18.5: Пояснення відносин між акторами мережі
- Page ID
- 67438
У попередньому розділі ми розглянули деякі інструменти для гіпотез про окремих суб'єктів, вбудованих в мережі. Такі моделі дуже корисні для вивчення відносин між реляційними та нереляційними атрибутами індивідів.
Одним з найбільш відмінних способів застосування статистичного аналізу до даних соціальних мереж є зосередження уваги на прогнозуванні відносин акторів, а не їх атрибути. Замість того, щоб будувати статистичну модель для прогнозування ступеня кожного актора, ми могли б, замість цього, передбачити, чи є зв'язок від кожного актора один до одного актора. Замість того, щоб пояснювати дисперсію в окремих осіб, ми могли б зосередитись на поясненні варіації відносин.
У цьому заключному розділі ми розглянемо кілька статистичних моделей, які прагнуть передбачити наявність або відсутність (або силу) зв'язку між двома акторами. Такі моделі зосереджуються безпосередньо на дуже соціологічному питанні: які фактори впливають на ймовірність того, що дві людини матимуть стосунки?
Один очевидний, але дуже важливий, провісник того, чи можуть бути пов'язані два актори, - це їх схожість або близькість. У багатьох соціологічних теоріях передбачається, що два актори, які поділяють певний атрибут, частіше формуватимуть соціальні зв'язки, ніж два актори, які цього не роблять. Ця гіпотеза «гомофілії» лежить в основі багатьох теорій диференціації, солідарності та конфлікту. Два актори, які ближче до одного в мережі, часто гіпотезують, що частіше утворюють зв'язки; два актори, які поділяють атрибути, швидше за все, перебувають на ближчій відстані один до одного в мережах.
Деякі з наведених нижче моделей досліджують гомофілію та близькість, щоб передбачити, чи мають актори зв'язки або близькі один до одного. Остання модель, яку ми розглянемо на моделі «Р1», також прагне пояснити відносини. Модель P1 намагається передбачити, чи не існує ніякого відношення, асиметричного відношення чи взаємної зв'язки між парами акторів. Однак замість того, щоб використовувати атрибути або близькість як предиктори, модель P1 фокусується на основних мережевих властивостях кожного актора та мережі в цілому (ступінь, поза ступенем, глобальна взаємність). Цей тип моделі — модель ймовірності наявності/відсутності кожного можливого співвідношення на графіку як функції мережевих структур — є одним з основних безперервних напрямків розвитку методів соціальних мереж.
Гіпотези про відносини всередині та між групами
Одним з найбільш поширених соціологічних спостережень є те, що «птахи пір'я злітаються разом». Поняття про те, що подібність (або гомофілія) збільшує ймовірність формування соціальних зв'язків, є центральним для більшості соціологічних теорій. Гіпотезу гомофілії можна прочитати, щоб зробити прогноз про соціальні мережі. Це говорить про те, що якщо два актори певним чином схожі, то більш імовірно, що між ними будуть мережеві зв'язки. Якщо ми подивимось на соціальну мережу, яка містить два типи акторів, щільність зв'язків повинна бути більшою всередині кожної групи, ніж між групами.
Інструменти>Тестувальні гіпотези>Змішані діадичні/вузлові>Категоричні атрибу>Спільний підрахунок Надає тест, що щільність зв'язків всередині і між двома групами відрізняється від того, що ми очікували б, якби зв'язки розподілялися випадковим чином по всіх парах вузлів.
Процедура приймає двійковий граф і розділ (тобто вектор, який класифікує кожен вузол як знаходиться в тій чи іншій групі), і переставляє та блокує дані. Якщо не було зв'язку між спільним атрибутом (тобто перебуванням в одному блоці) і ймовірністю зв'язки між двома акторами, ми можемо передбачити кількість зв'язків, які повинні бути присутніми в кожному з чотирьох блоків графіка (тобто: група 1 за групою 1; група 1 за групою 2; група 2 за групою 1; і група 2 по групі 2). Ці чотири «очікувані частоти» потім можна порівняти з чотирма «спостережуваними частотами». Логіка точно така ж, як і тест незалежності Пірсона Чі-квадрат - ми можемо генерувати «тестову статистику», яка показує, наскільки далеко таблиця 2 на 2 відходить від «незалежності» або «відсутності асоціації».
Однак для перевірки інференційної значущості відхилень від випадковості ми не можемо покладатися на стандартні статистичні таблиці. Замість цього обчислюється велика кількість випадкових графів з однаковою загальною щільністю і однаковими розмірами розділів. Розподіл вибірки відмінностей між спостережуваними та очікуваними для випадкових графів може бути обчислений і використаний для оцінки ймовірності того, що наш спостережуваний графік може бути результатом випадкового випробування з популяції, де не було зв'язку між членством в групі та ймовірністю зв'язку.
Щоб проілюструвати, якщо два великих політичних донори внесли свій внесок на одну сторону політичних кампаній (у 48 ініціативних кампаніях), ми кодуємо їх «1» як мають краватку або відношення, в іншому випадку ми їх кодуємо нуль. Ми розділили наших великих політичних донорів у Каліфорнійських ініціативних кампаніях на дві групи - ті, які пов'язані з «робітниками» (наприклад, профспілки, Демократична партія), і ті, які не є.
Ми передбачаємо, що дві групи, які представляють інтереси працівників, будуть частіше розділяти зв'язок перебування в коаліціях для підтримки ініціатив, ніж дві. групи, намальовані навмання. На малюнку 18.16 показані результати Інструменти>Тестування гіпотез >Змішані діадичні/Вузлові атриби> Категоріальні атрибу> Спільна кількість застосовується до цієї проблеми.

Малюнок 18.16: Випробування на двогрупові відмінності щільності стяжки
Вектор розділення (змінна групової ідентифікації) спочатку кодувався як нуль для донорів, що не працюють, і один для донорів працівників. Вони були повторно позначені на виході як один і два. Ми використовували типове значення 10 000 випадкових графів, щоб генерувати розподіл вибірки для групових відмінностей.
Перший рядок, позначений «1-1", говорить нам, що під нульовою гіпотезою, що зв'язки випадковим чином розподіляються між усіма акторами (тобто група не має різниці), ми б очікувати, що зв'язки 30.356 будуть присутні в непрацівникові до непрацівника блоку. Ми насправді спостерігаємо 18 зв'язків у цьому блоці, 12 менше, ніж можна було б очікувати. Негативна різниця ця велика відбулася лише в 2,8% часу на графіках, де зв'язки були розподілені випадковим чином. Зрозуміло, що у нас є відхилення від випадковості всередині блоку «неробочий». Але різниця не підтримує гомофілію - це говорить про протилежне; зв'язки між суб'єктами, які поділяють атрибут непредставлення працівників, менш імовірні, ніж випадкові, а не більш імовірні.
Другий рядок, позначений «1-2", не показує суттєвої різниці між кількістю зв'язків, що спостерігаються між робочими та неробітничими групами, та тим, що станеться випадково за нульовою гіпотезою про відсутність впливу спільної членства в групі на щільність зв'язків.
Третій ряд, позначений «2-2" Різниця ця велика вказує на те, що спостережуваний підрахунок зв'язків серед груп інтересів, що представляють працівників (21) набагато більше, ніж очікуваний випадково (5.3) майже ніколи не буде спостерігатися, якби нульова гіпотеза відсутності групового впливу на ймовірність зв'язків була правдою.
Можливо, наш результат не підтримує теорію гомофілії, оскільки група «неробітник» насправді не є соціальною групою взагалі - лише залишкова сукупність різноманітних інтереси. Використання інструментів>Тестування гіпотез > Змішана діадична/вузлова>Категоріальні атрибу>Таблиця непередбачених ситуацій Аналізуючи, ми можемо розширити кількість груп, щоб забезпечити кращий тест. Цього разу давайте класифікуємо політичних донорів як «інших», «капіталістів» або «робітників». Результати цього тесту наведені на малюнку 18.17.

Малюнок 18.17: Випробування на тригрупові відмінності щільності стяжки
Група «Інша» була перемаркована «1», група «капіталістична» перемаркована «2», а група «працівник» перемаркована «3». На графіку є 87 загальних зв'язків, із показаними спостережуваними частотами («Перехресні класифіковані частоти).
Ми бачимо, що спостережувані частоти відрізняються від «Очікуваних значень за моделлю незалежності». Величини над і недопредставленість показані як «Спостерігається/Очікується». Зауважимо, що всі три діагональні клітинки (тобто зв'язки всередині груп) тепер відображаються гомофілічно - більше, ніж випадкова щільність.
Обчислено чі-квадратну статистику Пірсона (74.217). І ми показуємо середні підрахунки краватки в кожній клітинці, яка відбулася в 10000 випадкових випробувань. Нарешті, ми спостерігаємо, що p < 0.0002. Тобто відхилення зв'язків від випадковості настільки велике, що траплялося б це лише дуже рідко, якби модель без асоціації була правдою.
Моделі гомофілії
Результат у розділі вище, здається, підтримує гомофілію (яку ми можемо побачити, дивлячись на те, де відбуваються відхилення від незалежності. Статистичний тест, однак, є лише глобальним випробуванням відмінності від випадкового розподілу. Рутинні інструменти>Тестування гіпотези>Змішані діадичні/вузлові>Категоріальні атрибу>Моделі щільності ANOVA надає специфічні тести деяких досить специфічних моделей гомофілії.
Найменш специфічне поняття про те, як члени груп ставляться до членів інших груп, просто полягає в тому, що групи відрізняються. Члени однієї групи можуть віддавати перевагу зв'язкам лише в межах своєї групи; члени іншої групи можуть віддавати перевагу зв'язкам лише за межами своєї групи.
Варіант структурної моделі блоку Інструменти>Тестувальні гіпотези>Змішані діадичні/Вузлові атриби>Категоріальні атрибу>Моделі щільності Anova надає тест, що закономірності всередині та між груповими зв'язками відрізняються між групами, але не визначає, яким чином вони можуть відрізнятися. На малюнку 18.18 показані результати пристосування цієї моделі до даних про міцні коаліційні зв'язки (обмін 4 або більше кампаніями) між «іншими», «капіталістичними» та «робітничими» групами інтересів.
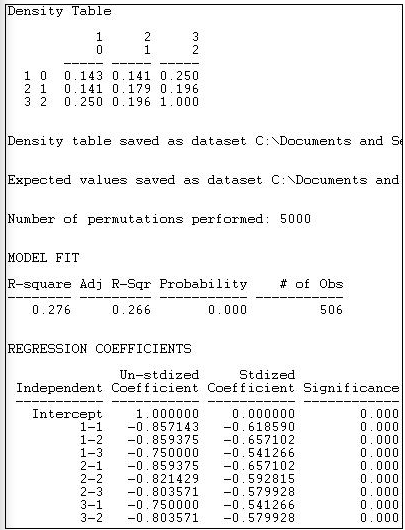
Малюнок 18.18: Структурна блокова модель відмінностей групової щільності стяжки
Спочатку показана спостережувана таблиця щільності. Члени «іншої» групи мають низьку ймовірність бути прив'язаними один до одного (0,143) або до «капіталістів» (0,143), але дещо міцніші зв'язки з «робітниками» (0,250). Тільки «робітники» (категорія 2, ряд 3) демонструють сильні тенденції до усередині групи зв'язків.
Далі до даних підлаштовується регресійна модель. Наявність або відсутність зв'язки між кожною парою акторів регресується на набір фіктивних змінних, які представляють кожну з осередків таблиці блоків 3 на 3. У цій регресії останній блок (тобто 3-3) використовується як еталонна категорія. У нашому прикладі відмінності між блоками пояснюють 27,6% дисперсії в парній наявності або відсутності зв'язків. Імовірність краватки між двома дійовими особами, обидва з яких знаходяться в блоці «робочі» (блок 3), становить 1.000. Імовірність в блоці, що описує зв'язки між «іншими» і «іншими» акторами (блок 1-1), на 857 менше цієї.
Статистичну значимість цієї моделі неможливо правильно оцінити за допомогою стандартних формул для незалежних спостережень. Натомість було проведено 5000 випробувань з випадковими перестановками наявності та відсутності зв'язків між парами акторів та оцінено стандартні помилки, розраховані на основі отриманого модельованого розподілу вибірки.
Набагато більш обмежене поняття групових відмінностей названо моделлю постійної гомофілії в Інструменти>Тестувальні гіпотези>Змішані діадичні/Вузлові атриби>Категоріальні атрибу>Моделі щільності Anova . Ця модель передбачає, що всі групи можуть мати перевагу усередині групи зв'язків, але сила переваги однакова у всіх групах. Результати підгонки даної моделі до даних наведені на малюнку 18.19.
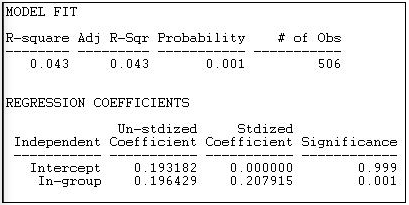
Малюнок 18.19: Постійна гомофілічна блокова модель відмінностей у груповій щільності зв'язків
Враховуючи те, що ми спостерігали, дивлячись безпосередньо на щільності блоків (показано на малюнку 18.18), не дивно, що модель постійної гомофілії не відповідає цим даним колодязь. Ми знаємо, що дві групи («інші» та «капіталісти») не мають явної тенденції до гомофілії - і це сильно відрізняється від групи «робітників». На блокову модель групових відмінностей припадає лише 4,3% дисперсії в парних зв'язках; однак випробування перестановки припускають, що це не випадковий результат (p = 0,001).
Ця модель має лише два параметри, оскільки гіпотеза пропонує просту різницю між діагональними клітинами (всередині групи зв'язків 1-1, 2-2 та 3-3) та всіма інші клітини. Гіпотеза полягає в тому, що щільності всередині цих двох перегородок однакові. Ми бачимо, що розрахункова середня щільність зв'язків пар, які не входять до однієї групи, становить 0.193 - існує 19,3% ймовірність того, що гетерогенні діади матимуть краватку. Якщо члени діади з однієї групи, ймовірність того, що вони поділяють нічию, на 0,196 більше, або 0,389.
Отже, хоча модель постійної гомофілії взагалі не прогнозує зв'язки індивіда, є помітний загальний ефект гомофілії.
Ми зазначили, що сильна тенденція до міжгрупових зв'язків описує лише групу «робітників». Третя блокова модель, позначена «Змінна гомофілія» інструментами> Тестування гіпотез > Змішана діадична/ Nodal>Категоріальні атрибу>Моделі щільності Anova перевіряє модель, яка кожна діагональ осередки (тобто зв'язки всередині групи 1, всередині групи 2 і всередині групи 3) відрізняються від усіх зв'язків, які не знаходяться всередині групи. На малюнку 18.20 відображаються результати.
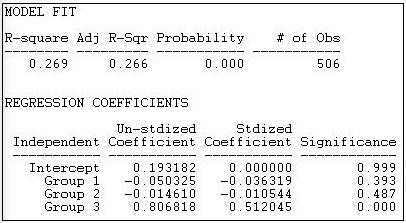
Малюнок 18.20: Змінна гомофілічна блокова модель відмінностей у груповій щільності зв'язків
Ця модель підходить для даних набагато краще (R-квадрат = 0,269, з p < 0,000), ніж модель постійної гомофілії. Він також підходить до даних майже так само, як і необмежена структурна блокова модель (рис. 18.18), але є простішою.
Тут перехоплення - це ймовірність того, що між будь-якими двома членами різних груп добре існує діадична зв'язок (0.193). Ми бачимо, що ймовірність усередині групових зв'язків між групою 1 («інші») насправді на 0,05 менше цієї (але не суттєво відрізняється). У межах групових зв'язків серед капіталістичних груп інтересів (група 2) зустрічаються дуже трохи рідше (-0,01), ніж гетерогенні групові зв'язки (знову ж таки, не значущі). Однак зв'язки між групами інтересів, що представляють працівників (група 3), значно більш поширені (0,81), ніж зв'язки всередині неоднорідних пар.
У нашому прикладі ми відзначили, що одна група, здається, відображає внутрішньогрупові зв'язки, а інші - ні. Один із способів думати про цю закономірність - блокова модель «ядро-периферія». Існує і сильна форма, і більш розслаблена форма серцево-периферійної структури.
Модель ядро-периферія 1 передбачає, що існує високоорганізоване ядро (багато зв'язків всередині групи), але інших зв'язків мало - або серед члени периферії, або між членами ядра і членами периферії. На малюнку 18.21 показані результати пристосування цієї блокової моделі до даних донорів Каліфорнії.
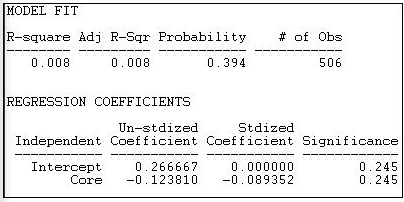
Малюнок 18.21: «Сильна» основно-периферійна блокова модель каліфорнійських політичних донорів
Зрозуміло, що ця модель не справляється з описом закономірності всередині і між груповими зв'язками. R-квадрат дуже низький (0,008), і результати цього невеликого будуть відбуватися 39.4% часу в випробуваннях з випадково переставлених даних. (Незначні) коефіцієнти регресії показують щільність (або ймовірність зв'язку між двома випадковими акторами) на периферії як 0,27, а щільність в «Ядрі» на 0,12 менше цієї. Оскільки «ядро» - це, за визначенням, максимально щільна область, то виявляється, що вихід у версії 6.8.5 може бути неправильно позначений.
Core-Periphery 2 пропонує більш розслаблену блокову модель, в якій ядро залишається щільно пов'язаним всередині себе, але дозволено мати зв'язки з периферією. Периферія - це, в максимально можливій мірі, сукупність випадків без зв'язків у своїй групі. На малюнку 18.22 показані результати цієї моделі для політичних донорів Каліфорнії.
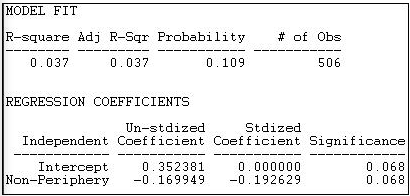
Малюнок 18.22: «Розслаблена» основно-периферійна блокова модель каліфорнійських політичних донорів
Підгонка цієї моделі краще (R-квадрат = 0,037), але все одно дуже бідна. Результати цього сильного відбуватимуться приблизно 11% часу у випробуваннях з випадково переставлених даних. Щільність перехоплення (яку ми інтерпретуємо як «непериферію») вище (присутні близько 35% всіх зв'язків), а ймовірність зв'язки між двома випадками на периферії - 0,17 нижче.
Гіпотези про подібність і відстань
Гіпотеза гомофілії часто розглядається категорично: чи існує тенденція до акторів, які мають один і той же «тип», бути сусідніми (або близькими) один до одного в в мережі?
Ця ідея, однак, може бути узагальнена до безперервних атрибутів: чи існує тенденція до акторів, які мають більше схожих атрибутів, розташовуватися ближче один до одного в Мережа?
УСІНЕТ Інструменти>Тестування гіпотез>Змішана діадична? Nodal>Безперервні атрибут>Статистика Moran/Geary забезпечує два заходи, які вирішують питання про» автокореляція» між акторськими балами за інтервальними показниками їх атрибутів та мережевою відстанню між ними. Два заходи (Moran's I і Geary's C) адаптовані для аналізу соціальних мереж від їх походження в географії, де вони були розроблені для вимірювання ступеня, в якій подібність географічних особливостей будь-яких двох місць була пов'язана з просторовою відстанню між ними.
Припустимо, що нас цікавило, чи існувала тенденція до того, що групи політичних інтересів, які були «близькі» один до одного, витрачати подібні суми грошей. Ми можемо припустити, що групи інтересів, які є частими союзниками, також можуть впливати один на одного з точки зору рівня ресурсів, які вони вносять - що серед частих союзників виникає свого роду норма очікуваного рівня внеску.
Використовуючи інформацію про внески дуже великих донорів (які дали понад $5,000,000) щонайменше на чотири (з 48) виборчих ініціатив в Каліфорнії, ми можемо проілюструвати ідею мережевої автокореляції.
Спочатку ми створюємо файл атрибутів, який містить стовпець, який має оцінку атрибутів кожного вузла, в даному випадку сума загальних витрат донорами.
По-друге, ми створюємо матричний набір даних, який описує «близькість» кожної пари акторів. Тут є кілька альтернативних підходів. Один з них полягає у використанні матриці суміжності (двійкової). Ми проілюструємо це, кодуючи двох донорів як суміжних, якщо вони внесли кошти на ту саму сторону принаймні чотирьох кампаній (тут ми побудували суміжність на основі даних про «приналежність»; часто ми маємо прямий показник суміжності, наприклад, один донор називає іншого союзником). Ми також могли б використовувати безперервну міру сили зв'язку між акторами як міру «близькості». Щоб проілюструвати це, ми будемо використовувати шкалу подібності профілів внесків донорів, яка коливається від негативних чисел (вказуючи на те, що два донори дали гроші на протилежні сторони ініціатив) до позитивних чисел (із зазначенням кількості разів пожертвуваних на тій же стороні питань. Можна легко уявити інші підходи до індексації мережевої близькості акторів (наприклад, 1/геодезична відстань). Може бути використана будь-яка матриця «близькості», яка фіксує попарну близькість акторів (деякі ідеї див. Інструменти>Подібності та Інструменти>Відмінності та відстані ).
На малюнках 18.23 і 18.24 відображаються результати Інструменти>Тестування гіпотези>Змішана діадична/Вузлова >Безперервні атрибут>Статистика Moran/Geary де ми розглянули автокореляцію рівнів витрат суб'єктів, що використовують суміжність як нашу міру мережевої відстані. Дуже просто: чи схильні актори, які є сусідами в мережі, дають подібні суми грошей? Представлені дві статистичні дані та деяка відповідна інформація (статистика Морана на малюнку 18.23 та статистика Geary на малюнку 18.24.

Малюнок 18.23: Автокореляція Морана рівнів витрат політичними донорами з мережевою суміжністю
Статистика автокореляції Морана «I» (спочатку розроблена для вимірювання просторової автокореляції, але використовується тут для вимірювання мережевої автокореляції) коливається від -1,0 ( ідеальна негативна кореляція) через 0 (без кореляції) до+1,0 (ідеальна позитивна кореляція). Тут ми бачимо значення -0,119, що вказує на те, що існує дуже скромна тенденція для акторів, які сусідять, відрізняються більше тим, наскільки вони сприяють, ніж два випадкові актори. Якщо що-небудь, здається, що члени коаліції можуть відрізнятися більше за рівнем свого внеску, ніж випадкові актори - інша гіпотеза кусає пил!
Статистика Морана (див. Будь-який текст геостатистики або пошук Google) побудована дуже схоже на звичайний коефіцієнт кореляції. Він індексує добуток відмінностей між балами двох акторів і середнього, зваженого схожістю актора - тобто коваріацію, зважену близькістю акторів. Ця сума береться в співвідношенні до дисперсії в балах всіх дійових осіб від середнього. Отримана міра, як і коефіцієнт кореляції, є відношенням коваріації до дисперсії і має умовну інтерпретацію.
Перестановки випробувань використовуються для створення розподілу вибірки. У багатьох (у нашому прикладі 1000) випробувань бали за атрибутом (витрати, в даному випадку) випадковим чином призначаються акторам, а статистика Морана обчислюється. У цих випадкових випробуваннях середня спостережувана статистика Морана становить -0,043, зі стандартним відхиленням 0,073. Різниця між тим, що ми спостерігаємо (-0.119), і тим, що прогнозується випадковою асоціацією (-0.043), невелика щодо мінливості вибірки. Насправді, 17,4% всіх зразків з випадкових даних показали кореляції принаймні такі великі - набагато більше, ніж звичайна 5% прийнятна частота помилок.
Міра кореляції Гірі обчислюється і інтерпретується дещо інакше. Результати наведені на малюнку 18.24 для асоціації рівнів витрат по суміжності мережі.
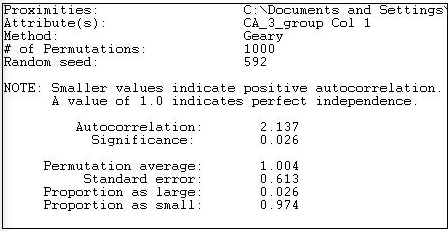
Малюнок 18.24: Автокореляція Geary рівнів витрат політичними донорами з мережевою суміжністю
Статистика Geary має значення 1.0, коли немає асоціації. Значення менше 1,0 вказують на позитивну асоціацію (дещо заплутано), значення більше 1,0 вказують на негативну асоціацію. Наше обчислене значення 2,137 вказує на негативну автокореляцію, як це робила статистика Морана. На відміну від статистики Морана, статистика Geary говорить про те, що різниця нашого результату від середнього 1,000 випадкових випробувань (1,004) є статистично значущою (p = 0,026).
Статистика Geary іноді описується в літературі геостатистики як більш чутлива до «локальних» відмінностей, ніж до «глобальних» відмінностей. Статистика Geary C будується шляхом вивчення відмінностей між балами кожної пари акторів та зважування цього за їх суміжністю. Статистика Морана будується шляхом розгляду відмінностей між оцінкою кожного актора та середнім значенням, а також зважування крос-продуктів. Різниця в підході означає, що статистика Geary більше орієнтована на те, наскільки різні члени кожної пари один від одного - «місцева» різниця; статистика Морана орієнтована більше на те, наскільки однакова або несхожа кожна пара до загального середнього - «глобальна» різниця.
У даних, де «ландшафт» значень відображає багато варіацій та ненормальний розподіл, ці дві міри, ймовірно, дадуть дещо різні враження про вплив суміжності мережі на схожість атрибутів. Як завжди, справа не в тому, що один «правильний», а інший «неправильний». Завжди найкраще обчислити обидва, якщо у вас немає сильних теоретичних пріоритетів, які свідчать про те, що один перевершує певну мету.
Цифри 18.25 і 18.26 повторюють вправу вище, але з однією різницею. У цих двох прикладах ми вимірюємо близькість двох акторів мережі в безперервному масштабі. Тут ми використали чисту кількість кампаній, в яких кожна пара акторів перебувала в одній коаліції, як міра близькості. Інші заходи, такі як геодезичні відстані, можуть частіше використовуватися для справжніх мережевих даних (а не для мережі, виведеної з приналежності).

Малюнок 18.25: Автокореляція рівнів витрат політичними донорами Морана з близькістю мережі
Використовуючи безперервну міру близькості мережі (замість суміжності), ми можемо очікувати сильнішої кореляції. Міра Морана зараз становить -0,145 (порівняно з -0,119), і є значною при p = 0,018. Існує невелика, але значна тенденція для акторів, які є «близькими» союзниками, давати різні суми грошей, ніж два випадково обрані актори — негативна мережева автокореляція.
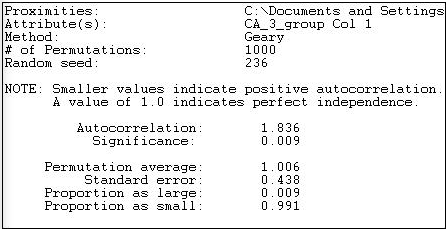
Малюнок 18.26: Автокореляція рівнів витрат політичними донорами Geary з близькістю мережі
Міра Geary стала трохи меншою за розміром (1,836 проти 2,137), використовуючи безперервну міру мережевої відстані. Результат також вказує на негативну автокореляцію, і таку, яка рідко траплялася б випадково, якщо справді не було зв'язку між мережевою відстанню та витратами.
Імовірність діадичного краватки: Р1 Лейнхардта
Підходи, які ми розглядали в цьому розділі, розглядають взаємозв'язок між атрибутами актора та їх розташуванням у мережі. Перш ніж закрити нашу дискусію про те, як статистичний аналіз застосовувався до мережевих даних, ми повинні розглянути один підхід, який вивчає, як зв'язки між парами акторів пов'язані з особливо важливими реляційними атрибутами акторів та з більш глобальною особливістю графіка.
Для будь-якої пари акторів в орієнтованому графі можливі три відносини: відсутність зв'язків, асиметрична краватка або зворотно-поступальна краватка. Мережа>P1 це регресійний підхід, який прагне передбачити ймовірність кожного з цих видів відносин для кожної пари акторів. Це трохи відрізняється від підходів, які ми розглядали досі, які прагнуть передбачити або наявність/відсутність краватки, або силу краватки.
Модель P1 (і її новіший наступник модель P*) прагнуть передбачити діадичні відносини між парами акторів, використовуючи ключові реляційні атрибути кожного актора, і графіка в цілому. Це відрізняється від більшості підходів, які ми бачили вище, які зосереджені на індивідуальних або реляційних атрибутах актора, але не включають загальні структурні особливості графіка (принаймні, не явно).
Модель Р1 складається з трьох рівнянь прогнозування, призначених для прогнозування ймовірності взаємного (тобто зворотно-поступального) відношення (m ij), асиметричного відношення (a ij), або нульове відношення (n ij) між акторами. Рівняння, як стверджують автори УСІНЕТ, такі:
\[m_{ij} = \lambda_{ij} e^{\rho + 2 \theta + \alpha_i + \alpha_j + \hat{a}_i + \hat{a}_j}\]
\[a_{ij} = \lambda_{ij} e^{\theta + \alpha_i + \beta_j}\]
\[n_{ij} = \lambda_{ij}\]
Перше рівняння говорить, що ймовірність взаємного зв'язку між двома акторами є функцією поза ступеня (або «експансивності») кожного актора: альфа i і альфа j. Вона також є функцією загальної щільності мережі (тета). Це також функція глобальної тенденції у всій мережі до взаємності (rho). Рівняння також містить константи масштабування для кожного актора в парі (a i і a j), а також глобальний параметр масштабування (лямбда).
Друге рівняння описує ймовірність того, що два актори будуть пов'язані асиметричним співвідношенням. Ця ймовірність є функцією загальної щільності мережі (тета), і схильності одного актора пари до відправки зв'язків (експансивність, або альфа), і схильності іншого актора до отримання зв'язків («привабливість» або бета).
Імовірність нульового відношення (без краватки) між двома акторами є «залишковою». Тобто, якщо зв'язки не взаємні або асиметричні, вони повинні бути нульовими. Тільки константа масштабування «лямбда», і ніякі причинно-наслідкові параметри не входять в третє рівняння.
Основна ідея полягає в тому, що ми намагаємося зрозуміти відносини між парами акторів як функції окремих реляційних ознак (тенденцій індивіда до відправки). зв'язки, і отримати їх), а також ключові особливості графіка, в який вбудовані два суб'єкти (загальна щільність і загальна тенденція до взаємності). Більш пізні версії моделі (P*, P2) включають додаткові глобальні особливості графіка, такі як тенденції до транзитивності та дисперсія між суб'єктами у схильності надсилати та отримувати зв'язки.
На малюнку 18.27 показані результати підгонки моделі Р1 до двійкової інформаційної мережі Кноке.
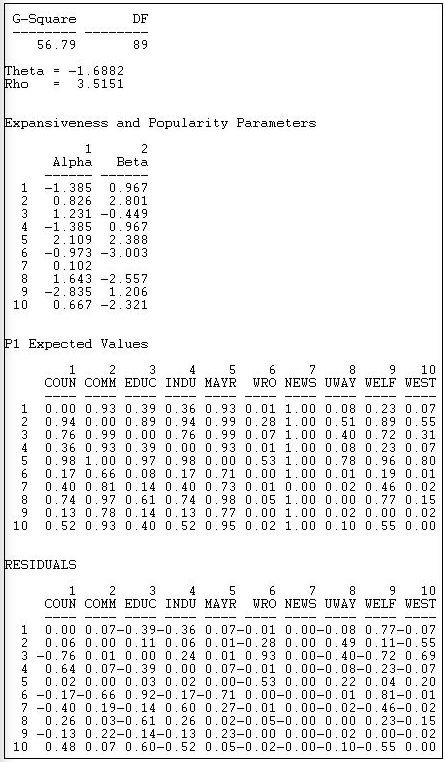
Малюнок 18.27: Результати аналізу P1 інформаційної мережі Кноке
Ускладнено технічні аспекти оцінки моделі Р1 та використано методи максимальної правдоподібності. G-квадрат (коефіцієнт ймовірності хі-квадрат) поганість статистики придатності надається, але не має прямої інтерпретації або тесту на значущість.
Наведено два описові параметри для властивостей глобальної мережі:
- \(\theta\) = -1.6882 refers to the effect of the global density of the network on the probability of reciprocated or asymmetric ties between pairs of actors.
- \(\rho\) = 3.5151 refers to the effect of the overall amount of reciprocity in the global network on the probability of a reciprocated tie between any pair of actors.
Для кожного актора наведено два описові параметри (вони оцінюються у всіх парних стосунках кожного актора):
\(\alpha\) ("expansiveness") refers to the effect of each actor's out-degree on the probability that they will have reciprocated or asymmetric ties with other actors. We see, for example, that the Mayor (actor 5) is a relatively "expansive" actor.
\(\beta\) ("attractiveness") refers to the effect of each actor's in-degree on the probability that they will have a reciprocated or asymmetric relation with other actors. We see here, for example, that the welfare rights organization (actor 6) is very likely to be shunned.
Використовуючи рівняння, можна прогнозувати ймовірність кожної спрямованої зв'язки на основі параметрів моделі. Вони відображаються як «Очікувані значення Р1». Наприклад, модель прогнозує 93% шанс нічию від актора 1 до актора 2.
Підсумкова панель вихідних даних показує різницю між зв'язками, які насправді існують, і прогнозами моделі. Модель прогнозує зв'язок від актора 1 до актора 2 досить добре (залишковий = .07), але робить погану роботу прогнозування відношення від актора 1 до актора 9 (залишковий = 0,77).
Залишки важливі, оскільки вони пропонують місця, де інші особливості графіка або особи можуть мати відношення до розуміння конкретних діад або де зв'язки між двома дійовими особами добре враховується основна «демографія» мережі. Які актори, ймовірно, матимуть зв'язки, які не передбачені параметрами моделі, також можна показати на дендограмі, як на малюнку 18.28.

Малюнок 18.28: Схема кластеризації P1 інформаційної мережі Кноке
Тут ми бачимо, що, наприклад, що актори 3 і 6 набагато частіше мають зв'язки, ніж прогнозує модель P1.