4.7: Межі виявлення
- Page ID
- 24885

Міжнародний союз чистої та прикладної хімії (IUPAC) визначає межу виявлення методу як найменшу концентрацію або абсолютну кількість аналіту, який має сигнал значно більший, ніж сигнал з відповідного бланка [IUPAC Compendium of Chemical Technology, Електронна версія]. Хоча наш інтерес полягає в кількості аналіту, в цьому розділі ми визначимо межу виявлення з точки зору сигналу аналіта. Знаючи сигнал, ви можете обчислити концентрацію аналіта, C A, або молі аналіту, n A, використовуючи рівняння
\[S_A = k_A C_A \text{ or } S_A = k_A n_A \nonumber\]
де k - чутливість методу.
Див. Розділ 3 для огляду цих рівнянь.
Давайте переведемо визначення межі виявлення IUPAC в математичну форму, дозволивши S mb представляти середній сигнал для порожнього методу, і дозволяючи\(\sigma_{mb}\) представляти стандартне відхилення методу бланка. Нульова гіпотеза полягає в тому, що аналіт відсутній у вибірці, а альтернативна гіпотеза полягає в тому, що аналіт присутній у вибірці. Для виявлення аналіта його сигнал повинен перевищувати S mb на відповідну кількість; таким чином,
\[(S_A)_{DL} = S_{mb} \pm z \sigma_{mb} \label{4.1}\]
\((S_A)_{DL}\)де межа виявлення аналіта.
Якщо\(\sigma_{mb}\) невідомо, ми можемо замінити його на s mb; Рівняння\ ref {4.1} тоді стає
\[(S_A)_{DL} = S_{mb} \pm t s_{mb} \nonumber\]
Аналогічні корективи ви можете внести в інші рівняння в цьому розділі. Див., наприклад, Кіршнер, К.Дж. «Оцінка меж виявлення для екологічних аналітичних процедур» в Каррі, Л.А. (ред) Виявлення в аналітичній хімії: важливість, теорія та практика; Американське хімічне товариство: Вашингтон, округ Колумбія, 1988.
Значення, яке ми вибираємо для z, залежить від нашого допуску для звітування про концентрацію аналіта, навіть якщо він відсутній у зразку (помилка типу 1). Зазвичай z встановлюється в три, що, з додатка 3, відповідає ймовірності\(\alpha\), 0,00135. Як показано на малюнку Template:index a, існує лише 0.135% ймовірності виявлення аналіту у зразку, який насправді не містить аналітів.
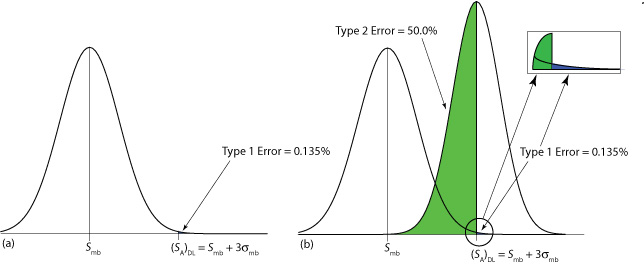
Межа виявлення також піддається помилці типу 2, в якій ми не можемо знайти докази для аналіту, навіть якщо він присутній у зразку. Розглянемо, наприклад, ситуацію, наведену на рисунку Template:index b, коли сигнал для зразка, який містить аналіт, точно дорівнює (S A) DL. У цьому випадку ймовірність помилки типу 2 становить 50%, оскільки половина можливих сигналів зразка нижче межі виявлення. Ми правильно виявляємо аналіт на межі виявлення IUPAC лише половину часу. Визначення IUPAC для межі виявлення є найменшим сигналом, для якого ми можемо сказати, на рівні значущості\(\alpha\), що аналіт присутній у зразку; однак, неможливість виявити аналіт не означає, що він відсутній у зразку.
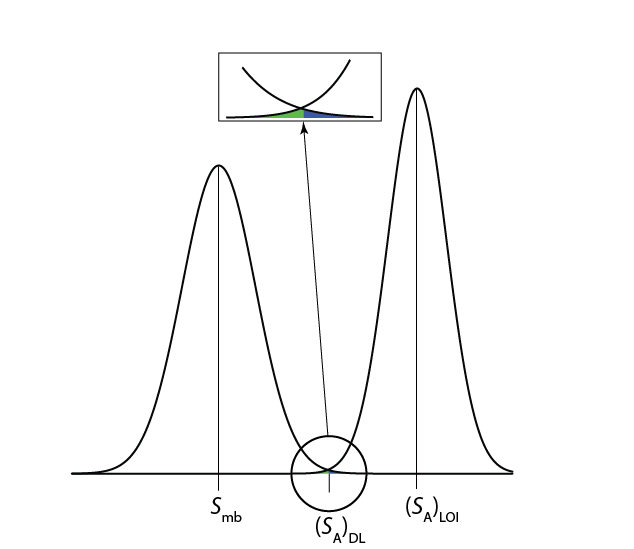
Межа виявлення часто представляється, особливо при обговоренні питань державної політики, як окрему лінію, яка відокремлює виявлені концентрації аналітів від концентрацій, які ми не можемо виявити. Таке використання межі виявлення є неправильним [Rogers, L.B. J. Chem. Едук. 1986, 63, 3—6]. Як пропонує Рисунок Template:index, для аналіту, концентрація якого знаходиться поблизу межі виявлення, існує велика ймовірність того, що ми не зможемо виявити аналіт.
Альтернативний вираз для межі виявлення, межа ідентифікації, мінімізує помилки типу 1 і типу 2 [Long, GL; Winefordner, J.D. Anal. Хім. 1983, 55, 712—724А]. Сигнал аналіта на межі ідентифікації, (S A) LOI\(z \sigma_A\), включає додатковий термін, для обліку розподілу сигналу аналіта.
\[(S_A)_\text{LOI} = (S_A)_\text{DL} + z \sigma_A = S_{mb} + z \sigma_{mb} + z \sigma_A \nonumber\]
Як показано на рисунку Template:index, межа ідентифікації забезпечує рівну ймовірність помилки типу 1 та 2 типу на межі виявлення. Коли концентрація аналіту знаходиться на межі ідентифікації, існує лише 0,135% ймовірність того, що його сигнал не відрізняється від сигналу методу бланка.
Здатність виявляти аналіт з упевненістю не те ж саме, що здатність з упевненістю повідомляти про його концентрацію, або розрізняти його концентрацію в двох зразках. З цієї причини Комітет Американського хімічного товариства з екологічної аналітичної хімії рекомендує межу кількісного визначення, (S A) LOQ [«Керівні принципи збору даних та оцінки якості даних в хімії навколишнього середовища ,» Анальний. Хім. 1980, 52, 2242—2249].
\[(S_A)_\text{LOQ} = S_{mb} + 10 \sigma_{mb} \nonumber\]