16.2: Основи мультиплексних даних
- Page ID
- 67395
Мультиплексні дані - це дані, які описують множинні відносини між одним і тим же набором акторів. Міри відносин можуть бути спрямовані чи ні; і відносини можуть бути записані як двійкові, багатозначні номінальні або цінні (порядкові або інтервальні).
Найпоширенішою структурою мультиплексних даних є набір матриць за актором (або «зрізів»), по одній для кожного відношення. На малюнку 16.1 показані вихідні дані Data>Display для набору даних організацій соціального забезпечення Knoke, який містить інформацію про два (двійкові, спрямовані) відносини: обмін інформацією (KNOKI) та обмін грошовими коштами (КНОКМ).

Малюнок 16.1: Дані > Відображення багатореляційної структури даних Кноке
Ці два відносини зберігаються як окремі матриці, але в одному файлі. Багато інструментів аналізу в UCINET оброблять кожну матрицю або «фрагмент» файлу даних з кількома матрицями, як приклад Knoke. Data> Unpack може бути використаний для видалення окремих матриць з декількох файлів матриць; Data>Join можна використовувати для створення множинно-матричного набору даних з окремих одноматричних файлів даних.
Багатоматричний підхід є найбільш загальним і дозволяє нам записувати стільки різних відносин, скільки ми хочемо, використовуючи окремі матриці. Деякі матриці можуть бути симетричними, а інші ні; деякі можуть бути двійковими, а інші цінними. Ряд інструментів, про які ми обговоримо найближчим часом, вимагатимуть, щоб дані в декількох матрицях були одного типу (симетричні/асиметричні, двійкові/значні). Отже, часто потрібно буде робити перетворення на окремих матрицях, перш ніж можна буде застосувати стратегії «скорочення» та «комбінації».
Тісно пов'язаною структурою мультиплексних даних є «Когнітивна соціальна структура» або CSS. CSS записує сприйняття ряду суб'єктів відносин між набором вузлів. Наприклад, ми можемо попросити кожного з Боба, Керол, Теда та Аліси розповісти нам, хто з ким з них дружив. Результатом буде чотири матриці однакової форми (4 актори по 4 актори), які повідомляють про те саме відношення (хто з ким дружить), але відрізняються залежно від того, хто робить репортаж та сприймає.
Дані CSS мають точно таку ж форму, як і стандартні фрагменти актора за актором. І деякі інструменти, що використовуються для індексації даних CSS, однакові. Через унікальність даних CSS - які орієнтовані на складне сприйняття єдиної структури, замість єдиного сприйняття складної структури - можуть бути застосовані деякі додаткові інструменти (докладніше, нижче).
Третя, і досить інша структура даних - багатозначна матриця. Припустимо, що відносини між акторами були номінальними (тобто якісними, або «теперішні-відсутніми»), але існували кілька видів відносин, які може мати кожна пара акторів - утворюючи номінальну поліотомію. Тобто кожна пара акторів мала один (і тільки один) з декількох видів відносин. Наприклад, відносини між сукупністю акторів можуть (у деяких популяціях) кодуватися як «співзасновник ядерної сім'ї» або «колеги» або «розширений член сім'ї» або «однорелігійний» або «жоден». Для іншого прикладу ми могли б об'єднати кілька відносин для створення якісних типів: 1 = тільки кін, 2 = тільки колега, 3 = як родичі, так і колеги, і 4 = ні родичі, ні колеги.
Номінальні, але багатозначні дані об'єднують інформацію про мультиплексних зв'язках в єдину матрицю. Значення, однак, не представляють міцність, вартість або ймовірність краватки, а навпаки розрізняють якісний тип краватки, який існує між кожною парою акторів. Запис даних таким чином є ефективним, і деякі алгоритми в UCINET (наприклад, Categorical REGE) можуть працювати безпосередньо з ним. Однак часто дані про мультиплексні відносини, які були збережені в одній багатозначній матриці, повинні бути перетворені, перш ніж ми зможемо виконати багато мережевих операцій над нею.
Візуалізація мультиплексних зв'язків
Для відносно невеликих мереж малювання графіків є найкращим способом «бачити» структуру. Єдина нова проблема полягає в тому, як представляти множинні відносини між акторами. Один підхід полягає у використанні декількох рядків (з різними кольорами або стилями) та накладення одного відношення на інше. Крім того, можна «зв'язати» відносини на якісні типи та представляти їх єдиним графіком, використовуючи лінії різних кольорів або стилів (наприклад, kin tie = червоний; work tie = синій; kin та work tie = зелений).
Netdraw має деякі корисні інструменти для візуалізації декількох відносин між одним і тим же набором акторів. Якщо дані були збережені у вигляді декількох матриць у одному файлі, коли цей файл відкрито (NetDraw> File>Open> UCinet Dataset>Network) діалогове вікно «Зв'язки» дозволить вам вибрати, яку матрицю для перегляду (а також встановити значення відсікання для візуалізації цінні дані). Це корисно для перегортання взад-вперед між відносинами, при цьому вузли залишаються в тих самих місцях. Припустимо, наприклад, ми зберегли десять матриць у файлі, відображаючи знімки відносин у мережі, коли вона розвивалася протягом деякого періоду часу. Використовуючи діалогове вікно «Зв'язки», ми можемо «перевернути сторінки», щоб побачити розвиток мережі.
Ще більш корисний інструмент можна знайти в NetDraw> Властивості> Лінії > Виділення декількох зв'язків. Креслення мережі Knoke з видимим діалоговим вікном показано на малюнку 16.2.
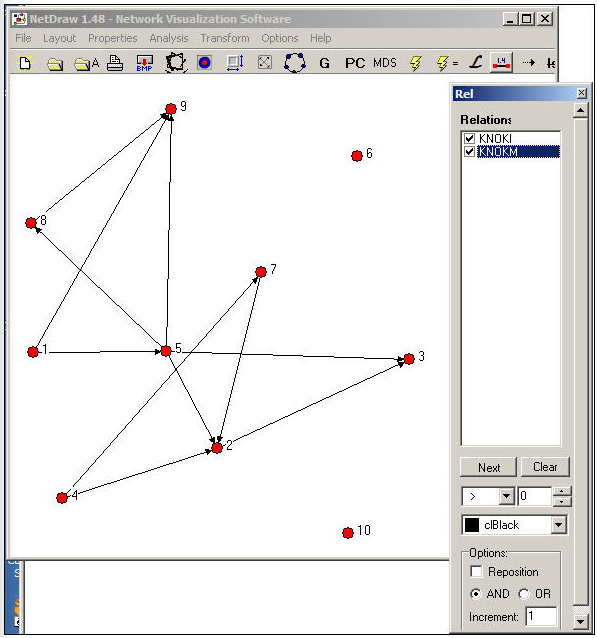
Малюнок 16.2: Графік NetDraw інформаційно-грошових мереж Knoke
За допомогою діалогового вікна «Відносини» ви можете вибрати, які зв'язки ви хочете переглянути, а також переглянути об'єднання («або») або перетин («і») зв'язків. У нашому прикладі ми попросили побачити схему зв'язків між організаціями, які надсилають як інформацію, так і гроші іншим.
Поєднання декількох відносин
Для більшості аналізів інформацію про множинні відносини між суб'єктами потрібно буде об'єднати в єдиний підсумковий захід. Одним із загальних підходів є об'єднання множинних відносин в індекс, який відображає якість (або тип) мультиплексного відношення.
Трансформа>Мультиплекс може бути використаний для узагальнення множинних відносин між акторами в якісний багатозначний індекс. Припустимо, що ми виміряли два відносини між Бобом, Керол, Тедом і Алісою. Перша - спрямована номінація дружби, а друга - неспрямоване подружнє відношення. Ці дві двійкові матриці чотири на чотири були упаковані в єдиний файл даних під назвою BCTaJoin. Діалогове вікно «Трансформувати> Мультиплекс» показано на малюнку 16.3.
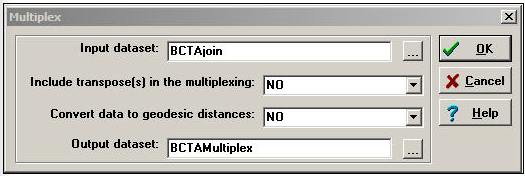
Малюнок 16.3: Трансформування> Мультиплексне діалогове вікно
Тут є два варіанти. Перетворення даних на геодезичні відстані дозволяє нам спочатку перетворити кожне відношення в цінну метрику з двійкового. Ми вирішили цього не робити. Інший вибір полягає в тому, чи включати транспонування (и) в мультиплексування. Для асиметричних даних вибір yes призведе до того, що рядки та стовпці вхідної матриці будуть розглядатися як окремі відносини при формуванні якісних комбінацій. Знову ж таки, ми вирішили цього не робити (хоча це розумна ідея у багатьох реальних випадках).
На малюнку 16.4 показаний вхідний файл, який складається з двох «покладених» або «нарізаних» матриць, що представляють дружбу і подружні зв'язки.

Малюнок 16.4: Трансформувати> Мультиплексний вхід
На малюнку 16.5 показана отримана «типологія» видів відносин між суб'єктами, яка була сформована у вигляді багатозначного номінального індексу.
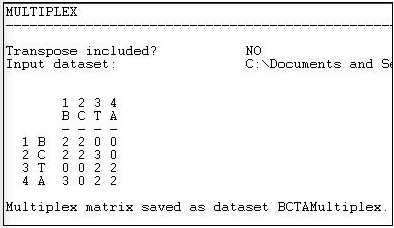
Малюнок 16.5: Трансформувати> Мультиплексний вихід
Там, де немає краватки ні в одній з матриць, був призначений тип «0". Там, де є і дружба, і подружня краватка, присвоєно число «2»; там, де є дружба краватка, але немає подружньої краватки, присвоєно число «3». Там міг бути додатковий тип (подружня краватка, але без дружби), якому було б присвоєно інший номер.
Поєднання множинних відносин таким чином дає якісну типологію видів відносин, які існують між суб'єктами. Індекс цього типу може представляти значний інтерес для опису поширеності типів у популяції та вибору підграфіків для більш детального аналізу.
Операція Трансформа>Мультиграф робить зворотне те, що робить Трансформа>Мультиплекс. Тобто, якщо ми почнемо з багатозначної одиночної матриці (як на рис. 16.5), ця операція дозволить розділити дані і створити множинний файл даних матриці з однією матрицею для кожного «типу» відношення. У випадку нашого прикладу, Transform> Multigraph створить дві нові матриці (одна описує відношення «2", і одна описує відношення «3").
Маючи справу з численними відносинами між суб'єктами, ми також можемо захотіти створити кількісний індекс, який поєднує відносини. Наприклад, ми можемо припустити, що якщо актори пов'язані 4 різними відносинами, вони поділяють «сильнішу» зв'язок, ніж якщо вони поділяють лише 3 відносини. Але існує багато можливих способів створення індексів, які захоплюють різні аспекти або виміри множинних відносин між суб'єктами. Два набори інструментів в UCINET підтримують об'єднання декількох матриць з широким спектром вбудованих функцій для захоплення різних аспектів мультиреляційних даних.
Трансформа>Матричні операції>Матричні операції>Між наборами даних>Статистичні резюме надає деякі основні інструменти для створення однозначної матриці з декількох матриць. На малюнку 16.6 показано діалогове вікно для цього інструмента.
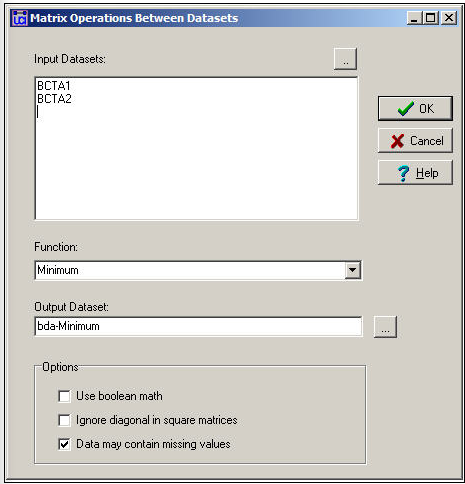
Малюнок 16.6: Діалогове вікно між операціями з матрицею даних - статистичні зведення
У прикладі ми вибрали дві окремі однорічні матриці для Боба, Керол, Теда та Аліси і попросили створити новий набір даних (одна матриця) під назвою BDA-мінімум. Вибравши функцію Minimum, ми вибрали правило, яке говорить: подивіться на відносини між матрицями та підсумовуйте кожне попарне відношення як найслабший. Для двійкових даних це те ж саме, що і логічна операція «і».
Також доступні в цьому діалоговому вікні Sum (який додає значення поелементно по матрицях); середнє (яке обчислює середнє, поелементно по матрицях); Максимум (який вибирає найбільше значення поелементно); і поелементне множення (яке множить елементи по матрицях). Це досить корисний набір інструментів, і відображає більшість способів, за допомогою яких можуть бути створені кількісні показники (найслабша краватка, найсильніша краватка, середня краватка, взаємодія зв'язків).
Ми могли б захотіти об'єднати інформацію про множинні відносини в кількісний індекс, використовуючи логічні операції замість числових. На малюнку 16.7 показано діалогове вікно Перетворення> Матричні операції>Матричні операції> Між наборами даних> Булеві комбінації.
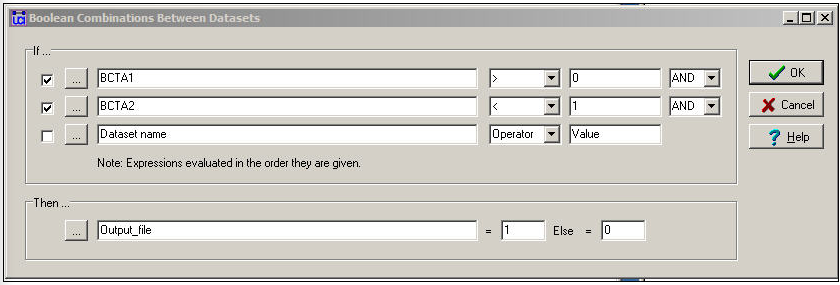
Малюнок 16.7: Діалогове вікно між операціями з матрицею набору даних - Булеві комбінації
У цьому діалозі ми сказали: якщо є зв'язок дружби і немає подружньої зв'язки, то кодуйте вихідне відношення як «1". В іншому випадку кодуйте вихідне відношення як «0". Це не дуже розумна річ, але вона ілюструє те, що цей інструмент може бути використаний для виконання основних логічних операцій для створення цінних (або двійкових) індексів, які поєднують інформацію про множинні відносини.
Поєднання декількох переглядів
Припустимо, що я попросив кожного співробітника факультету моєї кафедри заповнити анкету, звітуючи про свої уявлення про те, хто кому подобається серед факультету. Ми збирали б дані про «когнітивну соціальну структуру»; тобто звіти від акторів, вбудованих в мережу, про всю мережу. Існує дуже цікава дослідницька література, яка досліджує взаємозв'язок між позиціями акторів у мережах та їх сприйняттям мережі. Наприклад, чи мають актори ухил до сприйняття власних позицій як більш «центральних», ніж сприйняття іншими акторами своєї центральності?
Набір даних когнітивної соціальної структури (CSS) містить кілька матриць за актором. Кожна матриця повідомляє про повний набір єдиного відношення між усіма дійовими особами, як сприймається конкретним респондентом. Хоча ми могли б використовувати багато інструментів, розглянутих у попередньому розділі, щоб об'єднати або зменшити подібні дані в індекси, є деякі спеціальні інструменти, які застосовуються до когнітивних даних. На малюнку 16.8 показано діалогове вікно Data>CSS, яке надає доступ до деяких спеціалізованих інструментів для когнітивного дослідження мережі.
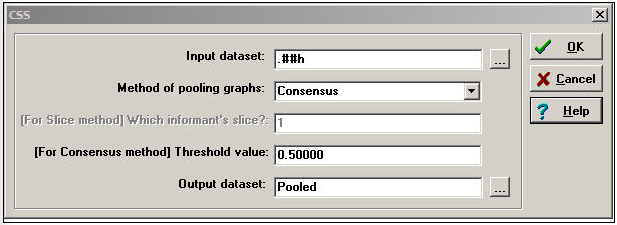
Малюнок 16.8: Діалогове вікно даних> CSS
Ключовим елементом тут є вибір методу для об'єднання графіків. Створюючи єдиний підсумок відносин, ми могли б вибрати сприйняття одного актора; або, можливо, ми захочете зосередитись на сприйнятті пари акторів, що беруть участь у кожному конкретному стосунку; або ми можемо захотіти об'єднати інформацію всіх акторів у мережі.
Зріз вибирає сприйняття одного конкретного актора для представлення мережі (потім діалогове вікно запитує: «Який інформатор?»). Якби у нас був конкретний експерт-інформатор, ми могли б вибрати його/її погляд на мережу як резюме. Або ми могли б витягти кілька різних акторів у різні файли. Ми також можемо витягувати акторів на основі деяких атрибутів (наприклад, статі) і витягти їх графіки, а потім об'єднати їх іншим методом.
Рядок LAS використовує дані з кожного рядка актора, щоб бути рядком у вихідній матриці. Тобто сприйняття актором А його значень рядків використовується для рядка A у вихідній матриці; сприйняття актором B його значень рядків використовується для рядка B у вихідній матриці. Це використовує кожного актора як «інформатора» про свої власні зв'язки.
Колонка LAS використовує стовпець кожного актора як запис стовпця у вихідній матриці. Тобто кожен актор використовується як «інформатор» щодо власних зв'язків.
Перетин LAS будує вихідну матрицю, вивчаючи записи конкретної пари задіяних акторів. Наприклад, у вихідній матриці ми мали б елемент, який описував відношення між Бобом і Тедом. У нас є дані про те, як Боб, Тед, Керол і Аліса сприймають відносини Боба і Теда. Метод LAS фокусується лише на двох задіяних вузлах (Боб і Тед) і ігнорує інші. Метод перетину дає «1" для краватки, якщо обидва Боб і Тед кажуть, що є краватка, і «0" інакше.
Союз LAS призначає «1" до парного відношення, якщо будь-який актор (тобто або Боб або Тед) каже, що є краватка.
Медіана LAS вибирає медіану двох значень для співвідношення B, T, про які повідомляють B і T. Це корисно, якщо досліджуване відношення є цінним, а не двійковим.
Консенсус використовує сприйняття всіх акторів для створення підсумкового індексу. Сприйняття Боба, Керол, Теда та Аліси підсумовуються, і якщо сума більша за вказане користувачем значення відсікання, призначається «1", інакше «0".
Середнє обчислює числове середнє сприйняття всіх акторів кожної парної краватки.
Сума обчислює суму сприйняття всіх акторів за кожну парну краватку.
Діапазон вибору тут передбачає благодатну область досліджень у тому, як суб'єкти, вбудовані у відносини, сприймають ці відносини. Різноманітність методів індексації також передбачає ряд цікавих питань щодо та методів боротьби з достовірністю мережевих даних, коли вони збираються від вбудованих респондентів.