2.2: Кількісна оцінка невизначеності за допомогою моделей ймовірності
- Page ID
- 13874
Цілі навчання
- У цьому розділі ви дізнаєтеся, як кількісно оцінити відносну частоту виникнення невизначених подій за допомогою моделей ймовірності.
- Ви дізнаєтеся про показники частоти, тяжкості, ймовірності, статистичних розподілів та очікуваних значень.
- Ви будете використовувати приклади для обчислення цих значень.
Розглядаючи невизначеність, ми використовуємо суворі кількісні дослідження випадковості, визнання її емпіричної закономірності в невизначених ситуаціях. Багато з цих методів використовуються для кількісної оцінки виникнення невизначених подій, які представляють інтелектуальні віхи. Коли ми створюємо моделі, засновані на ймовірності та статистиці, ви, швидше за все, визнаєте, що ймовірність та статистика стосуються майже кожної галузі дослідження сьогодні. Оскільки ми засвоїли прогностичну регулярність повторюваних випадкових подій, весь наш світогляд змінився. Наприклад, ми переконали себе в шансах отримати голови в монетному сальто настільки, що важко уявити інакше. Ми звикли бачити такі заяви, як «середній термін служби 1000 годин» на упаковці лампочок. Ми розуміємо таку фразу, тому що ми можемо думати про тривалість життя лампочки як невизначену, але статистично передбачувану. Ми регулярно чуємо такі заяви, як «Шанс на дощ завтра становить 20 відсотків». Нам важко уявити, що всього кілька століть тому люди не вірили навіть в існування випадкових явищ або випадкових подій або в аварії, а тим більше досліджували будь-який метод кількісної оцінки, здавалося б, випадкових подій. До недавнього часу люди вірили, що Бог контролював кожну хвилинну деталь Всесвіту. Це переконання виключає будь-який вид концептуалізації випадковості як регулярного або передбачуваного явища. Наприклад, до недавнього часу вартість покупки довічної ренти, яка платила покупцям 100 доларів на місяць на все життя, була такою ж для тридцятирічного віку, як і для сімдесятирічного. Неважливо, що емпірично «тривалість життя» тридцятирічного віку була в чотири рази довшою, ніж у сімдесятирічного віку. Наприклад, уряд Вільгельма III Англії запропонував ануїтети в розмірі 14 відсотків незалежно від того, чи був ануїтант 30 або 70 відсотків; (Карл Пірсон, Історія статистики У XVII-XVIII століттях на тлі зміни інтелектуальної, наукової та релігійної думки (Лондон: Charles Griffin & Co., 1978), с. 134. Адже люди вірили, що особливий час смерті людини - це «Божа воля». Ніхто не вірив, що тривалість чиєсь життя може бути оцінена або прогнозована статистично будь-якою поміченою або виставленою регулярністю між людьми. Незважаючи на досягнення в математиці та науці з початку цивілізації, що примітно, розробка заходів відносної частоти виникнення невизначених подій відбувалася лише в 1600-х роках. Це народження «сучасних» ідей випадковості відбулося, коли часто гравець поставив проблему математику Блезе Паскалю. Як часто виникає, проблема виявилася менш важливою в довгостроковій перспективі, ніж рішення, розроблене для вирішення проблеми.
Проблема полягала в тому, що якщо двоє людей грають в азартні ігри, і гра переривається і припиняється до того, як хтось із двох виграв, який справедливий спосіб розділити банк грошей на столі? Очевидно, що людина попереду в той час мав більше шансів на перемогу в грі і повинен був отримати більше. Гравець, який лідирує, отримає більшу частину банку грошей. Однак людина, яка програє, могла прийти ззаду і перемогти. Це могло статися і таку можливість виключати не варто. Як слід справедливо розділити горщик? Паскаль сформулював підхід до цієї проблеми і в серії листів з П'єром де Ферма розробив підхід до проблеми, який спричинив за собою записування всіх можливих результатів , які могли б статися, а потім підрахунок кількості разів, коли перший гравець виграв. Частка разів, коли перший гравець виграв (обчислюється як кількість разів виграв гравець, розділений на загальну кількість можливих результатів) була прийнята пропорцією банку, що перший гравець міг справедливо претендувати. У процесі формулювання цього рішення Паскаль і Ферма в цілому розробили основу для кількісної оцінки відносної частоти невизначених результатів, яка зараз відома як ймовірність. Вони створили математичне поняття очікуваної величини невизначеної події. Вони першими змоделювали виставлену закономірність випадковості чи невизначеності подій і застосували її для вирішення практичної проблеми. Фактично, їх рішення вказувало на багато інших потенційних застосувань проблем у сфері права, економіки та інших галузей.
З роботи Паскаля і Ферма стало зрозуміло, що для управління майбутніми ризиками в умовах невизначеності нам потрібно мати певне уявлення не тільки про можливі результати або стани світу, але і про те, наскільки ймовірним є кожен результат. Потрібна модель, або, іншими словами, символічне зображення можливих результатів і їх ймовірності або відносних частот.
Історична прелюдія до кількісної оцінки невизначеності через ймовірності
Історично розробка заходів випадковості (ймовірності) почалася лише в середині 1600-х років. Чому в середні віки, а не у греків? Відповідь, частково, полягає в тому, що греки і їх попередники не мали математичних понять. Також, що ще важливіше, греки не мали психологічної перспективи навіть споглядати ці поняття, а тим більше розвивати їх у переконливу теорію, здатну до відтворення та розширення. По-перше, греки не мали математичної системи позначення, необхідної для споглядання формального підходу до ризику. Їм не вистачало, наприклад, простої і повної символічної системи, що включає нуль і знак рівності, корисний для обчислень, внесок, який згодом був розроблений арабами і пізніше прийнятий західним світом. Використання римських цифр могло бути достатнім для підрахунку, і, можливо, достатнім для геометрії, але, безумовно, це не сприяло складним розрахункам. Знак рівності не був у загальному вживанні до пізнього середньовіччя. Уявіть, що ви робите обчислення (навіть такі прості обчислення, як ділення дробів або рішення рівняння) римськими цифрами без знака рівності, нульового елемента або десяткової крапки!
Але математики і вчені врегулювали ці перешкоди за тисячу років до появи ймовірності. Чому аналіз ризиків не з'явився з появою більш повної системи нумерації так само, як складні розрахунки в астрономії, техніці та фізиці? Відповідь є більш психологічною, ніж математичною, і лежить в основі того, чому ми розглядаємо ризик як психологічне, так і числове поняття в цій книзі. Грекам (і тисячоліттям інших, хто слідував за ними) небеса, божественно створені, вважалися статичними і досконалими і керувалися регулярністю та правилами досконалості - колами, сферами, шістьма досконалими геометричними твердими тілами тощо. Земна сфера, навпаки, була джерелом недосконалості і хаосу. Греки змирилися з тим, що не знайдуть сенсу вивчати хаотичні події Землі. Стародавні греки знайшли шлях до істини в спогляданні досконалості небес та інших досконалих незіпсованих або незіпсованих сутностей. Чому бог (або боги) достатньо потужний, щоб знати і створити все навмисно, створити світ, використовуючи менш досконалу модель? Греки та інші, хто слідував, вважали, що чисті міркування, а не емпіричні, спостереження призведуть до пізнання. Вивчення закономірності в хаотичній земній сфері було найгіршим, ніж марна трата часу; це відволікало увагу від важливих споглядань, які насправді можуть передати істинні знання.
Знадобилася кардинальна зміна мислення, щоб почати споглядати регулярність подій у земній області. Всі ми істоти нашого віку, і ми не могли поставити необхідні питання, щоб розвинути теорію ймовірності і ризику, поки не похитнули ці кайдани розуму. До епохи розуму, коли церковні реформи і зростаючий купецький клас (який прагматично розглядав і підраховував речі емпіричним шляхом) створили колосальне зростання торгівлі, ми залишалися в пастці старих способів мислення. Поки суспільство було статичним і стаціонарним, а села цього року були по суті такими ж, як і минулого року чи десятиліття чи століття до цього, було мало необхідності ставити або вирішувати ці проблеми. Кендалл фіксує це лаконічно, коли він зазначив, що «математика ніколи не веде думки, а лише висловлює її» * Західний світ просто ще не був готовий намагатися кількісно оцінити ризик або ймовірність подій (ймовірність) або споглядати невизначеність. Якщо всі речі, як вважають, керується всемогутнім богом, то регулярності не можна довіряти, можливо, це навіть можна вважати оманливим, а варіації не мають значення та ілюзорні, лише відображаючи Божу волю. Причому те, що такі речі, як кістки і малювання жеребків, одночасно використовувалися і магами, і азартними гравцями, і релігійними діячами для ворожіння, не давало ніякого поштовху до пошуку закономірності в земних починаннях.
* Кендалл М.Г., «Початок обчислення ймовірностей» в дослідженнях історії статистики та ймовірності, т. 1, під ред. Пірсон і сер Моріс Кендалл (Лондон: Charles Griffin & Co., 1970), 30.
Методи вимірювання частоти, тяжкості та розподілу ймовірностей для кількісної оцінки невизначених подій
Коли ми можемо побачити закономірність втрат та/або прибутків, зазнатих у минулому, ми сподіваємось, що та сама модель збережеться і в майбутньому. У деяких випадках ми хочемо мати можливість модифікувати минулі результати логічним чином, наприклад, завищувати їх на часову вартість грошей, обговорювану в «4: Еволюція управління ризиками - фундаментальні інструменти». Якщо закономірності прибутків і втрат продовжуватимуться, наші прогнози майбутніх втрат або прибутку будуть інформативними. Аналогічно, ми можемо розробити модель втрат на основі теоретичних або фізичних конструкцій ( наприклад, моделей прогнозування ураганів на основі фізики або ймовірності отримання голови в перевертанні монети на основі теоретичних моделей рівної ймовірності голови та хвоста). Імовірність - це поняття про те, як часто буде відбуватися певна подія. Неточності в наших здібностях створити правильний розподіл виникають через нашу нездатність точно передбачити ф'ючерсні результати. Розподіл - це відображення подій на карті, що говорить нам про ймовірність того, що подія або події відбуватимуться. У чомусь він нагадує картину ймовірності і регулярності подій, що відбуваються. Давайте тепер перейдемо до створення моделей і мірок результатів і їх частоти.
Заходи частоти та тяжкості
Таблиця 2.1 і таблиця 2.2 показують складання кількості претензій і їх доларових сум для будинків, які були спалені протягом п'ятирічного періоду в двох різних місцях з маркуванням Місцезнаходження A і Location B. У нас є інформація про загальну кількість претензій на рік і кількості пожежі. збитки в доларах за кожен рік. Кожне місце має однакову кількість будинків (1000 будинків). Кожне місце має загалом 51 претензію за п'ятирічний період, в середньому (або середнє) 10,2 претензії на рік, що є періодичністю. Середня доларова сума збитків за позовом за весь період також однакова для кожного місця, 6166.67 доларів, що є визначенням тяжкості.
| Рік | Кількість пожежних претензій | Кількість втрат від пожежі ($) | Середня втрата за претензію ($) |
|---|---|---|---|
| 1 | 11 | 16,500.00 | 1 500.00 |
| 2 | 9 | 40 000,00 | 4 444.44 |
| 3 | 7 | 30 000,00 | 4 285.71 |
| 4 | 10 | 123 000,00 | 12 300.00 |
| 5 | 14 | 105 000,00 | 7 500.00 |
| Всього | 51.00 | 314 500.00 | 6 166.67 |
| Середнє | 10.20 | 62 900.00 | 6 166.67 |
| Середня частота = | 10.20 | ||
| Середня тяжкість = | 6 166.67 за 5-річний період |
Таблиця 2.2 Претензії та втрати від пожежі ($) для будинків у розташуванні B
| Рік | Кількість пожежних претензій | Втрати від пожежі | Середня втрата за претензію ($) |
|---|---|---|---|
| 1 | 15 | 16,500.00 | 1 100.00 |
| 2 | 5 | 40 000,00 | 8 000.00 |
| 3 | 12 | 30 000,00 | 2 500.00 |
| 4 | 10 | 123 000,00 | 12 300.00 |
| 5 | 9 | 105 000,00 | 11 666,67 |
| Всього | 51.00 | 314 500.00 | 6 166.67 |
| Середнє | 10.20 | 62 900.00 | 6 166.67 |
| Середня частота = | 10.20 | ||
| Середня тяжкість = | 6 166.67 за 5-річний період |
Як показано в таблиці 2.1 та таблиці 2.2, загальна кількість вимог про пожежу для двох місць A та B однакова, як і загальна сума збитків у доларах. Можна згадати з раніше, кількість претензій на рік називається періодичністю. Середня частота претензій по місцях А і В становить 10,2 на рік. Розмір збитку в перерахунку на долари, втрачені за позовом, називають тяжкістю, як ми відзначали раніше. Середні долари, втрачені за заяву на рік у кожному місці, становить 6166.67 доларів.
Найважливішими заходами для ризик-менеджерів при вирішенні потенційних втрат, що виникають внаслідок невизначеності, зазвичай є заходи, пов'язані з частотою та серйозністю збитків протягом певного періоду часу. Використання даних про частоту та серйозність дуже важливо як для страховиків, так і для керівників фірм, які займаються оцінкою ризику різних починань. Менеджери ризиків намагаються використовувати діяльність (фізичне будівництво, резервні системи, фінансове хеджування, страхування тощо), щоб зменшити частоту або серйозність (або обидва) потенційних збитків. У розділі «4: Еволюція управління ризиками - основні інструменти» ми побачимо представлені дані про частоту та дані про серйозність. Як правило, ризик-менеджер пов'язує кількість інцидентів, що розслідуються, з базою, наприклад, кількість працівників, якщо вивчати частоту та тяжкість травм на робочому місці. У прикладах в таблиці 2.1 і таблиці 2.2 тяжкість пов'язана з кількістю пожежних претензій за п'ятирічний період на 1000 будинків. Важливо зазначити , що в цих таблицях точний розподіл (частоти та доларові втрати) протягом багатьох років для претензій на рік, що виникають у розташуванні А, відрізняється від розподілу для місцезнаходження Б. Це буде розглянуто далі в цьому розділі. Далі обговоримо поняття частоти з точки зору ймовірності або ймовірності.
Частота і ймовірність
Повертаючись до кількісної оцінки поняття невизначеності, ми спочатку спостерігаємо, що наше інтуїтивне використання слова ймовірність може мати два різних значення або форми, пов'язані з твердженнями невизначеності результатів. Це є прикладом двох різних тверджень:Див. Патрік Брокетт і Арнольд Левін Брокетт, Статистика, ймовірність і їх застосування (WB. Saunders Publishing Co., 1984), 62.
- «Якщо я пливу на захід від Європи, у мене є 50-відсотковий шанс, що я впаду з краю землі».
- «Якщо я переверну монету, у мене є 50-відсотковий шанс, що вона приземлиться на голови».
Концептуально вони представляють два різних типи тверджень ймовірності. Перший - це твердження про ймовірність як ступінь переконання про те, чи відбудеться подія і наскільки міцно тримається це переконання. Другий - це твердження про те, як часто голова буде очікувати, щоб з'являтися в повторних сальто монети. Важливою відмінністю є те, що буде викладено дійсність або правдивість першого твердження. Ми можемо прояснити правдивість заяви для всіх, плаваючи по всьому світу.
Друге твердження, однак, все ще залишається невирішеним. Навіть після першого перевертання монети у нас все ще є 50-відсотковий шанс, що наступний фліп призведе до голови. Другий передбачає різне тлумачення «ймовірності», а саме, як відносної частоти виникнення при повторних випробуваннях. Ця відносна частотна концептуалізація ймовірності є найбільш актуальною для управління ризиками. З минулих подій хочеться дізнатися про ймовірність майбутніх явищ. Першовідкривачі теорії ймовірностей прийняли відносно-частотний підхід до формалізації ймовірності випадкових подій.
Паскаль і Ферма відкрили великий концептуальний прорив: концепція, що в повторних азартних іграх (або в багатьох інших ситуаціях, що зустрічаються в природі), пов'язані з невизначеністю, виникли фіксовані відносні частоти виникнення окремих можливих результатів. Ці відносні частоти були стабільними протягом довгого часу, і люди могли обчислити їх, просто підрахувавши кількість способів, за якими може статися результат, розділений на загальну кількість однаково ймовірних можливих результатів. Крім того, емпірично відносна частота виникнення подій у довгій послідовності повторних випробувань (наприклад, повторних азартних ігор) відповідала теоретичному розрахунку кількості способів поділу події на загальну кількість можливих результатів. Це модель однаково ймовірних результатів або відносної частоти визначення ймовірності. Це був дуже виразний відхід від попередньої концептуалізації невизначеності, яка мала всі події, контрольовані Богом, без людського помітного зразка. У рамках Паскаль-Ферма передбачення стало питанням підрахунку, який може зробити будь-хто. Ймовірність і передбачення стали інструментом народу! На малюнку \(\PageIndex{1}\) наведено приклад, що представляє всі можливі результати кидка двох кольорових кубиків разом із пов'язаними з ними ймовірностями.
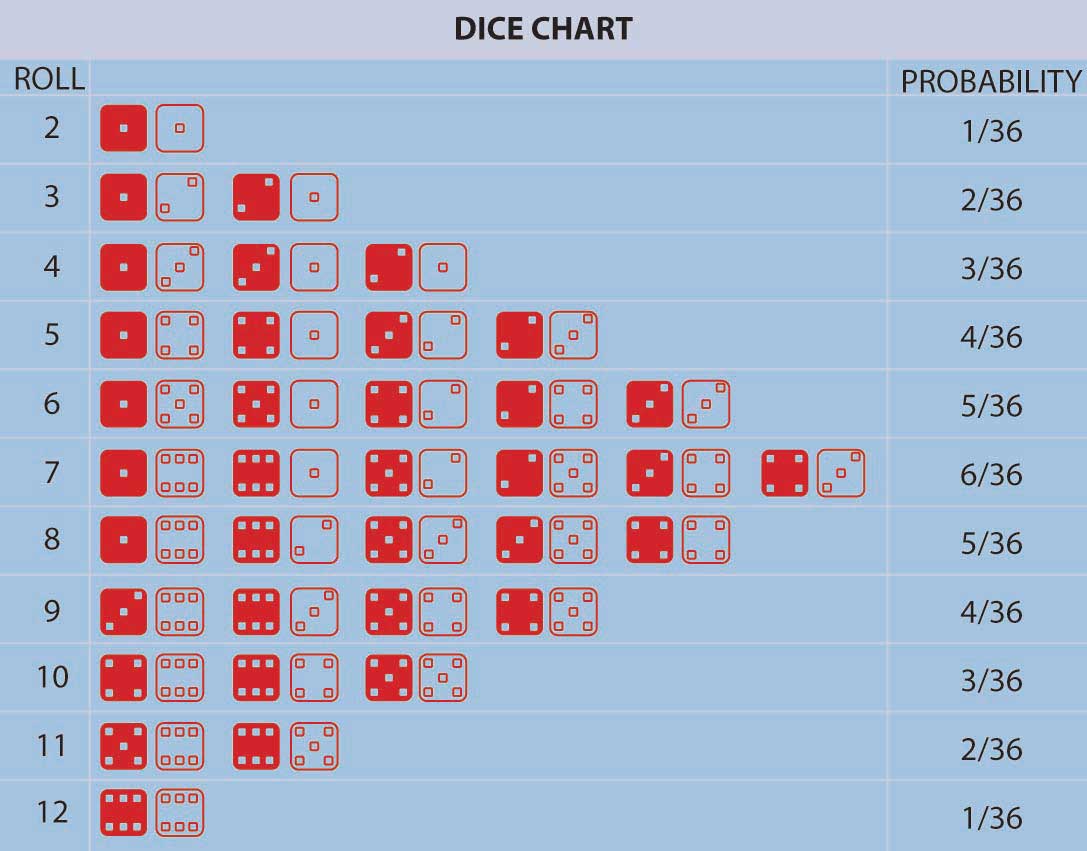
На малюнку\(\PageIndex{1}\) перераховані ймовірності кількості точок, звернених вгору (2, 3, 4 і т.д.) в рулоні двох кольорових кубиків. Ми можемо обчислити ймовірність для будь-якого з цих чисел (2, 3, 4 тощо) шляхом складання кількості результатів (кидків двох кубиків), які призводять до того, що ця кількість точок, звернених вгору, розділена на загальну кількість можливостей. Наприклад, кидок з тридцяти шести можливостей сумарно, коли ми кидаємо дві кістки (порахуємо їх). Імовірність прокатки 2 становить 1/36 (ми можемо кинути лише 2 в одну сторону, а саме, коли обидва кубики мають 1 обличчям вгору). Імовірність прокатки 7 дорівнює\(\frac{6}{36}\) =\(\frac{1}{6}\) (так як рулони можуть падати будь-яким з шести способів прокатки 7-1 і 6 двічі, 2 і 5 двічі, 3 і 4 двічі). Для будь-якого іншого вибору кількості точок, звернених вгору, ми можемо отримати ймовірність, просто додавши кількість способів поділу поділу на тридцять шість. Імовірність прокатки 7 або 11 (5 і 6 двічі) на кидок кістки, наприклад, дорівнює \(\frac{6+2}{36}\) =\(\frac{2}{9}\).
Поняття «однаково ймовірні результати» та обчислення ймовірностей як співвідношення «кількості способів, у яких може статися подія, розділене на загальну кількість однаково ймовірних результатів» є насіннєвими та повчальними. Але вона не включала ситуації, в яких кількість можливих результатів була (принаймні концептуально) необмеженою або нескінченною або не однаково ймовірною. Також логіка поняття однаково ймовірних результатів легко зрозуміла в той час. Наприклад, відомий математик Д'Аламбер допустив наступну помилку при обчисленні ймовірності появи голови двома сальто монети (Карл Пірсон, Історія статистики в XVII і XVIII століттях на мінливому тлі інтелектуального, наукового і релігійна думка [Лондон: Чарльз Гріффін і Ко, 1978], 552). Д'Аламберт сказав, що голова може підійти на першому сальто, що вирішить цю справу, або хвіст може підійти на першому сальто, а потім голова або хвіст на другому сальто. Є три результати, два з яких мають голову, і тому він стверджував, що ймовірність отримати голову в два сальто є\(\frac{2}{3}\). Очевидно, він не знайшов часу, щоб фактично перевернути монети, щоб побачити, що ймовірність була \(\frac{3}{4}\), оскільки можливі однаково ймовірні результати насправді (H, T), (H, H), (T, H), (T, T) з трьома парами сальто, що призводить до голови. Помилка полягає в тому, що результати, зазначені в рішенні Д'Аламбера, не однаково ймовірно, використовують його результати H, (T, H), (T, T), тому його знаменник неправильний. Мораль цієї історії полягає в тому, що постульовані теоретичні моделі завжди повинні бути перевірені на емпіричних даних, коли це можливо, щоб виявити будь-які можливі помилки. Нам знадобилося розширення. Помітивши, що ймовірність події, будь-якої події, за умови, що продовження. Крім того, розширення теорії до неоднаково ймовірних можливих результатів виникло , помітивши, що ймовірність події - будь-якої події - відбувається може бути розрахована як відносна частота події, що відбувається в тривалому періоді випробувань, в яких подія може відбутися або не відбутися. Таким чином, різні події могли мати різні, нерівні шанси відбутися при тривалому повторенні сценаріїв, пов'язаних з можливими виникненнями подій. У таблиці 2.3 наведено приклад цього. Ми можемо розширити теорію ще далі до ситуації, в якій кількість можливих результатів потенційно нескінченна. Але як щодо ситуації, в якій не можна легко визначити, пов'язану з кількістю можливих результатів? Ми можемо вирішити цю ситуацію, знову використовуючи відносну частотну інтерпретацію ймовірності, а також. Коли ми маємо континуум можливих результатів (наприклад, якщо результатом є час, ми можемо розглядати його як безперервний змінний результат), тоді створюється крива відносної частоти. Таким чином, ймовірність падіння результату між двома числами x і y є площею під частотною кривою між x і y. Загальна площа під кривою відображає, що це 100% впевнений, що відбудеться якийсь результат.
Так званий нормальний розподіл або дзвіноподібна крива зі статистики дає нам приклад такої безперервної кривої розподілу ймовірностей. Дзвоноподібна крива являє собою ситуацію, коли виникає континуум можливих результатів. Малюнок \(\PageIndex{2}\) надає таку дзвіноподібну криву для рентабельності реалізації нового науково-дослідного проекту. Вона може мати прибуток або збиток.
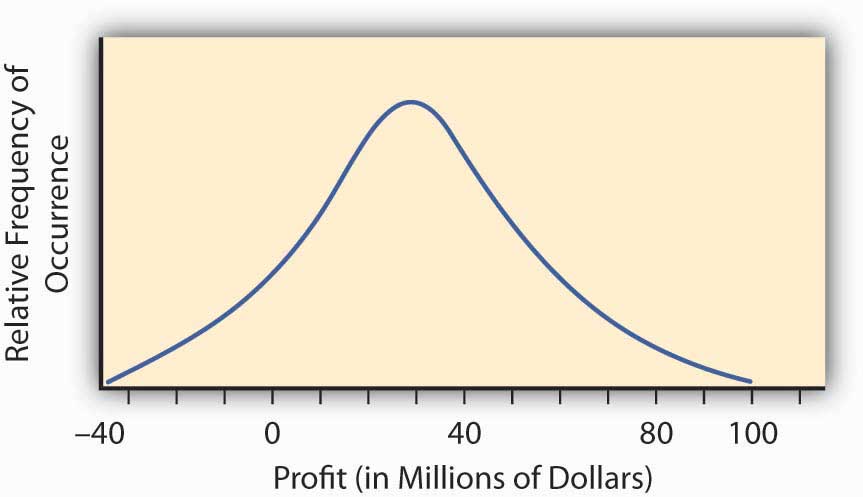
Щоб знайти ймовірність будь-якого діапазону значень рентабельності для цього науково-дослідного проекту, знаходимо площу під кривою на малюнку\(\PageIndex{2}\) між потрібним діапазоном значень рентабельності. Наприклад, розподіл на малюнку \(\PageIndex{2}\) був побудований так, щоб мати те, що називається нормальним розподілом з горбом над точкою 30 мільйонів доларів та мірою поширення 23 мільйони доларів. Цей спред являє собою стандартне відхилення, яке ми обговоримо в наступному розділі. Ми можемо обчислити площу під кривою вище $0, що буде ймовірність того, що ми отримаємо прибуток, реалізуючи науково-дослідний проект. Робимо це за посиланням на звичайну таблицю розподілу значень, наявну в будь-якій статистичній книзі. Площа під кривою становить 0,904, що означає, що ми маємо приблизно 90 відсотків зміни (ймовірність 0,9), що проект призведе до отримання прибутку.
На практиці ми будуємо таблиці розподілу ймовірностей або криві ймовірності, такі як на малюнку\(\PageIndex{1}\)\(\PageIndex{2}\), малюнку та таблиці 2.3, використовуючи оцінки ймовірності (ймовірності) різних станів природи на основі історичної відносної частоти виникнення або теоретичні дані. Наприклад, емпіричні дані можуть надходити з повторних спостережень в подібних ситуаціях, таких як з історично побудованими таблицями життя або смертності. Теоретичні дані можуть надходити з фізичної або інженерної оцінки ймовірності відмови для моста або судна зберігання атомної електростанції. Однак у деяких ситуаціях ми можемо визначити ймовірності суб'єктивно або за експертною думкою. Наприклад, оцінки політичних повалень урядів використовуються для ціноутворення страхування політичних ризиків, необхідних корпораціям, які ведуть бізнес на ринках, що розвиваються. Незалежно від джерела ймовірностей, ми можемо отримати оцінку ймовірностей або відносних частот майбутнього виникнення кожної мислимої події. Отримана сукупність можливих подій разом з відповідними ймовірностями виникнення називається розподілом ймовірностей, приклад якого наведено в таблиці 2.3.
Заходи значення результату: тяжкість втрати, значення виграшу
Ми розробили кількісну міру ймовірності різних невизначених результатів, з якими може зіткнутися фірма чи людина - їх також називають ймовірностями. Тепер ми можемо звернутися до вирішення наслідків невизначеності. Наслідки невизначеності найчастіше є життєво важливим питанням фінансово. Причиною того, що невизначеність викликає занепокоєння, є не сама невизначеність, а різні результати, які можуть вплинути на стратегічні плани, прибутковість, якість життя та інші важливі аспекти нашого життя або життєздатності компанії. Тому нам потрібно оцінити, як на нас впливають в кожному штаті світу. Для кожного результату ми пов'язуємо цінність, яка відображає те, як на нас впливає перебування в такому стані світу.
Як приклад розглянемо роздрібну фірму, яка виходить на новий ринок з новоствореним товаром. Вони можуть заробити багато грошей, скориставшись статусом «першого рушія». Вони можуть втратити гроші, якщо товар недостатньо прийнятий на ринку. Крім того, хоча вони намагалися передбачити будь-які проблеми, вони можуть зіткнутися з потенційною відповідальністю за продукт. Хоча вони, природно, намагаються зробити свою продукцію максимально безпечною, вони повинні враховувати потенційну відповідальність через обмежений досвід роботи з продуктом. Вони можуть оцінити ймовірність судового позову, а також наслідки (збитки), які можуть виникнути внаслідок необхідності захисту таких позовів. Невизначеність наслідків робить це зусилля ризикованим та потенціалом для отримання прибутку, що мотивує вихід компанії на новий ринок. Як розраховувати ці прибутки і збитки? Ми вже демонстрували деякі розрахунки на прикладах вище в таблиці 2.1 і таблиці 2.2 для претензій і пожежних втрат для будинків в місцях А і Б. Ці приклади зосереджені на наслідках невизначеності щодо пожеж. Інший спосіб обчислення однотипних наслідків наведено у прикладі в таблиці 2.3 для розподілу ймовірностей для цього нового виходу на ринок. Ми також шукаємо оцінку фінансових наслідків виходу на ринок. Цей приклад розглядає кілька можливих результатів, а не тільки результат пожежних втрат. Ці результати можуть мати позитивні або негативні наслідки. Тому тут ми використовуємо термінологію opportunity, а не тільки можливості втрати.
| Стан природи | Оцінка ймовірності стану | Фінансові наслідки перебування в цьому стані (у мільйоні доларів) |
|---|---|---|
| За умови втрати в позові про відповідальність за товар | .01 | −10.2 |
| Прийняття ринку обмежене та тимчасове | 1.0 | −.50 |
| Деяке прийняття на ринку, але немає великого споживчого попиту | 4.0 | 1.0 |
| Хороше прийняття на ринку та показники продажів | 4.0 | 1 |
| Великий попит на ринку та показники продажів | .09 | 8 |
Як бачите, не невизначеність самих держав змушує осіб, які приймають рішення, замислюватися над доцільністю виходу на ринок нового продукту. Це наслідки різних результатів, які викликають роздуми. Фірма може втратити 10,2 мільйона доларів або отримати 8 мільйонів доларів. Якби ми знали, яка держава здійсниться, рішення було б простим. Питання про те, як ми поєднуємо оцінку ймовірності зі значенням виграшу або збитку з метою оцінки ризику (наслідків невизначеності) в наступному розділі.
Поєднання ймовірності та значення результату разом, щоб отримати загальну оцінку впливу невизначеного зусилля
Розробники ранніх ймовірностей запитали, як ми можемо об'єднати різні ймовірності та значення результатів разом, щоб отримати єдине число, що відображає «значення» безлічі різних результатів та різних наслідків цих результатів. Вони хотіли єдине число, яке певним чином узагальнювало весь розподіл ймовірностей. У контексті азартних ігор того часу, коли результати були сума, яку ви виграли в кожному потенційному невизначеному стані світу, вони стверджували, що це значення було «справедливою вартістю» азартної гри. Ми визначаємо справедливу вартість як числове середнє значення досвіду всіх можливих результатів, якщо ви грали в гру знову і знову. Це ще називають «очікуваним значенням». Очікуване значення обчислюється шляхом множення кожної ймовірності (або відносної частоти) на відповідний коефіцієнт посилення або втрати.У деякому роді соромно, що термін «очікуване значення» був використаний для опису цього поняття. Кращим терміном є « середнє значення в довгостроковій перспективі» або «середнє значення», оскільки цього конкретного значення насправді не слід очікувати в будь-якому реальному сенсі і може навіть не бути можливістю (наприклад, значення, розраховане з таблиці 2.3, є 1.008, що навіть не є можливістю). Тим не менш, ми застрягли з цією термінологією, і вона передає деяке уявлення про те, що ми маємо на увазі до тих пір, поки ми інтерпретували це як число, очікуване як середнє значення в довгій серії повторень оцінюваного сценарію. Його також називають середнім значенням, або середнім значенням. Якщо X позначає значення, яке призводить до невизначеної ситуації, то очікуване значення (або середнє значення або середнє значення) часто позначається\(E(X)\), іноді також називають економістами як\(E(U)\) - очікувана корисність - і\(E(G)\) - очікуваний виграш. У довгостроковій перспективі загальна втрата або виграш, поділена на кількість повторних випробувань, буде сумою ймовірностей, що перевищує досвід у кожному штаті. У таблиці 2.3 очікуване значення дорівнює\ ((.01) × (—10,2) + (.1) × (−.50) + (.4) × (.1) + (.4) × (1) + (.09) × (8) = 1,008\). Таким чином, ми б сказали, що очікуваний результат невизначеної ситуації, описаної в таблиці 2.3, становив 1,008 мільйона доларів, або 1 008 000,00 доларів. Аналогічно, очікуване значення кількості точок на киданні пари кубиків, розраховане на прикладі на малюнку,\(\PageIndex{1}\) становить\ (2× ((\ frac {1} {36}) +3× (\ frac {2} {36}) +4 × (\ frac {3} {36}) +5× (\ frac {4} {36}) +6× (\ frac {5} {36}) +5× (\ frac {5} {36}) +5× (\ frac {5} {36}) +6× (\ frac {5} {36}}) +7× (\ розрив {6} {36}) +8× (\ розрив {5} {36}) +9× (\ розрив {4} {36}) +10× (\ розрив {3} {36}) +11× (\ розрив {2 } {36}) +12× (\ розрив {1} {36}) = 7\). У невизначених економічних ситуаціях, пов'язаних з можливими фінансовими вигодами або втратами, середнє значення або середнє значення або очікуване значення часто використовується для вираження очікуваної прибутковості. Інші зазвичай використовувані заходи прибутковості при невизначеній можливості, крім середнього або очікуваного значення, є режим (найімовірніше значення) і медіана (число з половиною чисел над ним і половиною чисел під ним - 50-відсоткова відмітка). Він являє собою очікувану віддачу від починання; однак, це не виражає ризику, пов'язаного з невизначеною ситуацією. Переходимо до цього зараз.
Що стосується табл. 2.1 та таблиці 2.2, для місць A та B втрат пожежних вимог очікуваним значенням втрат є тяжкість пожежних вимог, 6166,67 доларів, а очікувана кількість претензій - частота виникнення, 10.2 претензій на рік.
Ключові виноси
У цьому розділі ви дізналися про кількісну оцінку невизначених результатів за допомогою моделей ймовірності. Більш конкретно, ви заглибилися в методи обчислень:
- Тяжкість як міра наслідку невизначеності — це очікуване значення або середнє значення втрат, що виникає в різних державах світу. Тяжкість можна отримати, склавши всі значення втрат у вибірці і розділивши на загальний розмір вибірки.
- Якщо взяти таблицю ймовірностей (розподіл ймовірностей), то очікуване значення отримують шляхом множення ймовірності того чи іншого збитку, що настає на розмір втрат і підсумовуючи по всіх можливостях.
- Частота - це очікувана кількість випадків втрат , що виникають в різних державах світу.
- Імовірність і розподіл ймовірностей представляють відносну частоту виникнення (частоту виникнення події, поділену на загальну частоту всіх подій) різних подій в невизначених ситуаціях.
Питання для обговорення
- Дослідження втрат даних, понесених компаніями через хакери, які
проникають в Інтернет-безпеку фірми, виявило, що 60 відсотків
досліджуваних фірм у галузі зазнали
порушень безпеки і що середня втрата за порушення безпеки становила
15 000 доларів.
- Яка ймовірність того, що фірма не матиме порушення безпеки?
- Одна фірма мала два порушення за один рік і розглядає можливість витрачати гроші, щоб зменшити ймовірність порушення. Припускаючи , що наступний рік буде таким же, як і цього року з точки зору порушень безпеки, скільки фірма повинна бути готова заплатити за усунення порушень безпеки (тобто, яка очікувана вартість їх втрати)?
- Нижче наведено досвід роботи Страховика А за останні три
роки:
Рік Кількість експозицій Кількість претензій на зіткнення Втрати при зіткненні ($) 1 10 000 375 350 000 2 10 000 330 250 000 3 10 000 420 400 000 - Яка періодичність втрат в 1 році?
- Обчисліть ймовірність втрати в 1 році.
- Розрахуйте середні втрати на рік за претензіями та збитками при зіткненні.
- Розрахуйте середні втрати на експозицію.
- Розрахуйте середні втрати по претензії.
- Яка періодичність втрат?
- Яка тяжкість втрат?
- Нижче наведено досвід роботи Страховика В за останні три
роки:
Рік Кількість експозицій Кількість претензій на зіткнення Втрати при зіткненні ($) 1 20 000 975 650 000 2 20 000 730 850 000 3 20 000 820 900 000 - Розрахуйте середнє або середнє число претензій на рік для страховика за трирічний період.
- Обчисліть середнє або середнє доларове значення втрат при зіткненні за експозицію за рік 2.
- Розрахуйте очікуване значення (середнє або середнє) збитків за претензію за трирічний період.
- За кожен з трьох років розрахуйте ймовірність того, що одиниця експозиції подасть претензію.
- Яка середня частота втрат?
- Яка середня тяжкість втрат?
- Що таке стандартне відхилення втрат?
- Обчисліть коефіцієнт варіації.