7.2: Тести значущості для нормальних розподілів




- Last updated
- Oct 25, 2022
- Save as PDF

Звичайний розподіл - це найпоширеніший розподіл даних, які ми збираємо. Оскільки площа між будь-якими двома межами нормальної кривої розподілу чітко визначена, легко побудувати та оцінити тести на значущість.
Властивості звичайного розподілу можна переглянути у главах 5 та 6.
Порівняння¯X зμ
Одним із способів перевірки нового аналітичного методу є аналіз зразка, який містить відому кількість аналітуμ. Щоб судити про точність методу, ми аналізуємо кілька частин зразка, визначаємо середню кількість аналіту у зразку та використовуємо тест на значущість¯X для порівнянняμ.¯X Нульова гіпотеза полягає в тому, що різниця між¯X іμ пояснюється невизначеними помилками, які впливають на наше визначення¯X. Альтернативна гіпотеза полягає в тому, що різниця між¯X іμ занадто велика, щоб пояснюватися невизначеною помилкою.
H0: ¯X=μ
HA: ¯X≠μ
Тестова статистика - t exp, яку ми підставляємо в довірчий інтервал дляμ
μ=¯X±texps√n
Перестановка цього рівняння і рішення дляtexp
texp=|μ−¯X|√ns
дає значення,texp колиμ знаходиться на правому краю або на лівому краї довірчого інтервалу зразка (рис.7.2.1a).
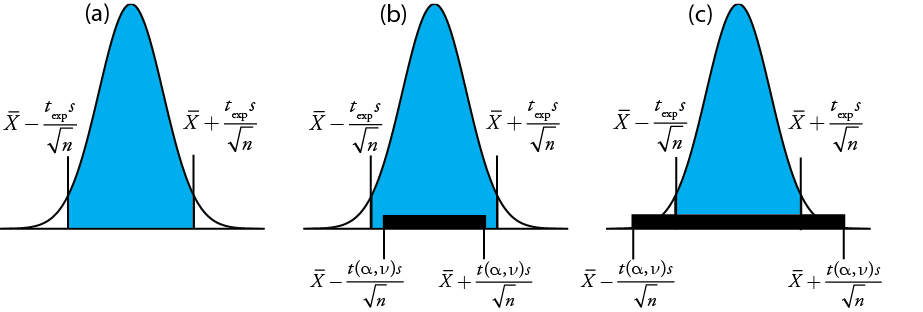
Щоб визначити, чи слід зберігати або відхиляти нульову гіпотезу, ми порівняємо значення t exp з критичним значеннямt(α,ν), деα рівень довіри таν ступені свободи для вибірки. Критичне значенняt(α,ν) визначає найбільший довірчий інтервал, пояснений невизначеною помилкою. Якщоtexp>t(α,ν), то довірчий інтервал нашої вибірки більше, ніж той, що пояснюється невизначеними помилками (рис.7.2.1 b). У цьому випадку ми відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу. Якщоtexp≤t(α,ν), то довірчий інтервал нашої вибірки менше, ніж пояснюється невизначеною помилкою, і ми зберігаємо нульову гіпотезу (рис.7.2.1 С). Приклад7.2.1 дає типове застосування цього тесту значущості, який відомий як t -тест¯X toμ. Ви знайдете значення дляt(α,ν) в Додатку 2.
Перш ніж визначити кількість Na 2 CO 3 в зразку, ви вирішили перевірити свою процедуру, проаналізувавши стандартний зразок, який становить 98,76% w/w Na 2 CO 3. П'ять реплікацій визначення% w/w Na 2 CO 3 в стандарті дають наступні результати
98.71%98.59%98.62%98.44%98.58%
Використовуючиα=0.05, чи є якісь докази того, що аналіз дає неточні результати?
Рішення
Середнє і стандартне відхилення для п'яти випробувань
¯X=98.59s=0.0973
Оскільки немає підстав вважати, що результати для стандарту повинні бути більшими або меншимиμ, ніж, доречний двохвіст t -тест. Нульова гіпотеза та альтернативна гіпотеза
H0: ¯X=μHA: ¯X≠μ
Статистика тесту, t exp, становить
texp=|μ−¯X|√n2=|98.76−98.59|√50.0973=3.91
Критичне значення для t (0,05, 4) з додатка 2 - 2,78. Оскільки t exp більше t (0,05, 4), відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу. На рівні довіри 95% різниця між¯X іμ є занадто великою, щоб пояснюватися невизначені джерела помилки, що говорить про наявність визначеного джерела помилки, що впливає на аналіз.
Є ще один спосіб інтерпретації результату цього t -тесту. Знаючи, що t exp дорівнює 3,91 і що існує 4 ступені свободи, ми використовуємо Додаток 2 для оцінки значення,α що відповідає t (α, 4) з 3.91. З додатка 2, т (0,02, 4) дорівнює 3,75, а т (0,01, 4) дорівнює 4,60. Хоча ми можемо відхилити нульову гіпотезу на рівні довіри 98%, ми не можемо відхилити її на рівні довіри 99%. Для обговорення переваг цього підходу див. Дж. С. Стерн і Г.Д. Сміт «Просіювання доказів - що не так з тестами значущості?» БМЖ 2001, 322, 226—231.
Раніше ми говорили про те, що ми повинні проявляти обережність, інтерпретуючи результат статистичного аналізу. Ми будемо продовжувати повертатися до цього моменту, оскільки це важливий. Визначивши, що результат неточний, як ми це робили в прикладі7.2.1, наступним кроком є виявлення і виправлення помилки. Однак перш ніж витрачати час і гроші на це, ми спочатку повинні критично вивчити наші дані. Наприклад, чим менше значення s, тим більше значення t exp. Якщо стандартне відхилення для нашого аналізу нереально мало, то ймовірність помилки 2 типу зростає. Включення декількох додаткових повторюваних аналізів стандарту та переоцінка t -тесту може посилити наші докази щодо визначеної помилки, або це може показати нам, що немає доказів для визначеної помилки.
Порівнянняs2 зσ2
Якщо ми регулярно аналізуємо певну вибірку, ми можемо встановити очікувану дисперсію для аналізу.σ2 Це часто трапляється, наприклад, у клінічній лабораторії, яка щодня аналізує сотні зразків крові. Кілька повторюваних аналізів одного зразка дають дисперсію зразка, s 2, значення якої може або не може суттєво відрізнятися відσ2.
Ми можемо використовувати F -тест, щоб оцінити, чи є різниця між s 2 іσ2 є значною. Нульова гіпотеза єH0: s2=σ2 і альтернативна гіпотеза єHA: s2≠σ2. Тестова статистика для оцінки нульової гіпотези - F exp, яка дається як або
Fexp=s2σ2 if s2>σ2 or Fexp=σ2s2 if σ2>s2
в залежності від того, чи є s 2 більше або менше, ніжσ2. Цей спосіб визначення F exp гарантує, що його значення завжди більше або дорівнює одиниці.
Якщо нульова гіпотеза вірна, то F exp повинна дорівнювати одиниці; однак через невизначені помилки F exp, як правило, більше одиниці. Критичне значення є найбільшим значенням F expF(α,νnum,νden), яке ми можемо віднести до невизначеної помилкиα, враховуючи заданий рівень значущості, і ступені свободи для дисперсії в чисельникуνnum, і дисперсія в знаменнику,νden. Ступінь свободи для s 2 дорівнює n — 1, де n - кількість реплікацій, що використовуються для визначення дисперсії вибірки, а ступінь свободи дляσ2 визначається як нескінченність,∞. Критичні значення F дляα=0.05 перераховані в Додатку 3 як для однохвостих, так і для двохвостих F -тестів.
Процес виробника для аналізу таблеток аспірину має відому дисперсію 25. Зразок з 10 таблеток аспірину відбирається і аналізується на кількість аспірину, даючи наступні результати в мг аспірину/таблетці.
254249252252249249250247251252
Визначте, чи є докази значної різниці між дисперсією вибірки та очікуваною дисперсією приα=0.05.
Рішення
Дисперсія для проби 10 таблеток становить 4,3. Нульова гіпотеза та альтернативні гіпотези
H0: s2=σ2HA: s2≠σ2
і значення для F exp дорівнює
Fexp=σ2s2=254.3=5.8
Критичне значення для F (0,05,∞, 9) з додатка 3 - 3,333. Оскільки F exp більше F (0,05,, 9)∞, ми відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу про те, що існує значна різниця між дисперсією вибірки та очікуваною дисперсією. Одним з пояснень різниці може бути те, що таблетки аспірину не були обрані випадковим чином.
Порівняння відхилень для двох зразків
Ми можемо розширити F -тест, щоб порівняти дисперсії для двох зразків, A і B, переписавши наше рівняння для F exp як
Fexp=s2As2B
визначення A і B таким чином, щоб значення F exp було більше або дорівнювало 1.
У таблиці нижче наведені результати двох експериментів з визначення маси циркулюючої американської пенні. Визначте, чи є різниця в дисперсіях цих аналізів наα=0.05.
| Перший експеримент | Другий експеримент | ||
|---|---|---|---|
| Пенні | Маса (г) | Пенні | Маса (г) |
| 1 | 3.080 | 1 | 3.052 |
| 2 | 3.094 | 2 | 3.141 |
| 3 | 3.107 | 3 | 3.083 |
| 4 | 3.056 | 4 | 3.083 |
| 5 | 3.112 | 5 | 3.048 |
| 6 | 3.174 | ||
| 7 | 3.198 | ||
Рішення
Стандартні відхилення для двох експериментів складають 0,051 для першого експерименту (А) і 0,037 для другого експерименту (B). Нульова та альтернативна гіпотези
H0: s2A=s2BHA: s2A≠s2B
і значення F exp дорівнює
Fexp=s2As2B=(0.051)2(0.037)2=0.002600.00137=1.90
З Додатка 3 критичне значення для F (0,05, 6, 4) дорівнює 9.197. Оскільки F exp < F (0,05, 6, 4), ми зберігаємо нульову гіпотезу. Немає жодних доказів,α=0.05 щоб припустити, що різниця в дисперсіях є значною.
Порівняння засобів для двох зразків
На результат аналізу впливають три фактори: метод, вибірка та аналітик. Ми можемо вивчити вплив цих факторів, проводячи експерименти, в яких ми змінюємо один фактор, утримуючи постійними інші фактори. Наприклад, для порівняння двох аналітичних методів ми можемо мати одного і того ж аналітика застосувати кожен метод до одного і того ж зразка, а потім вивчити отримані кошти. Подібним чином ми можемо розробляти експерименти для порівняння двох аналітиків або порівняння двох зразків.
Перш ніж розглядати тести на значущість для порівняння засобів двох вибірок, нам потрібно зрозуміти різницю між непарними даними і парними даними. Це критична відмінність, і важливо навчитися розрізняти ці два типи даних. Ось два простих приклади, які підкреслюють різницю між непарними даними та парними даними. У кожному прикладі мета полягає в тому, щоб порівняти два залишки, зважуючи копійки.
- Приклад 1: Ми збираємо 10 копійок і зважуємо кожну копійку на кожному балансі. Це приклад парних даних, оскільки ми використовуємо ті ж 10 копійок для оцінки кожного балансу.
- Приклад 2: Ми збираємо 10 копійок і ділимо їх на дві групи по п'ять копійок кожна. Зважуємо копійки в першій групі на одному балансі і зважуємо другу групу копійок на іншому балансі. Зверніть увагу, що жодна копійка не зважується на обох залишках. Це приклад непарних даних, оскільки ми оцінюємо кожен баланс, використовуючи різну вибірку копійок.
В обох прикладах вибірки 10 копійок були взяті з однієї і тієї ж популяції; різниця полягає в тому, як ми відбирали цю популяцію. Ми дізнаємося, чому ця відмінність важлива, коли ми переглядаємо тест на значущість для парних даних; однак спочатку ми представляємо тест на значущість для непарних даних.
Один простий тест для визначення того, чи є дані парними або непарними, - це подивитися на розмір кожної вибірки. Якщо зразки мають різний розмір, то дані повинні бути непарними. Зворотне не відповідає дійсності. Якщо два зразки однакового розміру, вони можуть бути парними або непарними.
Непарні дані
Розглянемо два аналізи, A і B, із засобами¯XA і¯XB, і стандартні відхилення s A і s B. Довірчі інтервали дляμA і дляμB є
μA=¯XA±tsA√nA
μB=¯XB±tsB√nB
де n A і n B - розміри вибірки для A і для B. Наша нульова гіпотеза полягає в томуH0: μA=μB, що будь-яка різниця міжμA іμB є результатом невизначеної помилки, які впливають на аналіз. Альтернативна гіпотеза полягає в томуHA: μA≠μB, що різниця міжμA іμB занадто велика, щоб пояснюватися невизначеною помилкою.
Щоб вивести рівняння для t exp, ми вважаємо, щоμA дорівнюєμB, і об'єднаємо рівняння для двох довірчих інтервалів
¯XA±texpsA√nA=¯XB±texpsB√nB
Розв'язування|¯XA−¯XB| та використання поширення невизначеності, дає
|¯XA−¯XB|=texp×√s2AnA+s2BnB
Нарешті, вирішуємо для t exp
texp=|¯XA−¯XB|√s2AnA+s2BnB
і порівняти його з критичним значеннямt(α,ν), деα ймовірність помилки типу 1, аν це ступені свободи.
Поки що наша розробка цього t -тесту схожа на те, що¯X для порівняння зμ, і все ж ми не маємо достатньої інформації для оцінки t -тесту. Бачите проблему? З двома незалежними наборами даних незрозуміло, скільки ступенів свободи ми маємо.
Припустимо, щоs2As2B розбіжності і дають оцінки однаковіσ2. У цьому випадку ми можемо замінитиs2A іs2B з об'єднаною дисперсієюs2pool, що є кращою оцінкою для дисперсії. Таким чином, наше рівняння дляtexp стає
texp=|¯XA−¯XB|spool×√1nA+1nB=|¯XA−¯XB|spool×√nAnBnA+nB
де s басейн, об'єднане стандартне відхилення,
spool=√(nA−1)s2A+(nB−1)s2BnA+nB−2
Знаменник цього рівняння показує нам, що ступені свободи для об'єднаного стандартного відхилення єnA+nB−2, яке також є ступенями свободи для t -тесту. Зверніть увагу, що ми втрачаємо два ступені свободи, тому що розрахунки дляs2A іs2B вимагають попереднього розрахунку¯XA amd¯XB.
Отже, як ви визначаєте, якщо це нормально, щоб об'єднати дисперсії? Використовуйте F-тест.
Якщоs2A і значноs2B відрізняються, то обчислюємо t exp, використовуючи наступне рівняння. У цьому випадку ми знаходимо ступені свободи, використовуючи наступне нав'язуюче рівняння.
ν=(s2AnA+s2BnB)2(s2AnA)2nA+1+(s2BnB)2nB+1−2
Оскільки ступені свободи повинні бути цілим числом, ми округляємо до найближчого цілого числа значенняν отриманого з цього рівняння.
Рівняння вище для ступенів свободи взято з Міллера, J.C.; Міллер, J.N. статистика аналітичної хімії, 2-е видання, Елліс-Хорвард: Чичестер, Великобританія, 1988. У 6-му виданні автори відзначають, що запропоновано кілька різних рівнянь для числа ступенів свободи для t, коли s A і s B відрізняються, відображаючи той факт, що визначення ступенів свободи і наближення. Альтернативним рівнянням, яке використовується статистичними програмними пакетами, такими як R, Minitab, Excel, є
ν=(s2AnA+s2BnB)2(s2AnA)2nA−1+(s2BnB)2nB−1=(s2AnA+s2BnB)2s4An2A(nA−1)+s4Bn2B(nB−1)
Для типових задач в аналітичній хімії обчислені ступені свободи досить нечутливі до вибору рівняння.
Незалежно від того, як ми обчислюємо t exp, ми відкидаємо нульову гіпотезу, якщо t exp більше,t(α,ν) і зберігаємо нульову гіпотезу, якщо t exp менше або дорівнюєt(α,ν).
Приклад7.2.3 дає результати двох експериментів для визначення маси циркулюючої американської пенні. Визначте, чи є різниця в засобах цих аналізів наα=0.05.
Рішення
Спочатку ми використовуємо F -тест, щоб визначити, чи можемо ми об'єднати відхилення. Ми завершили цей аналіз на прикладі7.2.3, не знайшовши доказів істотної різниці, а це означає, що ми можемо об'єднати стандартні відхилення, отримавши
spool=√(7−1)(0.051)2+(5−1)(0.037)27+5−2=0.0459
з 10 ступенями свободи. Для порівняння засобів використовуємо наступну нульову гіпотезу і альтернативні гіпотези:
H0: μA=μBHA: μA≠μB
Оскільки ми використовуємо об'єднане стандартне відхилення, ми обчислюємо t exp як
texp=|3.117−3.081|0.0459×√7×57+5=1.34
Критичне значення для t (0,05, 10), з додатка 2, дорівнює 2,23. Оскільки t exp менше t (0,05, 10), ми зберігаємо нульову гіпотезу. Бо уα=0.05 нас немає доказів того, що два набори копійок істотно відрізняються.
Одним із методів визначення %w/w Na 2 CO 3 в кальцинованій соді є використання кислотно-основного титрування. Коли два аналітики аналізують один і той же зразок кальцинованої соди, вони отримують результати, показані тут.
Аналітик А:86.82%87.04%86.93%87.01%86.20%87.00%
Аналітик B:81.01%86.15%81.73%83.19%80.27%83.93%
Визначте, чи значна різниця в середніх значеннях приα=0.05.
Рішення
Ми починаємо з звітності про середнє і стандартне відхилення для кожного аналітика.
¯XA=86.83%sA=0.32%
¯XB=82.71%sB=2.16%
Щоб визначити, чи можемо ми використовувати об'єднане стандартне відхилення, ми спочатку завершуємо F-тест, використовуючи наступні нульові та альтернативні гіпотези.
H0: s2A=s2BHA: s2A≠s2B
Розрахувавши F exp, отримаємо значення
Fexp=(2.16)2(0.32)2=45.6
Оскільки F exp більше критичного значення 7.15 для F (0,05, 5, 5) з Додатка 3, ми відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу про те, що існує значна різниця між дисперсіями; таким чином, ми не можемо обчислити об'єднаний стандарт відхилення.
Для порівняння засобів для двох аналітиків ми використовуємо наступні нульові та альтернативні гіпотези.
H0: ¯XA=¯XBHA: ¯XA≠¯XB
Оскільки ми не можемо об'єднати стандартні відхилення, ми обчислюємо t exp як
texp=|86.83−82.71|√(0.32)26+(2.16)26=4.62
і обчислити ступені свободи як
ν=((0.32)26+(2.16)26)2((0.32)26)26+1+((2.16)26)26+1−2=5.3≈5
З Додатка 2 критичне значення для t (0,05, 5) дорівнює 2,57. Оскільки t exp більше, ніж t (0,05, 5), ми відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу про те, що засоби для двох аналітиків значно відрізняютьсяα=0.05.
Парні дані
Припустимо, ми оцінюємо новий метод контролю концентрації глюкози в крові у пацієнтів. Важливою частиною оцінки нового методу є порівняння його з усталеним методом. Який найкращий спосіб зібрати дані для цього дослідження? Оскільки різниця в рівні глюкози в крові серед пацієнтів велика, ми можемо не виявити невелику, але істотну різницю між методами, якщо ми використовуємо різних пацієнтів для збору даних для кожного методу. Використання парних даних, в яких ми аналізуємо кров кожного пацієнта за допомогою обох методів, запобігає значній дисперсії всередині популяції від негативного впливу на t -тест засобів.
Типові рівні глюкози в крові для більшості людей, які не мають діабету, коливається між 80-120 мг/дл (4.4—6.7 мМ), підвищуючись до 140 мг/дл (7,8 мМ) незабаром після їжі. Більш високі рівні є загальними для осіб, які є попередньо діабетичної або діабетичної.
Коли ми використовуємо парні дані, ми спочатку обчислюємо індивідуальні відмінності, d i, між парними реакціями кожного зразка. Використовуючи ці індивідуальні відмінності, ми потім обчислюємо середню різницю¯d, і стандартне відхилення відмінностей, s d. Нульова гіпотеза полягає в томуH0: d=0, що немає різниці між двома зразками та альтернативною гіпотезоюHA: d≠0, полягає в тому, що різниця між двома зразками є значною.
Тестова статистика, t exp, походить від довірчого інтервалу навколо¯d
texp=|¯d|√nsd
де n - кількість парних зразків. Як і для інших форм t -тесту, ми порівнюємо t exp доt(α,ν), де ступені свободиν, є n — 1. Якщо t exp більшеt(α,ν), то відкидаємо нульову гіпотезу і приймаємо альтернативну гіпотезу. Ми зберігаємо нульову гіпотезу, якщо t exp менше або дорівнює t (a, o). Це відоме як парний t-тест.
Marecek et. al. розробили новий електрохімічний метод швидкого визначення концентрації антибіотика моненсін у чанах бродіння [Marecek, V.; Janchenova, H.; Brezina, M; Betti, M. Чим. Акт 1991, 244, 15—19]. Стандартним методом аналізу є тест на мікробіологічну активність, який є одночасно складним для завершення і трудомістким. Зразки збирали з ферментаційних чанів в різний час під час виробництва і аналізували на концентрацію моненсіна обома методами. Результати, у частках на тисячу (ppt), наведені в наступній таблиці.
| Зразок | Мікробіологічні | електрохімічний |
|---|---|---|
| 1 | 129.5 | 132.3 |
| 2 | 89.6 | 91.0 |
| 3 | 76.6 | 73.6 |
| 4 | 52.2 | 58.2 |
| 5 | 110.8 | 104.2 |
| 6 | 50.4 | 49.9 |
| 7 | 72.4 | 82.1 |
| 8 | 141.4 | 154.1 |
| 9 | 75.0 | 73.4 |
| 10 | 34.1 | 38.1 |
| 11 | 60.3 | 60.1 |
Чи є суттєва різниця між методами приα=0.05?
Рішення
Придбання зразків протягом тривалого періоду часу вводить значну залежну від часу зміну концентрації монензину. Оскільки варіація концентрації між зразками настільки велика, ми використовуємо парний t -тест з наступними нульовими та альтернативними гіпотезами.
H0: ¯d=0HA: ¯d≠0
Визначення різниці між методами як
di=(Xelect)i−(Xmicro)i
обчислюємо різницю для кожного зразка.
| зразок | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| di | 2.8 | 1.4 | —3.0 | 6.0 | —6.6 | —0,5 | 9.7 | 12,7 | —1.6 | 4.0 | —0,2 |
Середнє і стандартне відхилення для відмінностей складають відповідно 2,25 ppt і 5.63 ppt. Значення t exp дорівнює
texp=|2.25|√115.63=1.33
що менше критичного значення 2,23 для t (0,05, 10) з додатка 2. Ми зберігаємо нульову гіпотезу і не знаходимо доказів істотної різниці в методах наα=0.05.
Однією з важливих вимог до парного t -тесту є те, що детермінантні та невизначені помилки, які впливають на аналіз, повинні бути незалежними від концентрації аналіта. Якщо це не так, то проба з незвично високою концентрацією аналіту матиме незвично великий d i. Включення цієї вибірки в розрахунок¯d і s d дає упереджену оцінку для очікуваного середнього і стандартного відхилення. Це рідко є проблемою для зразків, які охоплюють обмежений діапазон концентрацій аналітів, таких як у прикладі7.2.4 або вправи7.2.6. Коли парні дані охоплюють широкий діапазон концентрацій, однак, величина детермінантних і невизначений джерел похибки не може бути незалежною від концентрації аналіта; коли це правда, парний t -тест може дати оманливі результати, оскільки парні дані з найбільшим абсолютним домінують визначальні та невизначені помилки¯d. У цій ситуації регресійний аналіз, який є предметом наступної глави, є більш підходящим методом порівняння даних.
Важливість розрізнення парних і непарних даних варто вивчити уважніше. Нижче наведені дані з деякої роботи, яку я завершив з колегою, в якій ми розглядали концентрацію Zn в озері Ері на інтерфейсі повітря-вода та інтерфейс осадок-вода.
| зразок сайту | ppm Zn і інтерфейс повітря-вода | ppm Zn на межі межі осадо-вода |
| 1 | 0,430 | 0,415 |
| 2 | 0,266 | 0,238 |
| 3 | 0,457 | 0,390 |
| 4 | 0.531 | 0,410 |
| 5 | 0,707 | 0.605 |
| 6 | 0,716 | 0,609 |
Середнє значення і стандартне відхилення для ppm Zn на межі розділу повітря-вода становлять 0,5178 ppm і 0,01732 ppm, а середнє і стандартне відхилення для ppm Zn на межі осадок-вода складають 0,4445 ppm і 0,1418 ppm. Ми можемо використовувати ці значення, щоб намалювати нормальні розподіли як для відпускаючи середні та стандартні відхилення для вибірки, так¯X іs, служити оцінками для засобів і стандартних відхилень для популяції,μ іσ. Як ми бачимо на наступному малюнку
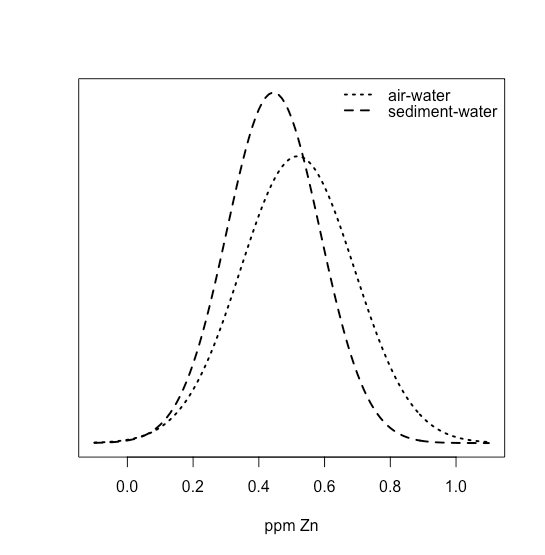
два розподіли сильно перекриваються, припускаючи, що t -тест їх засобів навряд чи знайде докази різниці. І все ж, ми також бачимо, що для кожної ділянки концентрація Zn на межі осаду - вода менше, ніж на межі розділу повітря-вода. При цьому різниця між концентрацією Zn на окремих ділянках досить велика, що маскує нашу здатність бачити різницю між двома інтерфейсами.
Якщо взяти відмінності між інтерфейсами «повітря-вода» і «осад - вода», то маємо значення 0,015, 0,028, 0,067, 0,121, 0,102 і 0,107 проміле Zn, із середнім значенням 0,07333 ppm Zn і стандартним відхиленням 0,04410 ppm Zn. Накладення всіх трьох нормальних розподілів
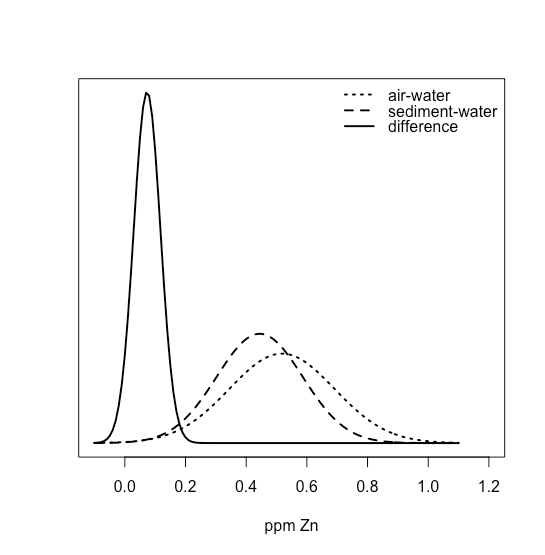
показує чітко, що більша частина нормального розподілу відмінностей лежить вище нуля, припускаючи, що t -тест може показати докази того, що різниця є значною.
Виділення
У розділі 7.1 ми розглянули набір даних, що складається з маси 100 циркулюючих США копійки. Таблиця7.2.1 надає ще один набір даних. Ви помічаєте щось незвичайне в цих даних? З 100 копійок, включених в більш ранню таблицю, жоден пенні не має маси менше 3 м В цій таблиці, однак маса однієї копійки менше 3 м Ми могли б запитати, чи настільки відрізняється ця маса копійки від інших копійок, що вона помилкова.
| 3.067 | 2.514 | 3.094 |
| 3.049 | 3.048 | 3.109 |
| 3.039 | 3.079 | 3.102 |
Вимірювання, яке не відповідає іншим вимірам, називається викидом. Викид може існувати з багатьох причин: викид може належати іншій популяції
Це канадська копійка?
або викид може бути забрудненим або іншим чином зміненим зразком
Копійка пошкоджена або незвично брудна?
або викид може бути наслідком помилки в аналізі
Ми забули тарувати залишок?
Незалежно від його джерела, наявність викидів компрометує будь-який змістовний аналіз наших даних. Є багато значущих тестів, які ми можемо використовувати для виявлення потенційних викидів, три з яких ми представляємо тут.
Q -Тест Діксона
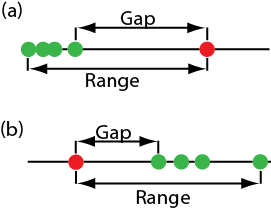
Одним з найпоширеніших тестів значущості для виявлення викидів є Q-тест Діксона. Нульова гіпотеза полягає в тому, що немає викидів, а альтернативна гіпотеза полягає в тому, що існує викид. Q -тест порівнює розрив між підозрюваним викидом і його найближчим числовим сусідом з діапазоном всього набору даних (рис.7.2.2).
Статистика тесту, Q exp, становить
Qexp=gaprange=|outlier's value−nearest value|largest value−smallest value
Це рівняння підходить для оцінки одного викиду. Інші форми Q -тесту Діксона дозволяють його розширення для виявлення декількох викидів [Rorabacher, D.B. анал. Хім. 1991, 63, 139—146].
Значення Q exp порівнюється з критичним значеннямQ(α,n), деα є ймовірність того, що ми відхилимо допустиму точку даних (помилка типу 1) і n - загальна кількість точок даних. Щоб захистити від відхилення дійсної точки даних, зазвичай ми застосовуємо більш консервативний двоххвостий Q-тест, хоча можливий викид є найменшим або найбільшим значенням у наборі даних. Якщо Q exp більшеQ(α,n), то ми відхиляємо нульову гіпотезу і можемо виключити викиди. Ми зберігаємо можливий викид, коли Q exp менше або дорівнюєQ(α,n). Таблиця7.2.2 містить значенняQ(α,n) для набору даних, який має 3—10 значень. Більш велика таблиця знаходиться в додатку 4. Значення дляQ(α,n) припускають базовий нормальний розподіл.
| п | Q (0,05, н) |
|---|---|
| 3 | 0,970 |
| 4 | 0,829 |
| 5 | 0,710 |
| 6 | 0,625 |
| 7 | 0.568 |
| 8 | 0.526 |
| 9 | 0,493 |
| 10 | 0,466 |
Тест Грубба
Хоча Q -тест Діксона є загальним методом оцінки викидів, він більше не підтримується Міжнародною організацією зі стандартизації (ISO), яка рекомендує тест Грубба. Існує кілька версій тесту Грубба в залежності від кількості потенційних викидів. Тут ми розглянемо випадок, коли є єдиний підозрюваний викид.
Детальніше про цю рекомендацію див. Міжнародні стандарти ISO Guide 5752-2 «Точність (правдивість і точність) методів вимірювання та результатів - частина 2: основні методи визначення повторюваності та відтворюваності стандартного методу вимірювання» 1994.
Статистика тесту для тесту Грубба, G exp, - це відстань між середнім значенням зразка та потенційним викидомXout, з точки зору стандартного відхилення зразка, с.¯X
Gexp=|Xout−¯X|s
Порівнюємо значення G exp з критичним значеннямG(α,n), деα є ймовірність того, що ми відхилимо дійсну точку даних, а n - кількість точок даних у вибірці. Якщо G exp більшеG(α,n), то ми можемо відхилити точку даних як викид, інакше ми збережемо точку даних як частину вибірки. Таблиця7.2.3 містить значення G (0,05, n) для зразка, що містить 3—10 значень. Більш велика таблиця знаходиться в Додатку 5. Значення дляG(α,n) припускають базовий нормальний розподіл.
| п | Г (0,05, н) |
|---|---|
| 3 | 1,115 |
| 4 | 1.481 |
| 5 | 1.715 |
| 6 | 1.887 |
| 7 | 2.020 |
| 8 | 2.126 |
| 9 | 2.215 |
| 10 | 2.290 |
Критерій Шовене
Наш остаточний метод виявлення викиду - критерій Шовене. На відміну від Q -Test Діксона та тесту Грубба, ви можете застосувати цей метод до будь-якого розподілу, якщо ви знаєте, як обчислити ймовірність для конкретного результату. Критерій Шовене стверджує, що ми можемо відхилити точку даних, якщо ймовірність отримання значення точки даних менше(2n−1), де n - розмір вибірки. Наприклад, якщо n = 10, результат з ймовірністю менше(2×10)−1, або 0,05, вважається викидом.
Для обчислення ймовірності потенційного викиду спочатку обчислимо його стандартизоване відхилення, z
z=|Xout−¯X|s
деXout потенційний викид,¯X - середнє значення зразка, а s - стандартне відхилення зразка. Зауважте, що це рівняння ідентично рівнянню для G exp у тесті Грубба. Для нормального розподілу можна знайти ймовірність отримання значення z за допомогою таблиці ймовірностей в Додатку 1.
Таблиця7.2.1 містить маси за дев'ять циркулюючих США копійки. Один запис, 2,514 г, здається, є викидом. Визначте, чи є цей пенні викидом, використовуючи Q -тест, тест Грубба та критерій Шовене. Для Q -тесту та тесту Grubb давайтеα=0.05.
Рішення
Для Q -тесту значення дляQexp дорівнює
Qexp=|2.514−3.039|3.109−2.514=0.882
З таблиці7.2.2 критичне значення для Q (0,05, 9) дорівнює 0,493. Оскільки Q exp більше Q (0,05, 9), ми можемо припустити, що копійка з масою 2,514 г, ймовірно, є викидом.
Для тесту Грубба спочатку потрібні середнє значення і стандартне відхилення, які складають 3,011 г і 0,188 г відповідно. Значення для G exp дорівнює
Gexp=|2.514−3.011|0.188=2.64
Використовуючи Таблицю7.2.3, знаходимо, що критичне значення для G (0,05, 9) дорівнює 2,215. Оскільки G exp більше G (0,05, 9), можна припустити, що копійка з масою 2,514 г, ймовірно, є викидом.
Для критерію Шовене критична ймовірність дорівнює(2×9)−1, або 0,0556. Значення z таке ж, як G exp, або 2,64. Використовуючи додаток 1, ймовірність для z = 2.64 дорівнює 0,00415. Оскільки ймовірність отримання маси 0,2514 г менше критичної ймовірності, можна припустити, що копійка з масою 2,514 г, швидше за все, є викидом.
Ви повинні проявляти обережність при використанні тесту на значущість для викидів, оскільки є ймовірність, що ви відхилите дійсний результат. Крім того, слід уникати відхилення викиду, якщо це призводить до точності, яка набагато краща, ніж очікувалося, на основі поширення невизначеності. Враховуючи ці побоювання, не дивно, що деякі статистики застерігають проти видалення викидів [Демінг, У.Е. Статистичний аналіз даних; Wiley: Нью-Йорк, 1943 (перевидано Dover: Нью-Йорк, 1961); стор. 171].
Ви також можете прийняти більш сувору вимогу щодо відхилення даних. Наприклад, при використанні тесту Грубба, настанови ISO 5752 пропонують зберегти значення, якщо ймовірність відхилення його більшеα=0.05, ніж, і позначити значення як «відсторонювач», якщо ймовірність відхилення від нього знаходиться міжα=0.05 іα=0.01. «Відхилення» зберігається, якщо немає вагомих причин для його відхилення. Керівні принципи рекомендують використовуватиα=0.01 як мінімальний критерій для відхилення можливого викиду.
З іншого боку, тестування на викиди може надати корисну інформацію, якщо ми спробуємо зрозуміти джерело підозрюваного викиду. Наприклад, викид в таблиці7.2.1 являє собою значну зміну маси копійки (приблизно на 17% зменшення маси), що є результатом зміни складу американського пенні. У 1982 році склад американського пенні змінився з латунного сплаву, який становив 95% w/w Cu і 5% w/w Zn (з номінальною масою 3,1 г), до чистого цинкового сердечника, покритого міддю (номінальною масою 2,5 г) [Richardson, T.H. J. chem. Едук. 1991, 68, 310—311]. Копійки в таблиці7.2.1, таким чином, були залучені з різних популяцій.