14.7: Регресія до середнього
- Page ID
- 98207

Цілі навчання
- Вивчити регресію до середнього
Регресія до середнього передбачає результати, які принаймні частково обумовлені випадковістю. Почнемо з прикладу завдання, яке є цілком випадковим: Уявіть собі експеримент, в якому група\(25\) людей передбачила результати сальто справедливої монети. Для кожного предмета експерименту монета перевертається\(12\) раз, і суб'єкт прогнозує результат кожного сальто. \(\PageIndex{1}\)На малюнку показані результати моделювання цього «експерименту». Хоча більшість предметів були правильними від\(5\) 2 до\(8\) разів\(12\), один змодельований предмет був правильним\(10\) часом. Зрозуміло, що цьому предмету дуже пощастило і, ймовірно, не так добре, якби він виконав завдання вдруге. Насправді найкращий прогноз кількості разів, коли ця тема була б правильною на повторному тесті\(6\), оскільки ймовірність бути правильною на даному випробуванні є\(0.5\) і є\(12\) випробування.
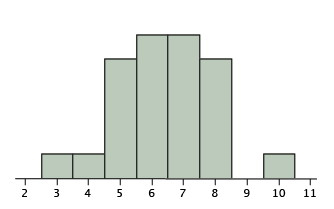
Більш технічно найкращим прогнозом результату суб'єкта на повторному тесті є середнє значення біноміального розподілу з\(N = 12\) і\(p = 0.50\). Цей розподіл показаний на малюнку\(\PageIndex{2}\) і має середнє значення\(6\).
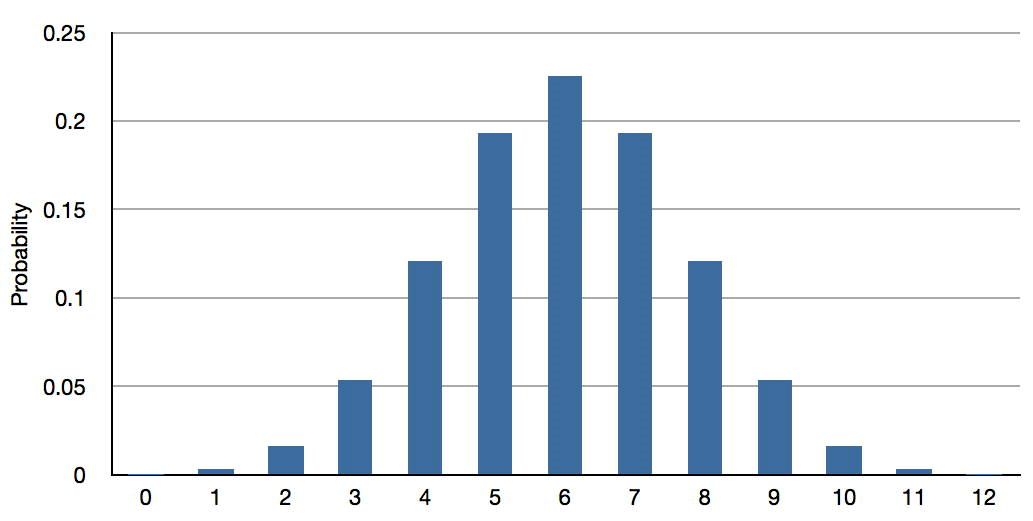
Справа тут в тому, що незалежно від того, скільки монет перевертає предмет, передбачений правильно, найкращим прогнозом їх оцінки на повторному тесті є\(6\).
Тепер ми розглянемо тест, який ми будемо називати "Тест А", який частково є випадковістю і частково майстерністю: Замість того, щоб передбачати результати сальто\(12\) монет, кожен суб'єкт прогнозує результати сальто\(6\) монет і відповідає на\(6\) правдиві/помилкові питання про світову історію. Припустимо, що середній бал на питаннях\(6\) історії є\(4\). Оцінка суб'єкта на тесті А має велику частку шансів, але також залежить від знань історії. Якщо суб'єкт набрав дуже високий бал на цьому тесті (наприклад, оцінка\(10/12\)), цілком ймовірно, що вони добре впоралися як з питаннями історії, так і з монетами. Якщо цей предмет потім дається другий тест (тест B), який також включав прогнози монет та питання історії, їх знання історії було б корисним, і вони знову очікували б оцінка вище середнього. Однак, оскільки їх висока продуктивність на монетній частині Test A не буде прогнозувати ефективність їх монет на тесті B, вони не очікували б, що вони будуть проходити також на тесті B, як і на тесті A. Тому найкращий прогноз їхнього балу на тесті B буде десь між їх оцінкою на тесті А та середнім значенням тесту B. Ця тенденція суб'єктів з високими значеннями на міру, яка включає шанс і вміння забивати ближче до середнього на повторному тесті, називається "»\(\textit{regression toward the mean}\).
Суть явища регресії до середнього полягає в тому, що люди з високими балами, як правило, вище середнього за майстерністю та удачею, і що лише частина майстерності має відношення до майбутньої продуктивності. Так само люди з низькими балами, як правило, нижче середнього за майстерністю та удачею, і їх невдача не має відношення до майбутньої продуктивності. Це не означає, що всі люди, які мають високий бал, мають удачу вище середнього. Однак в середньому вони це роблять.
Практично кожна міра поведінки має шанс і складову майстерності до нього. Візьмемо за приклад оцінку учня на підсумковому іспиті. Звичайно, знання студента з цього предмета буде основним визначальним фактором його оцінки. Однак є аспекти продуктивності, які обумовлені випадковістю. Іспит не може охоплювати все в курсі і тому повинен представляти підмножину матеріалу. Можливо, студенту пощастило в тому, що один аспект курсу, який студент погано розумів, був недостатньо представлений на тесті. Або, можливо, студент не був впевнений, який з двох підходів до проблеми буде кращим, але більш-менш випадково вибрав правильний. Інші елементи випадковості вступають в гру, а також. Можливо, школяр прокинувся рано вранці випадковим телефонним дзвінком, що призвело до втоми і зниження працездатності. І, звичайно, ворожіння на питаннях з множинним вибором - ще одне джерело випадковості в тестових балах.
Там буде регресія до середнього в тестовому повторному випробуванні ситуації, коли між тестом і повторним тестом є менше, ніж ідеальний (\(r = 1\)) зв'язок. Це випливає з формули для лінії регресії зі стандартизованими змінними, наведеної нижче:
\[Z_{Y'} = (r)(Z_X)\]
З цього рівняння зрозуміло, що якщо абсолютне значення\(r\) менше\(1\), то прогнозоване значення\(Z_Y\) буде ближче до того\(0\), що середнє для стандартизованих балів, ніж є\(Z_X\). Крім того, зверніть увагу, що якщо співвідношення між\(X\) і\(Y\) є\(0\), як це було б для завдання, яке все пощастило, передбачуваний стандартний бал для\(Y\) є його середнім\(0\), незалежно від оцінки на\(X\).
\(\PageIndex{3}\)На малюнку показано розсіяну діаграму з лінією регресії, що прогнозує стандартизований словесний SAT від стандартизованого Math SAT Зверніть увагу, що нахил лінії дорівнює кореляції\(0.835\) між цими змінними.
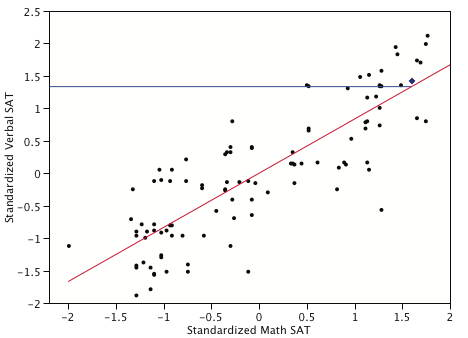
Точка, представлена синім діамантом, має значення\(1.6\) на стандартизованому Math SAT. Це означає, що цей студент набрав\(1.6\) стандартні відхилення вище середнього на Math SAT. Прогнозований бал є\((r)(1.6) = (0.835)(1.6) = 1.34\). Горизонтальна лінія на графіку показує значення прогнозованого балу. Ключовим моментом є те, що хоча цей студент набрав\(1.6\) стандартні відхилення вище середнього на Math SAT, він або вона тільки прогнозується, щоб набрати\(1.34\) стандартні відхилення вище середнього на словесних SAT. Таким чином, прогноз полягає в тому, що словесний бал SAT буде ближче до середнього\(0\), ніж є оцінка Math SAT. Аналогічно, студент, який забив набагато нижче середнього на Math SAT, буде прогнозовано, що оцінка вище на словесних SAT.
Регресія до середнього відбувається в будь-якій ситуації, в якій спостереження підбираються на основі виконання завдання, що має випадкову складову. Якщо ви вибираєте людей виходячи з їх виконання на такому завданні, ви будете вибирати людей частково виходячи з їх майстерності і частково виходячи з їх удачі на поставлене завдання. Оскільки не можна очікувати, що їхня удача збережеться від судового розгляду до судового розгляду, найкращий прогноз виступу людини на другому випробуванні буде десь між їх виконанням на першому випробуванні та середнім показником на першому випробуванні. Ступінь, до якої оцінка, як очікується, «регресує до середнього» таким чином, залежить від відносного внеску випадковості та майстерності в завдання: чим більша роль випадковості, тим більше регресія до середнього.
Помилки, що виникають внаслідок нерозуміння регресії до середнього
Нездатність оцінити регресію до середнього є загальним явищем і часто призводить до неправильних тлумачень і висновків. Один з кращих прикладів наводить Нобелівський лауреат Даніель Канеман в своїй автобіографії. Доктор Канеман намагався навчити льотних інструкторів, що похвала є більш ефективною, ніж покарання. Він був оскаржений одним з інструкторів, які ретранслювали, що в його досвіді хвалити курсанта за виконання чистого маневру, як правило, супроводжується меншою продуктивністю, тоді як крик на курсанта за погане виконання, як правило, супроводжується поліпшеною продуктивністю. Це, звичайно, саме те, що можна було б очікувати на основі регресії до середнього. Продуктивність пілота, хоча і базується на значній майстерності, буде варіюватися випадковим чином від маневру до маневру. Коли пілот виконує надзвичайно чистий маневр, цілком ймовірно, що йому чи їй пощастило на їхню користь на додаток до їх значної майстерності. Після похвали, але не через це, компонент удачі, ймовірно, зникне, а продуктивність буде нижчою. Аналогічно, погана продуктивність, ймовірно, частково пов'язана з невдачею. Після критики, але не через неї, наступний виступ, швидше за все, буде кращим. Щоб відвезти цю точку додому, Канеман змусив кожного інструктора виконати завдання, в якому монета була кинута в ціль двічі. Він продемонстрував, що продуктивність тих, хто зробив найкраще з першого разу, погіршилася, тоді як показники тих, хто зробив найгірше, покращилися.
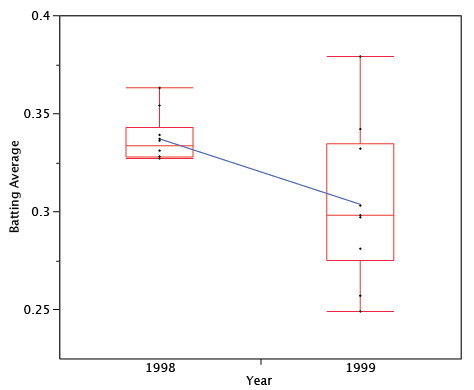
Регресія до середнього часто присутня в спортивних показниках. Хорошим прикладом є Schall і Smith (\(2000\)), який проаналізував багато аспектів бейсбольної статистики, включаючи ватин середні гравці в\(1998\). Вони вибрали\(10\) гравців з найвищими середніми показниками ватин (BAs)\(1998\) і перевірили, наскільки добре вони зробили\(1999\). Відповідно до того, що можна було б очікувати на основі регресії до середнього, ці гравці повинні, в середньому, мати нижчі середні показники ватин,\(1999\) ніж вони зробили в\(1998\). Як видно в таблиці\(\PageIndex{1}\),\(7/10\) гравці мали нижчі середні значення ватин\(1999\), ніж вони зробили в\(1998\). Більш того, ті, хто мав вищі середні показники,\(1999\) були лише трохи вищими, тоді як ті, хто був нижчим, були набагато нижчими. Середнє зниження від\(1998\) до\(1999\) було\(33\) балів. Незважаючи на це, більшість з цих гравців мали відмінні середні значення ватин,\(1999\) вказуючи на те, що майстерність була важливою складовою їх\(1998\) середніх.
| 1998 | 1999 | Різниця |
|---|---|---|
| 363 | 379 | 16 |
| 354 | 298 | -56 |
| 339 | 342 | 3 |
| 337 | 281 | -56 |
| 336 | 249 | -87 |
| 331 | 298 | -33 |
| 328 | 297 | -31 |
| 328 | 303 | -25 |
| 327 | 257 | -70 |
| 327 | 332 | 5 |
\(\PageIndex{4}\)На малюнку показані середні значення ватину за два роки. Зниження від\(1998\) до\(1999\) зрозуміло. Зверніть увагу, що хоча середнє значення зменшилося з\(1998\), деякі гравці збільшили свої середні показники ватин. Це ілюструє, що регресія до середнього не відбувається для кожної людини. Хоча прогнозовані бали для кожної людини будуть нижчими, деякі прогнози будуть неправильними.
Регресія до середнього грає роль у так званому «другокурснику», хорошим прикладом якого є те, що гравець, який виграє «новачок року», зазвичай робить менш добре у своєму другому сезоні. Пов'язане явище називається Sports Illustrated Cover Jinx.
Експеримент без контрольної групи може плутати ефекти регресії з реальними ефектами. Наприклад, розглянемо гіпотетичний експеримент для оцінки програми вдосконалення читання. Усі першокласники шкільного округу отримали тест на досягнення читання, а читачі з\(50\) найнижчими балами були зараховані до програми. Студенти були повторно перевірені за програмою, і середнє поліпшення було великим. Чи обов'язково це означає, що програма була ефективною? Ні, може бути, що початкові погані показники студентів були частково пов'язані з невдачею. Очікується, що їхня удача покращиться в повторному тесті, що збільшить їх бали з програмою лікування або без неї.
Для реального прикладу розглянемо експеримент, який прагнув визначити, чи буде препарат пропранолол збільшувати бали SAT студентів, які, як вважають, мають тривожність тесту. Пропранолол був наданий\(25\) старшокласникам вибраних, оскільки тести на IQ та інші успішності вказували на те, що вони не зробили так добре, як очікувалося на SAT. На повторному тесті, зробленому після отримання пропранололу, студенти покращили свої бали SAT в середньому\(120\) балів. Це було значно більшим збільшенням, ніж очікувані\(38\) бали просто на підставі того, що пройшов тест раніше. Проблема з дослідженням полягає в тому, що метод відбору студентів, ймовірно, призвів до непропорційної кількості студентів, яким не пощастило, коли вони вперше взяли SAT. Отже, ці студенти, ймовірно, збільшили б свої бали на повторному тесті з пропранололом або без нього. Це не означає, що пропранолол не мав ніякого ефекту. Однак, оскільки можливі ефекти пропранололу та ефекти регресії були збентежені, ніяких твердих висновків робити не слід.
Випадкове призначення студентів або до групи пропранололу або контрольної групи покращило б експериментальну конструкцію. Оскільки ефекти регресії тоді не були б систематично різними для двох груп, значна різниця забезпечила б хороші докази ефекту пропранололу.
Нью-Йорк Таймс статті про дослідження
Шалл, Т., & Сміт, Г. (2000) Чи бейсболісти регрес до середнього? Американський статистик, 54, 231-235.