3.5: Секвенування білка, пептидне картографування, синтетичні гени
- Page ID
- 7459

Історично склалося так, що деякі важливі захворювання стани були визначені як викликані нестачею важливого білка, або наявністю дисфункціональної мутованої форми білка.
- Наприклад, діабет, типи карликовості та гемофілії були виявлені через дефіцит інсуліну, гормону росту та фактора згортання крові VIII відповідно.
Ці захворювання можна лікувати шляхом введення додаткових доз очищених або частково очищених препаратів цих білків.
- Ці білки були виділені з природних матеріалів, наприклад свиня (інсулін), людський трупний гіпофіз (гормон росту людини) або фракції крові об'єднані від нормальних донорів (фактор VIII).
- У більшості випадків, навіть якщо білок був виявлений у відносно рясному постачанні, собівартість виробництва була істотною.
Найчастіше цікаві біологічно активні властивості були пов'язані з білками, які можна було виділити лише в незначних кількостях (наприклад, активатор плазміногену, що розчиняє згусток крові, що розчиняє білкову тканину).
Крім того, нелюдські білки зазвичай викликали імунну відповідь при введенні в організм людини, таким чином людська форма білка була єдиною корисною формою.
- Якби білок не був легко доступний з крові або сечі, було б недоцільно отримувати достатню вихідну речовину для виробництва.
- На жаль, якщо матеріал був отриманий з людських джерел, існувала можливість поширення захворювань людини (наприклад, гепатиту та вірусу СНІДу).
Якби генетичну інформацію для цих білків можна було б виділити, а потім транскрибувати та перекласти в легко масштабовану біологічну систему, потенційно велику кількість білка можна було б отримати - і, сподіваємось, відносно дешево.
З розвитком «молекулярної біології», тобто
- будова ДНК,
- з'ясування генетичного коду,
- виявлення транскрипційних промоторів і сайтів зв'язування рибосом,
- виділення рестрикційних ендонукласів,
- ідентифікація походження реплікації ДНК
- розробка плазмід з вибірковими маркерами, і
- культивування кишкової палички,
можливість існувала в середині 1970-х років, щоб зібрати все це разом і виробляти відносно велику кількість будь-якого людського білка для терапевтичного використання.
Як би ви йшли про процес виробництва великої кількості якогось важливого людського білка? (Тобто очищення білка)
Відправною точкою, як правило, є аналіз на функціональність, що цікавить. Наприклад, у нас може бути гемофілія, кров якого не згортається. Однак ми виявляємо, що якщо взяти зразок його крові і додати до нього невелику кількість крові від «нормальної» особини, кров гемофілії тепер згорнеться. Це і буде основою для нашого аналізу.
Використовуючи цей аналіз, ми будемо фракціонувати нормальну кров за допомогою різних засобів - хімічного осадження (з етанолом, або сульфатом амонію), а потім різні етапи рідинної хроматографії і т.д.
- По дорозі ми будемо стежити, куди йде наша діяльність по згортанню.
- Сподіваємось, в якийсь момент ми не зможемо його далі фракціонувати і матимемо чистий білок.
Як тільки у нас є чистий білок, ми можемо почати характеризувати його щодо його амінокислотної послідовності. Звідти ми зрештою можемо отримати ген для білка і експресувати його.
.png)
Малюнок 3.5.1: Виробництво білка
N-термінальний аналіз пептидної послідовності
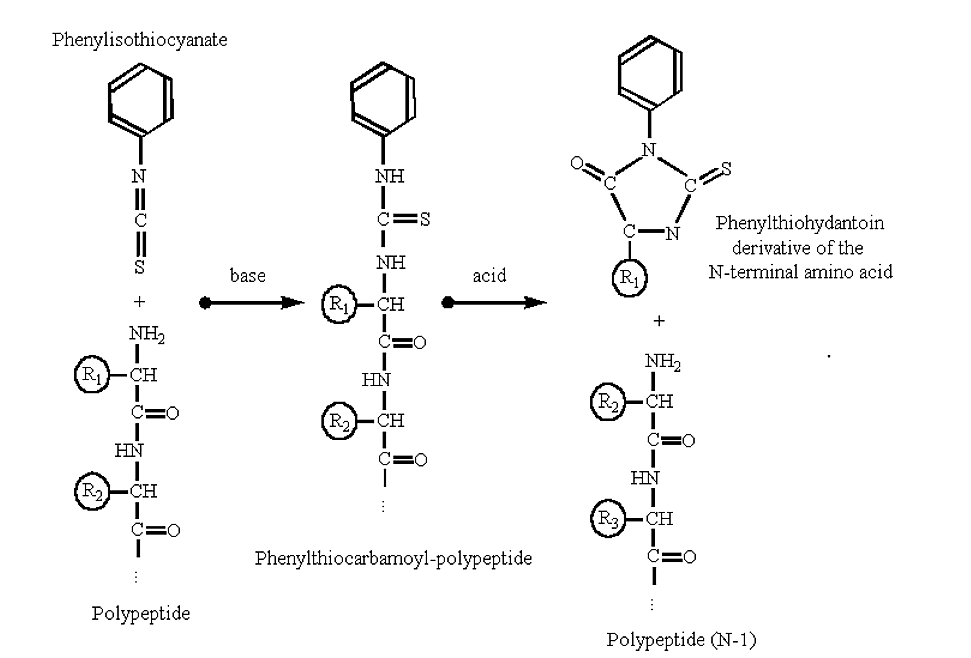
Поліпептиди можуть бути секвеновані з їх аміно-терміналу автоматизованими процедурами, заснованими на реакції деградації Едмана:
.png)
Малюнок 3.5.2: Деградація Едмана
- Зверніть увагу, що при хімії Едмана тільки N-кінцевий залишок атакується і видаляється, решта поліпептиду залишається недоторканою після реакції.
- Нова амінотермінальна група (раніше друга амінокислота в поліпептидному ланцюзі) тепер доступна для іншого раунду реакцій. Таким чином, метод можна автоматизувати.
- Бічний ланцюг амінокислот похідного фенілтіогіддантоїну можна ідентифікувати за допомогою рідинної хроматографії. Сучасні секвенсори амінокислот можуть, ймовірно, послідовність на порядку двох-трьох десятків циклів (амінокислот) поліпептиду.
- Зверніть увагу, що для реакції потрібна вільна аміногрупа на N-терміналі білка. Якщо аміно-термінальний залишок метильований або формульований, реакція не буде протікати (і поліпептид, як кажуть, має «заблокований» N-термінал).
С-термінальний аналіз пептидної послідовності
С-термінальний аналіз пептидної послідовності не так добре розроблений, як амінотермінальний аналіз.
- Метод зазвичай використовує неспецифічні карбоксипептидази.
- Карбоксипептидази будуть послідовно гідролізувати поліпептиди з карбокси-кінцевого кінця. Вивільнену амінокислоту можна ідентифікувати за допомогою рідинних хроматографічних методів, а залишився поліпептид доступний для подальших реакцій.
- Випускаються різні карбоксипептидази, зазвичай вони не зовсім неспецифічні (тобто мають певні переваги):
|
Ім'я |
Джерело |
специфіка |
|
Карбоксипептидаза А |
Бичача підшлункова залоза |
Ароматика, аліфатика (гідрофобіка) |
|
Карбоксипептидаза B |
Свиня підшлункова |
Аргінін, Лізин, Орнітин |
|
Карбоксипептидаза P |
Пеніциліум |
Як правило, неспецифічні |
|
Карбоксипептидаза Y |
Дріжджі |
Ароматичні, аліфатичні |
Іноді вибір того, яку карбоксипептидазу використовувати, грунтується на очікуваної інформації про послідовність. У таких видах експериментів:
- проби беруться в різні моменти часу в процесі травлення
- вільні амінокислоти відокремлюються від поліпептидів
- вивільнені амінокислоти ідентифікуються за допомогою амінокислотного аналізу (рідинної хроматографії).
C-термінальний аналіз, як правило, тільки точний для ідентифікації останніх півдюжини залишків або близько того в поліпептиді.
Пептидне картування
Однією з очевидних проблем секвенування білка є те, що навіть якщо N-термінал не «заблокований», з інтактного поліпептиду можна отримати лише інформацію обмеженої послідовності (тобто лише близько двох десятків з N-терміналу і півдюжини з C-терміналу).
Як можна отримати інформацію про послідовність для всього поліпептиду?
Одним із методів є пептидне картографування. Пептидне картування використовує протеолітичні розщеплення поліпептиду для отримання менших поліпептидів. Потім ці менші поліпептиди можуть бути ізольовані один від одного і підлягають послідовному аналізу.
Як ми впорядковуємо різні послідовності, які ми отримуємо?
Один з найпростіших способів - повторити експеримент, але з протеазою з іншою специфікою, і таким чином отримати перекривається інформацію послідовності.
|
Ім'я |
Джерело |
специфіка |
|
Хімотрипсин |
Бичача підшлункова залоза |
Розщеплення після Tyr, Phe і Trp; деяке розщеплення після Леу, Мет і Ала |
|
Бромелайн |
Ананас |
Розщеплення після Ліса, Али і Тира |
|
Трипсин |
Бичача підшлункова залоза |
Розщеплення після Arg, менше після Lys |
|
Протеаза V8 |
Золотистий стафілокок |
Розщеплення після Glu, менше після жереха |
.png)
Малюнок 3.5.3: Перекриваються продукти відколу
Інформація про послідовність перекриття може дозволити вирівняти пептиди в правильному порядку і визначити послідовність вихідного великого поліпептиду (тобто білка).
Одна з проблем, яка може виникнути, стосується залишків цистеїну та природи будь-яких ковалентних дисульфідних мостів у білку.
- Будь-які «пептидні» рухливості (на рідинних хроматографічних або PAGE аналізах), які розщеплюються на два менших пептиди після обробки відновником (наприклад, b -ME) вказують на наявність дисульфідної зв'язку, опосередкованої цистеїном.
- При секвенуванні цих пептидів кожен повинен містити залишок цистеїну. Якщо кожен пептид має тільки один цистеїн, то призначення дисульфідного зв'язку однозначне.
.png)
Малюнок 3.5.4: Залишки цистеїну в продуктах розщеплення
Відповідна генетична інформація
Після того, як ми отримаємо часткову або повну інформацію про послідовність пептидів, ми можемо почати ідентифікувати та ізолювати відповідну генетичну інформацію. Це і є головною метою. Після того, як ми отримаємо відповідну генетичну інформацію, можливо, можна виробляти відносно велику кількість потрібного поліпептиду.
Назад переклад
Оскільки ми знаємо генетичний код, ми можемо назад перевести будь-яку поліпептидну послідовність у відповідну генетичну послідовність.
- Таким чином, з амінокислотної послідовності ми могли б синтезувати штучний ген, який би кодував білок, що цікавить.
- Оскільки багато амінокислот кодуються більш ніж одним кодоном, існує потенційна неоднозначність щодо вихідної точної генетичної послідовності.
|
Амінокислота |
Кількість кодонів |
|
Метро, Трап |
1 |
|
Тех, Тир, Гіс, Глен, Дупу, Ліги, Жасп, Глю, Кішки |
2 |
|
Іль |
3 |
|
Вал, Про, Чт, Ала, Глі |
4 |
|
Лей, Арг, Сер |
6 |
Однак переконавшись, що ми знову перекладаємо таким чином, щоб вірно дублювати вихідну генетичну послідовність, може бути не критичним - правильна білкова послідовність є загальною метою.
Насправді, якщо ми намагаємося експресувати білок в іншому організмі (скажімо, експресуючи ген ссавців у бактеріальній системі), ми можемо насправді віддати перевагу вибору кодонового зміщення, відповідного організму господаря експресії.
Синтетичні гени для дрібних білків є розумним способом діяти; це один із способів експресії людського інсуліну в бактеріальних системах.
- Однак автоматизований синтез олігонуклеотидів ДНК практичний для полімерів довжиною приблизно 60-90 основ або менше (близько 20-30 амінокислот).
- Крім того, метод побудови синтетичних генів зазвичай вимагає перекриття комплементарних олігонуклеотидів (для лігування в одну дуплексну ДНК гена «касету»).
Таким чином, багато олігонуклеотиди потрібні навіть для одного невеликого синтетичного гена.
.png)
Малюнок 3.5.5: Синтетична побудова генів
Одним із способів вдосконалення вищезгаданого методу побудови синтетичних генів є прямий підхід ПЛР. Цей метод не використовує лігази, або навіть олігонуклеотиди, які стикуються разом. Натомість за допомогою цього методу багато (~ 100) різних перекриваються олігонуклеотидів одночасно використовуються в реакції ПЛР. Їх послідовність комплементарності можна представити наступним чином:

Весь набір олігонуклеотидів може не вибудовуватися, щоб дати весь ген, але це добре. Ми зробимо кілька раундів ПЛР з ідеєю, що деякі додаткові оліго відпалюватимуть та розширюватимуться і призведуть потроху до побудови суміжного синтетичного гена:
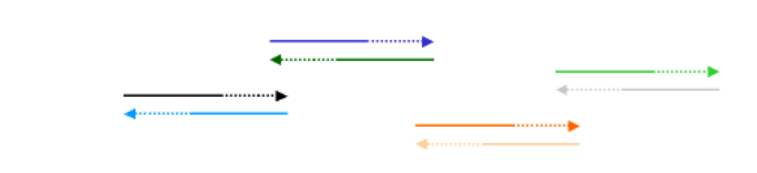
На наступному циклі ПЛР деякі з цих розширених фрагментів відпалять разом з іншими:
.png)
Вони будуть розширені за допомогою ПЛР і можуть переходити до відпалу з іншими більшими фрагментами ПЛР. Зрештою, весь ген буде побудований. Однак, оскільки ефективність побудови повнометражного гена, ймовірно, не буде дуже хорошою, нам потрібно провести наступний ПЛР-експеримент для ампліфікації гена повнометражного (з використанням зовнішніх праймерів). Принципові особливості цього методу узагальнюються наступним чином:
- Багато (цілих 1-2 сотні) перекриваються оліго поєднуються в одній реакції ПЛР
- Оліго розроблені таким чином, щоб бути якомога довше (~ 100 мерів) з обмеженим перекриттям (~ 20 основ)
- Повнометражний ген побудований в початковому (низьковрожайному) ПЛР-експерименті
- Цей ген повної довжини ампліфікується наступним типовим експериментом ПЛР з використанням зовнішніх праймерів.