18.4: Пояснення атрибутів мережевих акторів
- Page ID
- 67429
У попередньому розділі ми розглянули методи тестування відмінностей і асоціації між цілими мережами. Тобто вивчення макрошаблонів того, як позиція актора в одній мережі може бути пов'язана з їх положенням в іншій.
Нас часто цікавлять і мікропитання. Наприклад: чи впливає стать актора на їх центральність між собою? Це питання пов'язує атрибут (стать) до міри положення актора в мережі (між центральністю). Нас може зацікавити взаємозв'язок між двома (або більше) аспектами позицій актора. Наприклад: наскільки різниця в акторській центральності між сутністю може бути пояснена їх ступенем і кількістю клік, до яких вони належать? Нас може навіть зацікавити взаємозв'язок між двома окремими атрибутами серед набору акторів, які пов'язані в мережі. Наприклад, у шкільному класі чи існує зв'язок між статтю актора та їх академічними досягненнями?
У всіх цих випадках ми зосереджуємося на змінних, які описують окремі вузли. Ці змінні можуть бути або нереляційними атрибутами (наприклад, стать), або змінними, які описують певний аспект реляційної позиції індивіда (наприклад, між ними). У більшості випадків для опису відмінностей і асоціацій можуть застосовуватися стандартні статистичні інструменти аналізу змінних.
Але стандартні статистичні інструменти для аналізу змінних не можуть бути застосовані до інференціальних питань — гіпотез або значущості тестів, тому що індивіди ми досліджують не є незалежними спостереженнями, проведеними навмання з деякої великої популяції. Замість застосування нормальних формул (тобто тих, які вбудовані в пакети статистичних програм і обговорюються в більшості основних текстів статистики), нам потрібно використовувати інші методи, щоб отримати більш правильні оцінки достовірності та стабільності оцінок (тобто стандартних помилок). У деяких випадках може бути застосований підхід «boot-strapping» (оцінка варіації оцінок цікавить параметра від великої кількості випадкових підзразків акторів); в інших випадках ідея випадкової перестановки може бути застосована для генерації правильних стандартних помилок.
Гіпотези про засоби двох груп
Припустимо, у нас було уявлення про те, що приватні комерційні організації мають меншу ймовірність активної участі в обміні інформацією з іншими особами у своїй галузі, ніж були. державні організації. Ми хотіли б перевірити цю гіпотезу, порівнявши середній рівень урядових та неурядових суб'єктів в одній організаційній сфері.
Використовуючи мережу обміну інформацією Knoke, ми запустили Мережа> Централість> Ступінь , і зберегли результати у вихідному файлі «FreemanDegree» як набір даних UCINET. Ми також використовували Дані > Електронні таблиці>Матриця створити файл атрибутів UCINET «кнокеговт», який має один стовпець фіктивного коду (1 = урядова організація, 0 = неурядова організація).
Давайте проведемо простий t-тест з двома вибірками, щоб визначити, чи середня ступінь центральності державних організацій нижча за середню ступінь центральності не- державні організації. На малюнку 18.10 показано діалогове вікно «Інструменти» > «Тестування гіпотез» > «Рівень вузла» > «Т-тест» щоб налаштувати цей тест.
Малюнок 18.10: Діалогове вікно для інструментів> Тестування гіпотез > Рівень вузла> T-тест
Оскільки ми працюємо з окремими вузлами в якості спостережень, дані розташовуються в стовпці (або, іноді, рядку) одного або декількох файлів. Зауважте, як у діалоговому вікні вводяться назви файлів (вибрані за допомогою перегляду або набрані) та стовпці у файлі. Нормована міра центральності ступеня Фрімена знаходиться у другому стовпці його файлу; у файлі, який ми створили для кодування урядов/неурядових організацій, є лише один вектор (стовпець).
Для цього тесту ми вибрали за замовчуванням 10 000 випробувань, щоб створити розподіл вибірки на основі перестановки різниці між двома засобами. Для кожного з цих випробувань бали за нормованою централізацією ступеня Фрімена випадковим чином переставляються (тобто випадковим чином призначаються уряду чи неурядові, пропорційні кількості кожного типу.) Стандартне відхилення цього розподілу на основі випадкових випробувань стає оцінюваною стандартною похибкою для нашого тесту. На малюнку 18.11 показані результати.
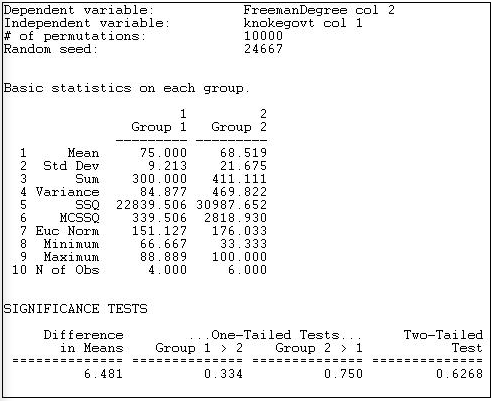
Малюнок 18.11: Тест на різницю середньої нормованої ступеня центральності урядових та неурядових організацій Кноке
Перший вивід повідомляє основну описову статистику для кожної групи. Номери груп присвоюються відповідно до порядку справ у файлі, що містить незалежну змінну. У нашому прикладі першим вузлом був COUN, державна організація; так, уряд став «Групою 1», а неурядовий став «Групою 2».
Ми бачимо, що середня нормована ступінь центральності державних організацій (75) на 6,481 одиниць перевищує середню нормовану ступінь центральності неурядових організації (68.519). Це, здавалося б, підтверджує нашу гіпотезу; але тести статистичної значущості закликають до значної обережності. Відмінності, такі великі, як 6.481 на користь державних організацій, трапляються 33,4% часу у випадкових випробуваннях - тому ми будемо приймати неприйнятний ризик помилитися, якщо ми прийшли до висновку, що дані відповідають нашій дослідницькій гіпотезі.
UCINET не виводить оцінену стандартну похибку або значення звичайного двогрупового t-тесту.
Гіпотези про засоби множинних груп
Підхід до оцінки різниці між засобами двох груп, розглянутий у попередньому розділі, може бути розширений на кілька груп з одностороннім аналізом дисперсія (ANOVA). Процедура Інструменти>Тестування гіпотези>Рівень вузла>ANOVA забезпечує регулярний підхід OLS до оцінки відмінностей у групових засобах. Оскільки наші спостереження не є незалежними, застосовується і процедура оцінки стандартних помилок випадковими реплікаціями.
Припустимо, ми розділили 23 великих донорів політичних кампаній Каліфорнії на три групи та закодували вектор одного стовпця у файлі атрибутів UCINET. Ми закодували кожного донора як потрапляння в одну з трьох груп: «інші», «капіталісти» або «робітники».
Якщо ми вивчимо мережу зв'язків між донорами (визначається спільною участю в одних і тих же кампаніях), ми очікуємо, що групи працівників будуть відображатися вище центральність власного вектора, ніж донори в інших групах. Тобто ми передбачаємо, що «ліві» групи інтересів виявлять значну взаємозв'язок, і - в середньому - мають членів, які більше пов'язані з високопов'язаними іншими, ніж це стосується капіталістичних та інших груп. Ми обчислили центральність власного вектора за допомогою Мережа> Централість> Власний вектор , і збережені результати в іншому файлі атрибутів UCINET.
Діалогове вікно для Інструменти>Тестування гіпотез >Рівень вузла>ANOVA виглядає дуже схоже на Інструменти>Тестування гіпотез > Рівень вузла> T-тест , тому ми не будемо відображати його. Результати нашого аналізу наведені на малюнку 18.12.
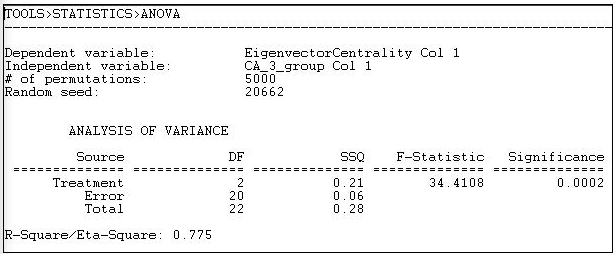
Малюнок 18.12: Одностороння ANOVA власної векторної центральності політичних донорів Каліфорнії, зі стандартними помилками на основі перестановки та тести
Середня центральність власного вектора восьми «інших» донорів становить 0,125. Для семи «капіталістів» він дорівнює 0,106, а для семи «робочих» груп - 0,323 (розрахований в іншому місці). Відмінності між цими засобами вельми істотні (F = 34,4 з 2 д.ф. і р = 0,0002). Відмінності в групових засобах становлять 78% загальної дисперсії в балах центральності власних векторів серед донорів.
Регресування позиції щодо атрибутів
Де атрибут акторів, які ми зацікавлені в поясненні або прогнозуванні, вимірюється на рівні інтервалу, і один або кілька наших провісників також знаходяться на інтервальний рівень, множинна лінійна регресія є загальним підходом. Інструменти>Тестування гіпотези>Рівень вузла>Регресія обчислить базову статистику лінійної множинної регресії за допомогою OLS та оцінюватиме стандартні помилки та значущість, використовуючи метод випадкових перестановок для побудови розподіли вибірки R-квадратів і коефіцієнтів нахилу.
Давайте продовжимо приклад в попередньому розділі. Нашим залежним атрибутом, як і раніше, є власновекторна центральність окремих політичних донорів. Цього разу ми будемо використовувати три незалежні вектори, які ми побудували за допомогою Data>Електронні таблиці> Матриця , як показано на малюнку 18.13.
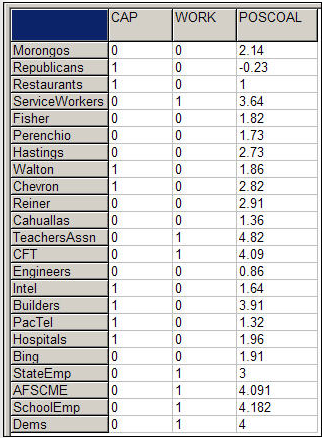
Малюнок 18.13: Побудова незалежних векторів для множинної лінійної регресії
Були побудовані дві фіктивні змінні, щоб вказати, чи є кожен донор членом групи «капіталіст» або «працівник». Опущена категорія («інше») буде служити категорією перехоплення/посилання. POSCOAL - це середня кількість разів, коли кожен донор бере участь на одній стороні проблем з іншими донорами (негативний бал свідчить про протидію іншим донорам).
По суті, ми намагаємося з'ясувати, чи є у «робітників» вища центральність власного вектора (спостерігається в розділі вище) просто функцією більш високих показників участь у коаліціях, або чи мають працівники краще зв'язаних союзників — незалежно від високої участі.
На малюнку 18.14 показано діалогове вікно для визначення залежного та декількох незалежних векторів.
Малюнок 18.14: Діалогове вікно для інструментів> Тестування гіпотез > Рівень вузла> Регресія
Зверніть увагу, що всі незалежні змінні потрібно вводити в єдиний набір даних (з декількома стовпцями). Усі основні статистичні дані регресії можуть бути збережені як вихідні дані, для використання в графіці або подальшого аналізу. На малюнку 18.15 показаний результат оцінки множинної регресії.
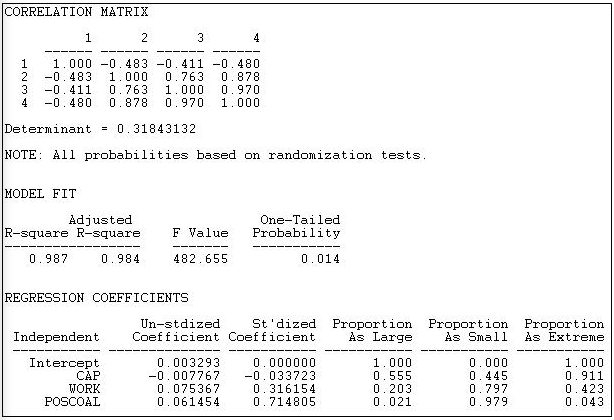
Малюнок 18.15: Множинна регресія центральності власного вектора з тестами значущості на основі перестановки
Кореляційна матриця показує дуже високу колінеарність між перебуванням у групі робітників (змінна 3) та участю в коаліціях (змінна 4). Це говорить про те, що може бути важко відокремити наслідки простої участі від наслідків групи інтересів працівників.
R-квадрат дуже високий для цієї простої моделі (.987) і дуже значний за допомогою тестів перестановки (p = 0.014).
Контролюючи загальну участь коаліції, капіталістичні інтереси, ймовірно, матимуть дещо нижчу центральність власного вектора, ніж інші (-0,0078), але це не так значні (р = 0,555). Робочі групи, здається, мають вищу центральність власного вектора, навіть контролюючи загальну участь коаліції (0,075), але ця тенденція може бути випадковим результатом (однохвосте значення становить лише p = 0,102). Чим вище рівень участі в коаліціях (POSCOAL), тим більша центральність власного вектора акторів (0,0615, р = 0,021), незалежно від того, який вид інтересу представляється.
Як і раніше, коефіцієнти генеруються стандартними методами лінійного моделювання OLS і засновані на порівнянні балів за незалежними і залежними атрибутами окремі дійові особи. Тут відрізняється визнання того, що актори не є незалежними, тому необхідна оцінка стандартних помилок шляхом моделювання, а не за стандартною формулою.
Підходи t-тесту, ANOVA та регресії, розглянуті в цьому розділі, розраховуються на рівні мікро- або індивідуального актора. Заходи, які аналізуються як незалежні та залежні, можуть бути як реляційними, так і нереляційними. Тобто, ми могли б бути зацікавлені в прогнозуванні та тестуванні гіпотез про нереляційні атрибути акторів (наприклад, їх дохід) за допомогою поєднання реляційних (наприклад, центральності) та нереляційних (наприклад, гендерних) ознак. Ми могли б бути зацікавлені в прогнозуванні реляційного атрибута акторів (наприклад, центральності) за допомогою поєднання реляційних та нереляційних незалежних змінних.
Приклади ілюструють, як реляційні та нереляційні атрибути акторів можуть бути проаналізовані за допомогою загальних статистичних методів. Однак головне, що слід пам'ятати, полягає в тому, що спостереження не є незалежними (оскільки всі актори є членами однієї мережі). Через це потрібна пряма оцінка розподілів вибірки та результуючої статистики — стандартне, базове статистичне програмне забезпечення не дасть правильних відповідей.