9.5: Розподіл вибірки середнього
- Page ID
- 98347

Цілі навчання
- Створити середнє значення і дисперсію розподілу вибірки середнього
- Обчислити стандартну похибку середнього
- Створити центральну граничну теорему
Розподіл вибірки середнього значення було визначено в розділі, що вводить розподіли вибірки. У цьому розділі розглядаються деякі важливі властивості розподілу вибірки середнього, введеного в демонстраціях в цьому розділі.
Середнє відбір проб
Середнє розподіл вибірки середнього значення - це середнє значення популяції, з якої були вибіркові бали. Тому, якщо сукупність має середнє\(\mu\) значення, то середнє значення розподілу вибірки середнього значення також є\(\mu\). Символ\(\mu _M\) використовується для позначення середнього розподілу вибірки середнього. Тому формулу середнього розподілу вибірки середнього можна записати так:
\[\mu _M = \mu\]
Дисперсія вибірки
Дисперсія розподілу вибірки середнього обчислюється наступним чином:
\[ \sigma_M^2 = \dfrac{\sigma^2}{N}\]
Тобто дисперсія розподілу вибірки середнього - це дисперсія популяції, поділена на\(N\), розмір вибірки (кількість балів, що використовуються для обчислення середнього). Таким чином, чим більше розмір вибірки, тим менше дисперсія розподілу вибірки середнього.
Примітка
(необов'язково) Цей вираз можна дуже легко отримати із закону суми дисперсії. Почнемо з обчислення дисперсії розподілу вибірки суми трьох чисел, вибіркових з популяції з дисперсією\(\sigma ^2\). The variance of the sum would be:
\[\sigma ^2 + \sigma ^2 + \sigma ^2\]
Для\(N\) numbers, the variance would be \(N\sigma ^2\). Since the mean is \(1/N\) times the sum, the variance of the sampling distribution of the mean would be \(1/N^2\) разів дисперсія суми, яка дорівнює\(\sigma ^2/N\).
Стандартна похибка середнього - це стандартне відхилення розподілу вибірки середнього. Тому квадратний корінь дисперсії розподілу вибірки середнього і може бути записаний як:
\[ \sigma_M = \dfrac{\sigma}{\sqrt{N}}\]
Стандартна похибка представлена а\(\sigma\) тому, що це стандартне відхилення. Індексний індекс (\(M\)) вказує на те, що стандартна помилка, про яку йде мова, є стандартною помилкою середнього.
Центральна гранична теорема
Визначення
Центральна гранична теорема стверджує, що:
Враховуючи сукупність із скінченним\(\mu\) середнім та скінченною ненульовою дисперсією\(\sigma ^2\), розподіл вибірки середнього наближається до нормального розподілу із середнім\(\mu\) значенням та дисперсією\(\sigma ^2/N\) як\(N\), the sample size, increases.
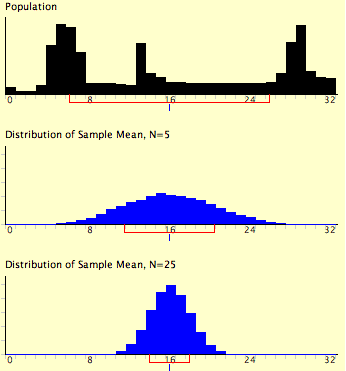
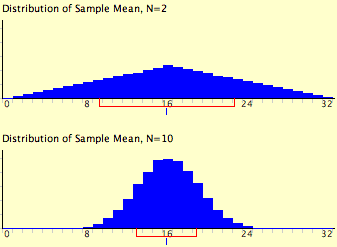
Вирази для середнього і дисперсійного розподілу вибірки середнього не є новими або чудовими. Що примітно, це те, що незалежно від форми материнської популяції, розподіл вибірки середнього наближається до нормального розподілу зі\(N\) збільшенням. Якщо ви використовували «Демо центральної граничної теореми», ви вже переконалися в цьому самі. Нагадуємо, на малюнку\(\PageIndex{1}\) показані результати моделювання для\(N = 2\) і\(N = 10\). Материнське населення було рівномірним розподілом. Ви можете бачити, що дистрибутив для\(N = 2\) далекий від нормального розподілу. Тим не менш, це показує, що оцінки щільніше посередині, ніж у хвостах. \(N = 10\)Бо розподіл досить близький до нормального розподілу. Зверніть увагу, що засоби двох дистрибутивів однакові, але що розкид розподілу для\(N = 10\) менший.
На малюнку\(\PageIndex{2}\) показано, наскільки тісно розподіл вибірки середнього наближається до нормального розподілу навіть тоді, коли материнська популяція дуже ненормальна. Якщо ви уважно подивитеся, ви можете побачити, що розподіли вибірки дійсно мають невеликий позитивний перекос. Чим більше розмір вибірки, тим ближче розподіл вибірки середнього буде до нормального розподілу.