18.3: Порівняння двох відносин для одного набору акторів
- Page ID
- 67428
Основне питання двоваріантної описової статистики, застосованої до змінних, полягає в тому, чи вирівнюють бали на одному атрибуті (co-vary, корелюють) з оцінками на іншому атрибут, при порівнянні між випадками. Основне питання двоваріантного аналізу мережевих даних полягає в тому, чи узгоджується закономірність зв'язків для одного відношення між сукупністю акторів із схемою зв'язків для іншого відношення між тими ж суб'єктами. Тобто співвідносяться відносини?
Три найпоширеніші інструменти для двоваріантного аналізу атрибутів також можуть бути застосовані до двоваріантного аналізу відносин:
Чи суттєво відрізняється центральна тенденція одного відношення від центральної тенденції іншого? Наприклад, якби ми мали дві мережі, які описували військові та економічні зв'язки між народами, яка має більшу щільність? Військові чи економічні зв'язки більш поширені? Цей вид питання є аналогом тесту на різницю між засобами в парних або повторюваних заходах аналізу атрибутів.
Чи існує кореляція між зв'язками, які присутні в одній мережі, і зв'язками, які присутні в іншій? Наприклад, чи мають пари країн, які мають політичні союзи, мають великі обсяги економічної торгівлі? Цей вид питання аналогічний кореляції між балами двох змінних в атрибутивному аналізі.
Якщо ми знаємо, що зв'язок одного типу існує між двома суб'єктами, наскільки це збільшує (або зменшує) ймовірність того, що зв'язок іншого типу існує між їх? Наприклад, який вплив на один долар збільшення обсягу торгівлі між двома країнами на обсяг туризму, що протікає між двома країнами? Цей вид питання аналогічний регресії однієї змінної на іншу в аналізі атрибутів.
Гіпотези про два парних засобів або щільності
У розділі вище про уніваріативну статистику для мереж ми відзначили, що щільність матриці обміну інформацією для бюрократій Кноке виявилася вище щільності грошової біржової матриці. Тобто середнє значення або щільність одного відношення між сукупністю акторів, здається, відрізняється від середнього або щільності іншого відношення серед тих же акторів.
Мережа>Порівняти щільність>Парний (той самий вузол) порівнює щільності двох відносин для одних і тих же акторів та обчислює оцінені стандартні помилки для перевірки відмінностей методами початкового завантаження. Коли обидва відносини двійкові, це перевірка на відмінності ймовірності краватки одного типу і ймовірності краватки іншого типу. Коли обидва відносини цінуються, це перевірка на різницю в середній зв'язці сильних сторін двох відносин.
Проведемо цю перевірку на інформаційно-грошових відносин в даних Кноке, як показано на малюнку 18.7.
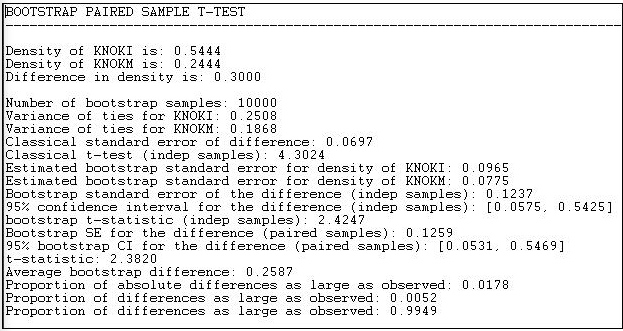
Малюнок 18.7: Тест на різницю щільності в ноке інформаційно-грошових відносин
Результати як для стандартного підходу, так і для початкового завантаження підходу (цього разу ми провели 10,000 під-зразків) повідомляються у виході. Різниця між засобами (або пропорціями, або щільністю) становить 0,3000. Стандартна похибка різниці класичним методом - 0,0697; стандартна похибка за оцінкою bootstrap - 0,1237. Звичайний підхід значно занижує справжню мінливість вибірки і дає результат, який є занадто оптимістичним у відкиданні нульової гіпотези про те, що дві щільності однакові.
Методом bootstrap ми можемо побачити, що існує двоххвоста ймовірність 0.0178. Якби у нас була попередня альтернативна гіпотеза про напрямок різниці, ми могли б використовувати однохвостий p рівень 0,0052. Отже, можна з великою упевненістю зробити висновок, що щільність інформаційних зв'язків між організаціями більше, ніж щільність грошових зв'язків. Тобто спостережувана різниця виникла б дуже рідко випадково у випадкових зразках, взятих з цих мереж.
Кореляція між двома мережами з однаковими акторами
Якщо між двома окремими суб'єктами в одному відношенні існує зв'язок, чи може бути зв'язок між ними в іншому відношенні? Якщо два актори мають міцну зв'язок одного типу, чи можуть вони також мати міцну зв'язок іншого?
Коли ми маємо інформацію про множинні відносини між однаковими наборами акторів, часто викликає значний інтерес, чи є ймовірність (або сила) краватки один тип пов'язаний з ймовірністю (або силою) іншого. Розглянемо Knoke інформаційні та грошові зв'язки. Якщо організації обмінюються інформацією, це може створити почуття довіри, що робить грошово-обмінні відносини більш імовірними; або, якщо вони обмінюються грошима, це може сприяти більш відкритим комунікаціям. Тобто можна було б припустити, що матриця інформаційних відносин позитивно корелювала б з матрицею грошових відносин - пари, які беруть участь в одному типі обміну, частіше займаються іншим. Як варіант, може бути, що відносини взаємодоповнюють: грошові потоки в одному напрямку, інформація в іншому (негативна кореляція). Або може бути, що ці два відносини не мають нічого спільного один з одним (немає кореляції).
Інструменти>Тестування гіпотез >Діадичні (QAP) >QAP кореляція обчислює міри номінальної, порядкової та інтервальної асоціації між відносинами у двох матрицях та використовує квадратичні процедури присвоєння для розробки стандартних помилок для перевірки значущості асоціація. На малюнку 18.8 показані результати кореляції між інформаційною мережею Кноке та валютно-обмінними мережами.

Малюнок 18.8: Асоціація між інформацією Кноке та грошовими мережами Кноке за кореляцією QAP
Перший стовпець показує значення п'яти альтернативних заходів асоціації. Кореляція Пірсона є стандартною мірою, коли обидві матриці мають оціночні відносини, виміряні на рівні інтервалу. Гамма була б розумним вибором, якби одне або обидва відносини вимірювалися за порядковою шкалою. Просте узгодження та коефіцієнт Жаккар є розумними мірами, коли обидва відносини є двійковими; відстань Хеммінга - це міра несхожості або відстані між балами в одній матриці та оцінками в іншій (це кількість значень, які поелементно відрізняються від однієї матриці до іншої).
Третій стовпець (Avg) показує середнє значення міри асоціації у великій кількості випробувань, в яких рядки та стовпці двох матриць були випадковим чином перестановлено. Тобто, якою була б кореляція (або інша міра) в середньому, якби ми відповідали випадковим акторам? Ідея «Порядку квадратичного присвоєння» полягає у визначенні значення міри асоціації, коли їх насправді не є систематичним зв'язком між двома відносинами. Це значення, як ви бачите, не обов'язково дорівнює нулю - оскільки різні заходи асоціації матимуть обмежені діапазони значень, засновані на розподілах балів у двох матрицях. Зауважимо, наприклад, що спостерігається просте узгодження 0,456 (тобто якщо в осередку матриці є 1, є 45.6% ймовірність того, що у відповідній комірці матриці два буде 1). Це, здавалося б, вказує на асоціацію. Але, через щільність двох матриць, узгодження випадково перевпорядкованих матриць буде відображати середнє відповідність 0,475. Так що спостережувана міра навряд чи відрізняється від випадкового результату.
Щоб перевірити гіпотезу про наявність асоціації, ми розглянемо частку випадкових випробувань, які б генерували коефіцієнт, такий великий, як (або такий малий, як, залежно від міра) реально спостережувана статистика. Ці цифри повідомляються (з випадкових випробувань перестановки) у стовпцях з маркуванням «P (large)» та «P (малий)». Відповідне одне з цих значень для перевірки нульової гіпотези відсутності асоціації показано у стовпці «Знак».
Мережева регресія
Замість того, щоб співвідносити одне відношення з іншим, ми можемо захотіти передбачити одне відношення, знаючи інше. Тобто замість симетричної асоціації між відносинами ми, можливо, побажаємо розглянути асиметричну асоціацію. Стандартним інструментом для цього питання є лінійна регресія, і підхід може бути розширений на використання більш ніж однієї незалежної змінної.
Припустимо, наприклад, що ми хотіли побачити, чи можемо ми передбачити, яка з бюрократій Кноке надіслала інформацію, до якої інші. Ми можемо розглядати мережу обміну інформацією як нашу «залежну» мережу (з N = 90).
Ми можемо припустити, що наявність грошового зв'язку від однієї організації до іншої збільшить ймовірність інформаційного зв'язку (звичайно, від попередньої розділ, ми знаємо, що це емпірично не підтримується!). Крім того, ми можемо припустити, що інституційно подібні організації будуть частіше обмінюватися інформацією. Отже, ми створили ще одну матрицю 10 на 10, кодуючи кожен елемент як «1», якщо обидві організації в діаді є державними органами, або обидві є неурядовими органами, і «0», якщо вони змішаних типів.
Тепер ми можемо виконати стандартний множинний регресійний аналіз шляхом регресування кожного елемента інформаційної мережі на відповідні його елементи в грошовій мережі. та мережею державних установ. Для оцінки стандартних похибок для R-квадратів та коефіцієнтів регресії можна використовувати квадратичне присвоєння. Ми проведемо багато випробувань із рядками та стовпцями в залежній матриці, випадково перемішані, та відновлюємо R-квадрат та коефіцієнти регресії з цих прогонів. Потім вони використовуються для складання емпіричних розподілів вибірки для оцінки стандартних помилок за гіпотезою відсутності асоціації.
Версія 6.81 UCINET пропонує чотири альтернативні методи для Інструменти>Тестування гіпотез >Діадична (QAP) >Регресія QAP . На малюнку 18.9 показані результати методу «повного партіаллірованія».
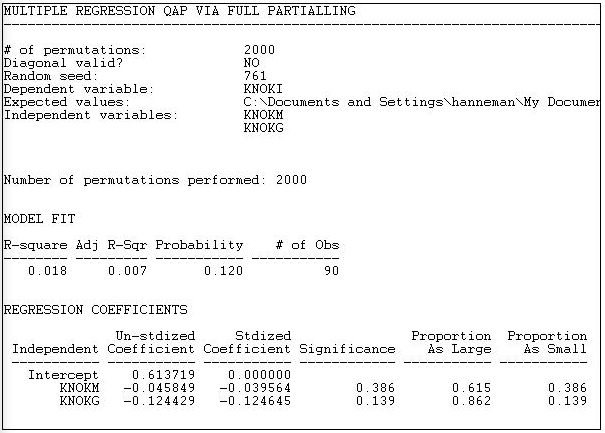
Малюнок 18.9: Регресія QAP інформаційних зв'язків про грошові зв'язки та державний статус методом повного партиалізації
Описова статистика та міра добра придатності є стандартними результатами множинної регресії - за винятком, звичайно, що ми дивимося на прогнозування відносин між акторами, а не атрибутами акторів.
Модель R-квадрат (0,018) вказує на те, що знання того, чи відправляє одна організація гроші іншій, і чи дві організації інституційно схожі, зменшує невизначеність у прогнозуванні інформаційної зв'язки лише приблизно на 2%. Рівень значущості (за методом QAP) - 0,120. Зазвичай ми робимо висновок, що ми не можемо бути впевнені, що спостережуваний результат є невипадковим.
Оскільки залежна матриця в цьому прикладі є двійковою, рівняння регресії інтерпретується як лінійна модель ймовірності (можна розглянути logit або probit). моделі — але УСІНЕТ таких не надає). Перехоплення вказує на те, що якщо дві організації не мають одного інституційного типу, а одна не надсилає гроші іншій, ймовірність того, що одна надсилає інформацію іншій, становить 0,61. Якщо одна організація дійсно відправляє гроші іншій, це знижує ймовірність інформаційного посилання на 0,046. Якщо дві організації мають один і той же інституційний тип, ймовірність відправки інформації знижується на 0,124.
Однак, використовуючи метод QAP, жоден з цих ефектів не відрізняється від нуля на звичайних (наприклад, p < 0,05) рівнях. Результати цікаві - вони припускають, що грошові та інформаційні зв'язки, якщо що, є альтернативою, а не відновленням зв'язків, і що інституційно подібні організації рідше спілкуються. Але ми не повинні сприймати ці очевидні закономірності серйозно, тому що вони можуть з'являтися досить часто просто випадковою перестановкою випадків.
Інструменти в цьому розділі дуже корисні для вивчення того, як мультиплексні відносини між набором акторів «йдуть разом». Ці інструменти часто можуть бути корисними доповненнями до деяких інструментів для роботи з мультиплексними даними, які ми розглянули в розділі 16.