці8.1.1, дорівнює 30.385. Обчислення∑2i=1(Cstdi−¯Cstd)2 виглядає грізним, але ми можемо спростити його обчислення, визнавши, що ця сума квадратів є чисельником у рівнянні стандартного відхилення; таким чином,
n∑i=1(Cstdi−¯Cstd)2=(sCstd)2×(n−1)
деsCstd - стандартне відхилення для концентрації аналіту в нормах калібрування. Використовуючи дані в таблиці,8.1.1 ми знаходимо, щоsCstd це 0.1871 і
n∑i=1(Cstdi−¯Cstd)2=(0.1872)2×(6−1)=0.175
Підставляємо відомі значення в рівняння дляsCA дач
sCA=0.4035120.706√13+16+(29.33−30.385)2(120.706)2×0.175=0.0024
Нарешті, 95% довірчий інтервал для 4 ступенів свободи
μCA=CA±tsCA=0.241±(2.78×0.0024)=0.241±0.007
8.1.4На малюнку показана калібрувальна крива з кривими, що показують 95% довірчий інтервал для C A.
Оцінка регресійної моделі
Ніколи не слід приймати результат лінійного регресійного аналізу без оцінки достовірності моделі. Мабуть, найпростішим способом оцінки регресійного аналізу є вивчення залишкових помилок. Як ми бачили раніше, залишкова похибка для єдиного стандарту калібрування, r i, дорівнює
ri=(yi−ˆyi)
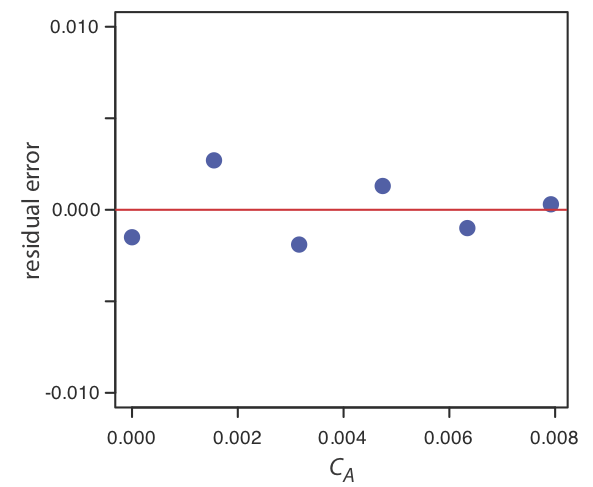
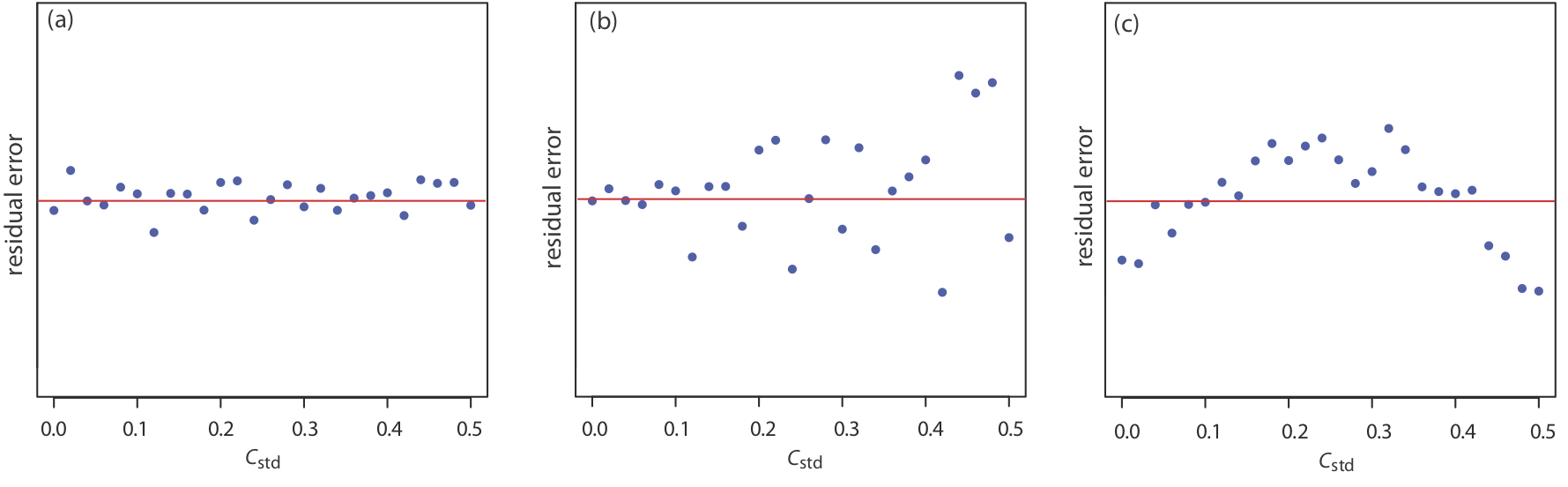
Якщо модель регресії дійсна, то залишкові помилки повинні розподілятися випадковим чином щодо середньої залишкової похибки нуля, без видимої тенденції до менших або більших залишкових помилок (рис.8.1.5a). Такі тенденції, як у малюнку8.1.5b та малюнку,8.1.5c свідчать про те, що принаймні одне з припущень моделі є неправильним. Наприклад, тенденція до більших залишкових помилок при більш високих концентраціях, Рисунок8.1.5b, свідчить про те, що невизначені помилки, що впливають на сигнал, не залежать від концентрації аналіта. На малюнку8.1.5c залишкові помилки не є випадковими, що говорить про те, що ми не можемо моделювати дані за допомогою прямолінійного співвідношення. Регресійні методи для останніх двох випадків розглядаються в наступних розділах.
Використовуйте свої результати з вправи,8.1.1 щоб побудувати залишковий сюжет і пояснити його значення.
Рішення
Для створення залишкової ділянки нам потрібно обчислити залишкову похибку для кожного стандарту. Наступна таблиця містить відповідну інформацію.
| xi | yi | ˆyi | yi−ˆyi |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.000 | \ (\ hat {y} _i\) ">0.0015 | \ (y_i -\ hat {y} _i\) ">—0.0015 |
| \ (x_i\) ">1.55×10−3 | \ (y_i\) ">0,050 | \ (\ hat {y} _i\) ">0.0473 | \ (y_i -\ hat {y} _i\) ">0.0027 |
| \ (x_i\) ">3.16×10−3 | \ (y_i\) ">0,093 | \ (\ hat {y} _i\) ">0.0949 | \ (y_i -\ hat {y} _i\) ">—0.0019 |
| \ (x_i\) ">4.74×10−3 | \ (y_i\) ">0.143 | \ (\ hat {y} _i\) ">0.1417 | \ (y_i -\ hat {y} _i\) ">0.0013 |
| \ (x_i\) ">6.34×10−3 | \ (y_i\) ">0.188 | \ (\ hat {y} _i\) ">0.1890 | \ (y_i -\ hat {y} _i\) ">—0,0010 |
| \ (x_i\) ">7.92×10−3 | \ (y_i\) ">0,236 | \ (\ hat {y} _i\) ">0.2357 | \ (y_i -\ hat {y} _i\) ">0.0003 |
На малюнку нижче показана схема отриманих залишкових помилок. Залишкові помилки з'являються випадковими, хоча вони чергуються за знаком, і вони не виявляють значної залежності від концентрації аналіта. Разом ці спостереження свідчать про те, що наша регресійна модель є доречною.