13.2: Вимірювання подібності/несхожості
- Page ID
- 67427
Ми можемо спробувати оцінити, які вузли найбільш схожі на інші вузли інтуїтивно, дивлячись на графік. Ми помітили б деякі важливі речі. Здавалося б, актори 2, 5 і 7 можуть бути структурно схожі тим, що начебто мають взаємні зв'язки один з одним і майже з усіма іншими. Актори 6, 8 і 10 «регулярно» схожі тим, що вони досить ізольовані, але структурно не схожі, оскільки пов'язані з абсолютно різними наборами акторів. Але, крім цього, дійсно досить важко оцінити еквівалентність суворо, просто дивлячись на діаграму.
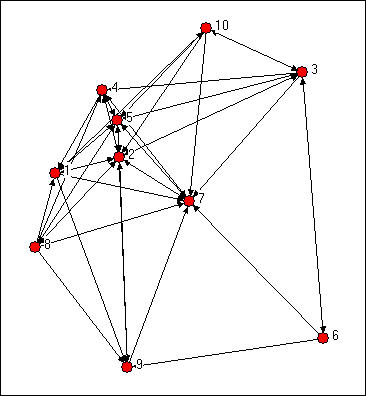
Малюнок 13.1: Інформаційна мережа, спрямована Knoke
Ми можемо бути набагато більш точними в оцінці подібності, якщо використовувати матричне представлення мережі замість діаграми. Це також дозволяє нам використовувати комп'ютер для виконання деяких досить нудних робіт, пов'язаних з обчисленням індексних чисел для оцінки подібності. Оригінальна матриця даних була відтворена нижче, як малюнок 13.2. Багато особливостей, які були очевидні на схемі, також легко зрозуміти в матриці. Якщо ми подивимось на рядки і відраховувати-градуси, і якщо ми подивимося вниз стовпці (для підрахунку в градусі), ми можемо побачити, хто центральні актори і хто є ізолятами. Але, ще більш загалом, ми можемо бачити, що два суб'єкти структурно еквівалентні в тій мірі, в якій профіль балів у їх рядках і стовпцях аналогічний. Знайти автоморфну еквівалентність і регулярну еквівалентність не так вже й просто. Але, оскільки ці інші форми менш обмежувальні (а отже, і спрощення структурних класів), ми починаємо з вимірювання того, наскільки схожі зв'язки кожного актора з усіма іншими суб'єктами.
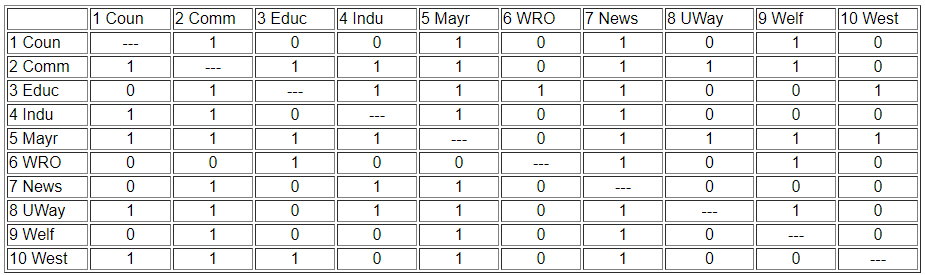
Малюнок 13.2: Матриця суміжності інформаційної мережі Knoke
Можна сказати, що два актори структурно еквівалентні, якщо вони мають однакові моделі зв'язків з іншими акторами. Це означає, що записи в рядках і стовпцях для одного актора ідентичні записам іншого. Якби матриця була симетричною, нам потрібно було б лише сканувати пари рядків (або стовпців). Але, оскільки ці дані стосуються спрямованих зв'язків, ми повинні вивчити схожість відправки та отримання зв'язків (звичайно, нас може зацікавити структурна еквівалентність стосовно тільки відправки або тільки отримання зв'язків). Ми можемо побачити подібність акторів, якщо ми розгорнемо матрицю на малюнку 13.2, перерахувавши вектори рядків, а потім вектори стовпців для кожного актора як один стовпець, як ми маємо на малюнку 13.3.

Малюнок 13.3: Конкатеновані суміжні рядки та стовпців для інформаційної мережі Knoke
Зв'язки кожного актора (як в, так і поза) тепер представлені у вигляді стовпця даних. Тепер ми можемо виміряти подібність кожної пари стовпців, щоб індексувати подібність двох акторів, утворюючи попарну матрицю подібності. Ми також могли б отримати ту ж ідею в зворотному напрямку, індексувавши несхожість або «відстань» між балами в будь-яких двох стовпцях.
Існує будь-яка кількість способів індексувати схожість і відстань. У наступних двох розділах ми коротко розглянемо найбільш часто використовувані підходи, коли зв'язки вимірюються як значення (тобто міцність або вартість або ймовірність) і як двійкові.
Мета тут полягає в тому, щоб створити акторну матрицю мір подібності (або відстані). Після того, як ми це зробили, ми можемо застосувати інші прийоми для візуалізації подібності акторських моделей відносин з іншими акторами.
Цінні відносини
Загальним підходом для індексації подібності двох значущих змінних є ступінь лінійної асоціації між ними. Точно такий же підхід може бути застосований і до векторів, які описують сильні сторони відносин двох акторів з усіма іншими суб'єктами. Як і будь-які заходи лінійної асоціації, лінійність є ключовим припущенням. Часто розумно, навіть коли дані знаходяться на рівні інтервалу (наприклад, обсяг торгівлі від однієї нації до всіх інших) розглядати заходи зі слабшими припущеннями (наприклад, заходи асоціації, призначені для порядкових змінних).
Коефіцієнти кореляції Пірсона, коваріації та крос-добуток
Кореляційна міра подібності особливо корисна, коли дані про зв'язки «цінуються», тобто розповідають про силу і напрямок асоціації, а не просту присутність або відсутність. Кореляції Пірсона варіюються від -1,00 (це означає, що два актори мають абсолютно протилежні зв'язки один з одним), через нуль (це означає, що знання зв'язки одного актора з третьою стороною не допомагає нам взагалі здогадуватися, що може бути зв'язок іншого актора до третьої сторони), до+1,00 (це означає, що два актори завжди мати точно такий же зв'язок з іншими дійовими особами - ідеальна еквівалентність). Кореляції Пірсона часто використовуються для узагальнення попарної структурної еквівалентності, оскільки статистика (звана «маленьким r») широко використовується в соціальній статистиці. Якщо дані про зв'язки дійсно номінальні, або якщо щільність дуже висока або дуже низька, кореляції іноді можуть бути трохи клопіткими, і збіги (див. Нижче) також слід вивчити. Різні статистичні дані, однак, зазвичай дають дуже однакові відповіді. На малюнку 13.4 показані кореляції десяти профілів організації Knoke щодо вхідних та вихідних інформаційних зв'язків. Ми застосовуємо кореляцію, хоча дані Knoke є двійковими. Алгоритм UCINET Інструменти>Подібності буде обчислювати кореляції для рядків або стовпців.
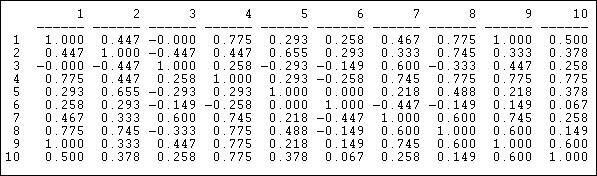
Малюнок 13.4: Пірсонові кореляції рядків (відправки) для інформаційної мережі Knoke
Ми бачимо, наприклад, що вузол 1 і вузол 9 мають однакові візерунки зв'язків; існує помірно сильна тенденція актора 6 мати зв'язки з акторами, яких актор 7 не робить, і навпаки.
Міра кореляції Пірсона не звертає уваги на загальну поширеність зв'язків (середнє значення рядка або стовпця), і вона не звертає уваги на відмінності між акторами в розбіжностях їх зв'язків. Часто це бажано - орієнтуватися тільки на закономірність, а не середнє значення і дисперсію як аспекти подібності між дійовими особами.
Часто, однак, ми можемо хотіти, щоб наша міра подібності відображала не лише візерунок зв'язків, але й відмінності між акторами у їх загальній щільності зв'язків. Інструменти> Подібності також обчислить матрицю коваріації. Якщо ми хочемо включити відмінності в відхиленнях між суб'єктами як аспекти (dis) подібності, а також засоби, може бути використано співвідношення перехресних продуктів, розраховане в Інструменти> Схожість.
Евклідова, Манхеттенська та квадратна відстань
Альтернативним підходом до лінійної кореляції (та її родичів) є вимірювання «відстані» або «несхожості» між профілями зв'язків кожної пари акторів. Кілька заходів «відстані» досить часто використовуються в мережевому аналізі, зокрема евклідова відстань або квадратна евклідова відстань. Ці заходи не чутливі до лінійності асоціації і можуть бути використані як з цінними, так і з двійковими даними.
На малюнку 13.5 показані евклідові відстані між організаціями Кнока, розраховані за допомогою Інструментів> Розбіжності та відстані> Розбіжності/відстані вектора Std.

Малюнок 13.5: Евклідові відстані при відправці для інформаційної мережі Knoke
Евклідова відстань між двома векторами дорівнює квадратному кореню суми квадратних відмінностей між ними. Тобто сила прив'язки актора А до С віднімається від сили краватки актора Б до С, а різниця - в квадрат. Потім це повторюється у всіх інших дійових осіб (D, E, F тощо) та підсумовується. Потім береться квадратний корінь суми.
Тісно пов'язаною мірою є «Манхеттен» або блокова відстань між двома векторами. Ця відстань - це просто сума абсолютної різниці між зв'язками актора до кожного альтера, підсумована поперек змін.
Двійкові відносини
Якщо інформація, яку ми маємо про зв'язки між нашими акторами, є двійковою, можна використовувати кореляційні та дистанційні заходи, але можуть бути не оптимальними. Для даних, які є двійковими, частіше дивитися на вектори двох акторських зв'язків, і подивитися, наскільки тісно записи в одному «збігаються» записи в іншому.
Існує кілька корисних показників схожості профілю стяжки на основі ідеї відповідності, які обчислюються інструментами> подібності.
Матчі: Точний, Жаккар, Хеммінг
Дуже простий і часто ефективний підхід до вимірювання подібності двох профілів зв'язків полягає в тому, щоб підрахувати кількість разів, коли краватка актора А змінити, така ж, як зв'язок актора Б, щоб змінити, і висловити це у відсотках від можливої загальної суми.
На малюнку 13.6 показаний результат зв'язку стовпців (отримання інформації) бюрократії Кноке.
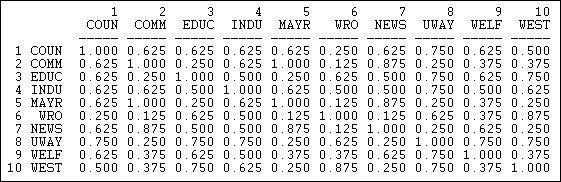
Малюнок 13.6: Частка збігів для отримання інформації Knoke
Ці результати показують схожість таким чином, який досить легко інтерпретувати. Число 0.625 у клітинці 2,1 означає, що, порівнюючи актора #1 та #2, вони мають однакову зв'язок (присутній або відсутній) з іншими акторами\(62.5\%\) того часу. Цей захід особливо корисний для багатокатегорійних номінальних мір зв'язків; він також забезпечує приємне масштабування двійкових даних.
У деяких мережах з'єднання дуже розріджені. Дійсно, якби розглядати зв'язки особистого знайомства в дуже великих організаціях, дані могли б мати дуже низьку щільність. Там, де щільність дуже низька, «збіги», «кореляція» та «відстань» заходи можуть показувати відносно невеликі варіації серед акторів і можуть спричинити труднощі у розрізненні наборів структурної еквівалентності (звичайно, у дуже великих мережах низької щільності справді може бути дуже низькі рівні структурних еквівалентність).
Одним із підходів до вирішення цієї проблеми є обчислення кількості разів, коли обидва суб'єкти повідомляють про краватку (або один і той же тип краватки) тим же третім суб'єктам у відсотках від загальної кількості зв'язків, про які повідомляється. Тобто ми ігноруємо випадки, коли ні X, ні Y не прив'язані до Z, і запитуємо, із загальної кількості зв'язків, які присутні, який відсоток є спільним. На малюнку 13.7 показані коефіцієнти Жаккарда для отримання інформації в мережі Knoke, розраховані за допомогою інструментів> подібності та вибору «Jaccard».
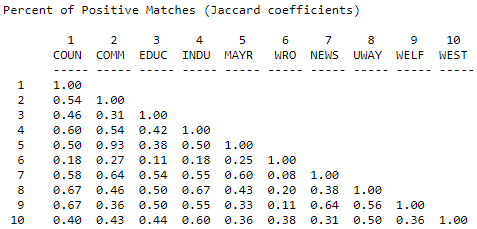
Малюнок 13.7: Коефіцієнти Жаккарда для профілів прийому інформації в мережі Knoke
Знову вимальовується та ж основна картина. Унікальність актора #6, правда, підкреслюється. Актор 6 більш унікальний за цим показником через відносно невеликої кількості загальних зв'язків, які він має - це призводить до більш низького рівня схожості, коли ігнорується «спільна відсутність» зв'язків. Там, де дані розріджені, і де є дуже істотні відмінності в ступенях точок, позитивний коефіцієнт відповідності є хорошим вибором для двійкових або номінальних даних.
Ще однією цікавою мірою «відповідності» є відстань Хеммінга, показана на малюнку 13.8.
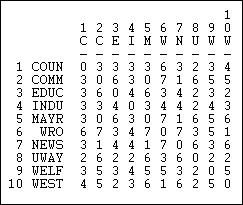
Малюнок 13.8: Відстані Хеммінга при отриманні інформації в мережі Кноке
Відстань Хеммінга - це кількість записів у векторі для одного актора, які потрібно було б змінити, щоб зробити його ідентичним вектору іншого актора. Ці відмінності можуть бути як додаванням, так і скиданням краватки, тому відстань Хеммінга розглядає відсутність суглобів як схожість.
При деякій винахідливості, напевно, можна придумати якісь інші розумні способи індексації ступеня структурної подібності між акторами. Ви можете подивитися на програму «Близькість» від SPSSx, яка пропонує велику колекцію мірок подібності. Вибір міри повинен керуватися концептуальним поняттям «як щодо», подібність двох профілів стяжки є найбільш важливою для цілей конкретного аналізу. Часто, чесно кажучи, це мало різниці, але це навряд чи є достатніми підставами ігнорувати це питання.