13.4: Опис структурних наборів еквівалентності
- Page ID
- 67413
Два суб'єкти, які структурно еквівалентні, мають однакові зв'язки з усіма іншими акторами - вони ідеально замінні або обмінні. У «реальних» даних точна еквівалентність може бути досить рідкісною, і багато хто має сенс виміряти приблизну еквівалентність. Існує кілька підходів до вивчення закономірності подібності в зв'язках профілів акторів, а також для формування класів структурної еквівалентності.
Один дуже корисний підхід полягає в застосуванні кластерного аналізу, щоб спробувати визначити, скільки існує наборів структурної еквівалентності, і які суб'єкти потрапляють у кожен набір. Ми розглянемо ще два поширені підходи - CONCOR, і числову оптимізацію за допомогою пошуку табу.
Те, що матриця подібності та кластерний аналіз нам не говорять, це те, що подібність робить акторів у кожному наборі «однаковими» і які відмінності роблять акторів в одному наборі «відмінними» від акторів в іншому. Дуже корисним підходом до розуміння основ подібності і відмінності між множинами структурно еквівалентних акторів є блокова модель, а резюме на її основі називається матрицею зображення. Обидві ці ідеї були пояснені в іншому місці. Ми розглянемо, як вони можуть допомогти нам зрозуміти результати пошуку CONCOR та tabu.
Кластеризація подібності або відстаней профілів
Кластерний аналіз є природним методом дослідження структурної еквівалентності. Два актори, які мають схожі моделі зв'язків з іншими акторами, будуть об'єднані в кластер, а ієрархічні методи покажуть «дерево» послідовного приєднання.
Мережа>Ролі та позиції>Структурний>Профіль може виконувати різні види кластерного аналізу для оцінки структурної еквівалентності. На малюнку 13.12 показано типове діалогове вікно для цього алгоритму.

Малюнок 13.12: Діалогове вікно мережі>Ролі та позиції>Структурні> Профіль
Залежно від того, як були виміряні відносини між акторами, передбачено кілька поширених способів побудови акторної подібності або матриці відстані (кореляції, евклідові відстані, сумарні збіги або коефіцієнти Жаккар). Якщо вам потрібна інша міра подібності, ви можете побудувати її в іншому місці (наприклад, Інструменти> Подібності), зберегти результат і застосувати кластерний аналіз безпосередньо (тобто Інструменти> Кластер).
Є й інші важливі варіанти вибору. По-перше, що робити з елементами матриці подібності, які індексують схожість актора з собою (тобто діагональні значення)? Один вибір («Зберегти») включає схожість вузла з самим собою; інший вибір («Ігнорувати») виключає діагональні елементи з розрахунку подібності або різниці. Метод за замовчуванням («Взаємний») замінює діагональний елемент для обох випадків на зв'язок, який існує між випадками.
Можна «Включити транспонування» чи ні. Якщо дані, що досліджуються, симетричні (тобто простий граф, а не спрямований), то транспонування ідентичне матриці, і його не слід включати. Для спрямованих даних алгоритм за замовчуванням обчислює подібність рядків (out-ties), але не в зв'язках. Якщо ви хочете включити повний профіль як вхідних, так і зовнішніх зв'язків для спрямованих даних, вам потрібно включити транспонування.
Якщо ви працюєте з необробленою матрицею суміжності, подібність можна обчислити на профілі краватки (ймовірно, за допомогою відповідності або підходу Жаккарда). Крім того, примикань можна перетворити на цінну міру несхожості шляхом обчислення геодезичних відстаней (в цьому випадку кореляції або евклідові відстані можуть бути обрані як міра подібності).
На малюнку 13.13 показані результати аналізу, описані в діалоговому вікні.

Малюнок 13.13: Профіль подібності геодезичних відстаней рядків і стовпців інформаційної мережі Кноке
На першій панелі показана матриця структурної еквівалентності - або ступінь подібності між парами акторів (в даному випадку несхожість, так як ми вибрали для аналізу евклідових відстаней).
На другій панелі показано грубу графіку кластеризації, відображену символами. Тут ми бачимо, що актори 7 і 4 найбільш схожі, друге скупчення формують актори 1 і 5; третій - актори 8 і 9. Цей алгоритм також забезпечує більш відшліфоване представлення результату у вигляді дендограми в окремому вікні, як показано на малюнку 13.14.

Малюнок 13.14: Дендограма даних структурної еквівалентності (див. Рис.
У прикладі даних немає точної структурної еквівалентності. Тобто не існує двох випадків, які мають однакові зв'язки з усіма іншими справами. Дендограма може бути особливо корисною для визначення груп випадків, які є достатньо еквівалентними для розгляду як класів. Заходи адекватності кластеризації в Інструментів>Кластер можуть надати додаткові вказівки.
Два інших підходи, CONCOR та оптимізація, слідують дещо іншій логіці, ніж кластеризація. В обох цих методах спочатку встановлюються розділи або приблизні класи еквівалентності (користувач вибирає, скільки), а випадки виділяються цим класам числовими прийомами, покликаними максимізувати схожість всередині класів.
КОНКОР
CONCOR - це підхід, який використовується вже досить давно. Хоча алгоритм CONCOR зараз розглядається як трохи своєрідний, методика зазвичай дає значущі результати.
CONCOR починається з співвіднесення кожної пари акторів (як ми це робили вище). Кожен рядок цієї кореляційної матриці актора за актором потім витягується і співвідноситься один з одним рядком. У певному сенсі підхід запитує «наскільки схожий вектор подібності актора X на вектор подібності актора Y»? Цей процес повторюється знову і знову. Зрештою елементи в цій «ітераційній кореляційній матриці» сходяться на значенні +1 або -1 (якщо ви хочете переконати себе, спробуйте!).
Потім CONCOR розділяє дані на два набори на основі цих кореляцій. Потім в межах кожного набору (якщо в ньому більше двох дійових осіб) процес повторюється. Процес триває до тих пір, поки всі актори не будуть розділені (або поки ми не втратимо інтерес). Результатом є двійкове розгалужене дерево, яке дає початок остаточному розділу.
Для ілюстрації ми попросили CONCOR показати нам групи, які найкраще задовольняють цій властивості, коли ми вважаємо, що в інформаційних даних Knoke є чотири групи. Ми використовували Мережа> Ролі та позиції>Структурний> Concor, і встановили глибину розколів = 2 (тобто розділити дані двічі). Всі алгоритми блокування вимагають, щоб ми мали попереднє уявлення про те, скільки груп існує. Результати наведені на малюнку 13.15.

Малюнок 13.15: CONCOR на інформаційній матриці Кноке з двома розщепленнями
На першій панелі показані кореляції випадків. Ми включили транспонування, тому ці кореляції засновані як на відправці, так і на отриманні зв'язків. Наші дані, однак, є двійковими, тому до використання коефіцієнта кореляції (і CONCOR) слід ставитися з обережністю.
На другій панелі зображені два розколу. У першому розподілі утворилися дві групи {1, 4, 5, 2, 7} та {8, 3, 9, 6, 10}. На другому розділенні вони поділялися на {1, 4}, {5, 2, 7}, {8, 3, 9} та {6, 10}.
Третя панель («Заблокована матриця») показує перестановлені вихідні дані. Результат тут можна було б спростити, створивши матрицю «block image» чотирьох класів за чотирма класами, з «1» в блоках високої щільності і «0» в блоках низької щільності - як на малюнку 13.16.
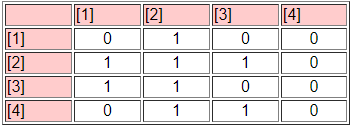
Малюнок 13.16: Блокове зображення результатів CONCOR
Доброгідність придатності блокової моделі можна оцінити шляхом співвіднесення перестановленої матриці (блокової моделі) з «ідеальною» моделлю з тими ж блоками (тобто тим, у якому всі елементи одного блоку є одиницями, а всі елементи нульових блоків - нулями). Для моделі CONCOR з двома розділеними (чотири групи) цей r-квадрат дорівнює 0,451. Тобто приблизно 1/2 дисперсії в зв'язках в моделі CONCOR може припасти на «ідеальну» структурну блокову модель. Це може розглядатися як добре, але навряд чи є чудовим підходом (немає реального критерію того, що добре підходить).
Модель блоку та її зображення також дають опис того, що це означає, коли ми говоримо «актори в першому блоці приблизно структурно еквівалентні». Актори першого класу еквівалентності, швидше за все, посилають зв'язки з усіма іншими акторами у блоці два, але жоден інший блок. Актори першого класу еквівалентності, швидше за все, отримають зв'язки від усіх акторів у блоках 2 та 3. Отже, ми не тільки визначили класи, ми також описали форму відносин, що робить випадки еквівалентними.
Оптимізація за допомогою пошуку Tabu
Цей метод блокування був розроблений зовсім недавно, і спирається на широке використання комп'ютера. Пошук табу використовує більш сучасний (і комп'ютерний інтенсивний) алгоритм, ніж CONCOR, але намагається реалізувати ту ж саму ідею групування акторів, які найбільш схожі в блок. Пошук табу робить це шляхом пошуку наборів акторів, які, якщо їх розмістити в блоці, виробляють найменшу суму відхилень всередині блоку в профілі зв'язків. Тобто, якщо актори в блоці мають схожі зв'язки, їх дисперсія навколо блоку середнього профілю буде невеликою. Отже, поділ, який мінімізує суму відхилень всередині блоку, мінімізує загальну дисперсію в профілі стяжки. В принципі, цей метод повинен давати результати, подібні (але не обов'язково ідентичні) CONCOR. На практиці це не завжди так. Тут (рис. 13.17) наведено результати Мережа>Ролі та позиції>Структурний>Оптимізація>Бінарний, застосований до інформаційної мережі Knoke, і запитує чотири класи. Варіація методики для цінних даних доступна як Мережа> Ролі та позиції> Структурні> Оптимізація> Цінується.

Малюнок 13.17: Оптимізоване чотириблочне рішення для структурної еквівалентності інформаційної мережі Кноке
Загальна кореляція між фактичними оцінками в заблокованій матриці та «ідеальною» матрицею, що складається лише з одиниць та нулів, є досить хорошою (0.544).
Пропонований поділ на класи структурної еквівалентності: {7}, {1, 3, 4, 10, 8, 9}, {5, 2} та {6}.
Тепер ми також можемо описати позиції кожного з класів. Перший клас (актор 7) має щільні посилаючі зв'язки з третім (актори 5 і 2); і отримує інформацію з усіх трьох інших класів. Другий, і найбільший, клас відправляє інформацію в перший і третій клас, а також отримує інформацію з третього класу. Останній клас (актор 6), відправляє в перший клас, але отримує від жодного.
Цей останній аналіз найбільш повно ілюструє основні цілі аналізу структурної еквівалентності:
1) Скільки класів еквівалентності, або приблизних класів еквівалентності, існує?
2) Наскільки добре підходить це спрощення в класи еквівалентності при узагальненні інформації про всі вузли?
3) Яка позиція кожного класу, визначена його відносинами до інших класів?