13.3: Візуалізація подібності та відстані
- Page ID
- 67412
У попередньому розділі ми бачили, як ступінь подібності або відстані між двома акторами моделей зв'язків з іншими акторами можна виміряти та індексувати. Як тільки це буде зроблено, то що?
Часто корисно вивчити подібності або відстані, щоб спробувати знайти групи акторів (тобто більших за пару), які схожі. Вивчаючи більші закономірності того, які групи акторів схожі на інші, ми також можемо отримати деяке розуміння того, що «як щодо» позиції актора є найбільш критичними для того, щоб зробити їх більш схожими або більш віддаленими.
Два інструменти, які зазвичай використовуються для візуалізації закономірностей відносин між змінними, також дуже корисні для вивчення даних соціальних мереж. Коли ми створили матрицю подібності або відстані, що описує всі пари акторів, ми можемо вивчати схожість відмінностей між «випадками» відносин так само, як ми б вивчали подібність між атрибутами.
У наступних двох розділах ми покажемо дуже короткі приклади того, як багатовимірне масштабування та ієрархічний кластерний аналіз можуть бути використані для виявлення закономірностей у матрицях схожості/відстані за актором. Обидва ці інструменти широко використовуються в немережевому аналізі; є великі та чудові літератури про багато важливих складнощів використання цих методів. Наша мета тут полягає лише в тому, щоб надати лише дуже базове введення.
Інструменти кластеризації
Агломеративна ієрархічна кластеризація вузлів на основі подібності їх профілів зв'язків з іншими випадками забезпечує «з'єднувальне дерево» або «дендограму», яка візуалізує ступінь подібності між випадками - і може бути використана для пошуку наближених класів еквівалентності.
Інструменти>Кластер>Ієрархічна триває, спочатку розміщуючи кожен випадок у своєму кластері. Два найбільш схожі випадки (ті, з найвищим виміряним показником подібності) потім об'єднуються в клас. Подібність цього нового класу з усіма іншими потім обчислюється на основі одного з трьох методів. На основі знову обчисленої матриці подібності процес об'єднання/перерахунку повторюється до тих пір, поки всі випадки не будуть «агломератовані» в єдиний кластер. «Ієрархічна» частина імені методу посилається на той факт, що як тільки випадок був об'єднаний в кластер, він ніколи не перекласифікується. Це призводить до кластерів збільшення розміру, які завжди охоплюють менші кластери.
Метод «Average» обчислює схожість середніх балів у новоутвореному кластері з усіма іншими кластерами; метод «Single-Link» (він же «найближчий сусід») обчислює подібність на основі подібності члена нового кластера, який найбільш схожий один на одного випадку не в кластер. Метод «Complete-Link» (він же «найдальший сусід») обчислює подібність між членом нового кластера, який найменш схожий один на одного випадку не в кластері. Метод за замовчуванням полягає у використанні середнього кластера; методи з одним зв'язком, як правило, дають довгі, стрункі схеми приєднання; методи повного зв'язку, як правило, дають сильно відокремлені схеми приєднання.
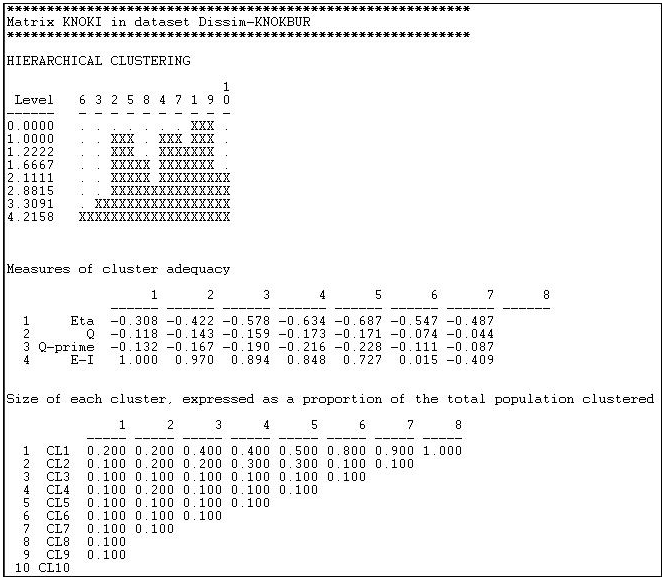
Відстань Хеммінга при надсиланні інформації в мережі Knoke обчислювалася, як показано у розділі вище, а результати зберігалися у вигляді файлу. Потім цей файл був введений в Інструменти>Кластер> Ієрархічний. Ми уточнили, що «середній» метод повинен бути використаний, і що дані були «несхожістю». Результати наведені на малюнку 13.9.
Малюнок 13.9: Кластеризація Хеммінгових відстаней передачі інформації в мережі Кноке
Перша графіка показує, що вузли 1 і 9 були найбільш схожими, і з'єдналися першими. Графіку, до речі, можна відтворити як більш відшліфовану дендограму за допомогою Інструменти>Дендограма>Малювати дані, збережені з інструмента кластера. На наступному етапі є три кластери (випадки 2 і 5, 4 і 7, а також 1 і 9). Приєднання триває до тих пір, поки (на\(^\text{th}\) кроці 8) всі випадки не агломеруються в єдине скупчення. Це дає чітку картину схожості випадків, і угруповань або класів справ. Але тут дійсно вісім картинок (по одній на кожен крок приєднання). Яке «правильне» рішення?
Знову ж таки, однозначної відповіді немає. Теорія та предметне знання процесів, що породжують дані, є найкращим керівництвом. Друга панель «Заходи кластерної адекватності» може надати певну допомогу. Тут є ряд індексів, і більшість (зазвичай) дадуть подібні відповіді. При русі справа (більш високі кроки або кількість агломерації) вліво (більше кластерів, менше агломерації) посадка поліпшується. Індекс E-I часто є найбільш корисним, оскільки він вимірює співвідношення кількості зв'язків всередині кластерів до зв'язків між кластерами. Як правило, мета полягає в тому, щоб досягти класів, які дуже схожі всередині, і досить чіткі без. Тут найбільше спокушає рішення 5\(^\text{th}\) кроку процесу (кластери 2+5, 4+7, 1+9, а інші - одноелементні кластери).
Щоб бути значущими, кластери також повинні містити розумний відсоток випадків. Остання панель показує інформацію про відносні розміри кластерів на кожному етапі. Маючи лише 10 випадків, які потрібно згрупувати в нашому прикладі, це не дуже просвітливо тут.
UCINET надає два додаткові інструменти кластерного аналізу, які ми не будемо обговорювати тут, але які ви, можливо, захочете вивчити. Інструменти>Кластер>Оптимізація дозволяє користувачеві апріорі вибрати ряд класів, а потім використовує обраний метод кластерного аналізу, щоб оптимально підігнати випадки до класів. Це дуже схоже на методику структурної оптимізації, про яку ми розповімо нижче. Інструменти>Кластер> Адекватність кластера приймає призначену користувачем класифікацію (розділ або файл атрибутів), підходить до даних до нього та повідомляє про правильність придатності.
Багатовимірні інструменти масштабування
Зазвичай нашою метою в аналізі еквівалентності є виявлення та візуалізація «класів» або кластерів випадків. Використовуючи кластерний аналіз, ми неявно припускаємо, що подібність або відстань між випадками відображається як єдиний базовий вимір. Однак можливо, що існує кілька «аспектів» або «розмірів», що лежать в основі спостережуваних подібностей випадків. Факторний або компонентний аналіз може бути застосований до кореляцій або коваріацій між випадками. Крім того, можна використовувати багатовимірне масштабування (неметричне для даних, які за своєю суттю є номінальними або порядковими; метричні для цінних).
MDS являє собою закономірності подібності або несхожості в профілі зв'язків між акторами (при застосуванні до суміжності або відстаней) як «карту» в багатовимірному просторі. Ця карта дозволяє нам побачити, наскільки «близькі» актори, чи вони «скупчуються» у багатовимірному просторі та скільки варіацій є уздовж кожного виміру.
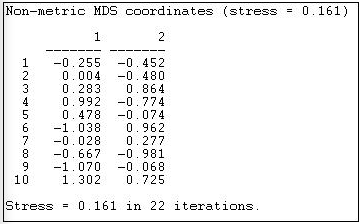
На малюнках 13.10 та 13.11 наведено результати застосування інструментів>MDS>неметричних MDS до необробленої матриці суміжності інформаційної мережі Кнока та вибору двовимірного рішення.
Малюнок 13.10: Неметричні двовимірні координати MDS інформаційної суміжності Кнока
«Стрес» - міра поганої форми. Використовуючи MDS, непогано подивитися на ряд рішень з більшими розмірами, щоб ви могли оцінити, наскільки відстані є одновимірними. Координати показують розташування кожного випадку (від 1 до 10) на кожному з вимірів. Перший випадок, наприклад, знаходиться в нижньому лівому квадранті, маючи негативні оцінки як на вимірі 1, так і на вимірі 2.
«Значення» розмірів іноді можна оцінити, порівнюючи випадки, які знаходяться на крайніх полюсах кожного виміру. Чи є організації на одному полюсі «публічними», а ті на іншому «приватними»? Аналізуючи дані соціальних мереж, не є незвичайним для першого виміру просто кількість з'єднання або ступінь вузлів.
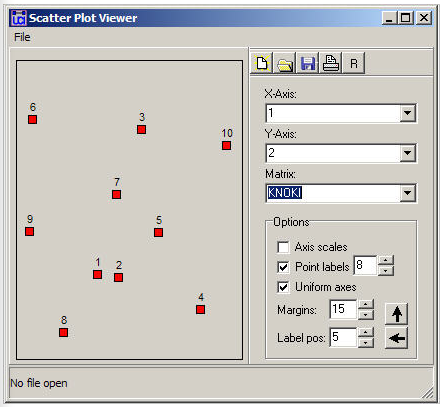
Малюнок 13.11: Двовимірна карта неметричної MDS інформаційної суміжності Кнока
Малюнок 13.11 відображає вузли відповідно до їх координатами. На цій карті ми шукаємо значущі тісні кластери точок для виявлення випадків, які дуже схожі за обома вимірами. У нашому прикладі такої подібності дуже мало (за винятком, мабуть, вузлів 1 і 2).
Інструменти кластеризації та масштабування можуть бути корисними у багатьох видах мережевого аналізу. Будь-яка міра відносин між вузлами може бути візуалізована за допомогою цих методів - найчастіше розглядається суміжність, сила, кореляція, відстань.
Ці інструменти також досить корисні для вивчення еквівалентності. Більшість методів оцінки еквівалентності генерують акторні міри близькості або подібності в профілі зв'язків (використовуючи різні правила, залежно від того, який тип еквівалентності ми намагаємося виміряти). Кластер та MDS часто дуже корисні для розуміння результатів.