19.2: Побудова моделі на основі агентів
- Page ID
- 67739
Почнемо з моделювання на основі агентів. Насправді, є багато чудових навчальних посібників вже там про те, як побудувати ПРО, особливо ті, які Чарльз Макал і Майкл Норт, відомі агенти на основі модельєрів в Аргоннській національній лабораторії [84]. Macal і North пропонують розглянути наступні аспекти при розробці моделі на основі агентів:
- Конкретна проблема, яку повинен вирішити ПРО
- Проектування агентів та їх статичних/динамічних атрибутів
- Дизайн середовища та спосіб взаємодії агентів з ним
- Дизайн поведінки агентів
- Проектування взаємних взаємодій агентів
- Наявність даних
- Метод валідації моделі
Серед цих пунктів 1, 6 та 7 стосуються фундаментальних наукових методологій. Важливо мати на увазі, що просто побудова довільної ПРО та отримання результатів шляхом моделювання не дасть жодного науково значущого висновку. Для того, щоб ПРО був науково значущим, він повинен бути побудований і використаний в будь-якому з наступних двох взаємодоповнюючих підходів:
- Побудувати ПРО, використовуючи модельні припущення, які походять від емпірично спостережуваних явищ, а потім виробляти раніше невідомі колективні поведінки шляхом моделювання.
- Побудувати ПРО, використовуючи гіпотетичні моделі припущень, а потім відтворити емпірично спостережувані колективні явища шляхом моделювання.
Перший полягає у використанні ПРО для прогнозування, використовуючи перевірені теорії поведінки агентів, тоді як останній - досліджувати та розробляти нові пояснення емпірично спостережуваних явищ. Ці два підходи різні з точки зору масштабів відомого та невідомого (A використовує мікро-відомі для отримання макро-невідомого, тоді як B використовує мікро-невідоме для відтворення макровідомих), але важливо те, що одна з цих шкал повинна бути заснована на усталених емпіричних знаннях. В іншому випадку результати моделювання не матимуть жодних наслідків для модельованої реальної системи. Звичайно, вільне дослідження різної колективної динаміки шляхом тестування гіпотетичної поведінки агентів для отримання гіпотетичних результатів є досить веселим та навчальним, з великою кількістю власних інтелектуальних переваг. Моя думка полягає в тому, що ми не повинні неправильно інтерпретувати результати, отримані від таких дослідницьких ПРО, як підтверджене прогнозування реальності.
Тим часом пункти 2, 3, 4 та 5 у списку Macal та North вище більше зосереджені на технічних аспектах моделювання. Вони можуть бути переведені в наступні завдання проектування в реальному кодуванні за допомогою мови програмування на кшталт Python:
- Спроектуйте структуру даних для зберігання атрибутів агентів.
- Спроектуйте структуру даних для зберігання станів навколишнього середовища.
- Опишіть правила того, як оточення поводиться самостійно.
- Опишіть правила взаємодії агентів з навколишнім середовищем.
- Опишіть правила того, як агенти поводяться самостійно.
- Опишіть правила взаємодії агентів один з одним.
Представлення агентів у Python
Часто зручно і звично визначати як атрибути агентів, так і поведінку за допомогою класу в об'єктно-орієнтованих мовах програмування, але в цьому підручнику ми не будемо докладно розглядати об'єктно-орієнтоване програмування. Натомість ми будемо використовувати динамічний клас Python як чисту структуру даних для стислого зберігання атрибутів агентів. Наприклад, ми можемо визначити порожній клас агента наступним чином:

Команда class визначає новий клас, під яким можна визначити різні атрибути (змінні, властивості) і методи (функції, дії). У звичайному об'єктно-орієнтованому програмуванні потрібно дати більш конкретні визначення атрибутів і методів, доступних під цим класом. Але в цьому підручнику ми будемо трохи ліниві і використовувати динамічний, гнучкий характер класів Python. Тому ми просто кинули пас у визначення класу. pass - це фіктивне ключове слово, яке нічого не робить, але нам все одно потрібно щось там тільки з синтаксичних причин.
У будь-якому випадку, як тільки цей клас агента визначено, ви можете створити новий порожній об'єкт агента наступним чином:

Потім ви можете динамічно додавати різні атрибути до цього об'єкту агента a:

Ця гнучкість дуже схожа на гнучкість словника Python. Вам не потрібно заздалегідь визначати атрибути об'єкта Python. Як ви привласнюєте значення атрибуту (записується як «ім'я об'єкта». «attribute»), Python автоматично генерує новий атрибут, якщо він не був визначений раніше. Якщо ви хочете знати, які типи атрибутів доступні під об'єктом, ви можете скористатися командою dir:

Перші два атрибути є типовими атрибутами Python, які доступні для будь-яких об'єктів (їх можна ігнорувати зараз). Крім тих, ми бачимо, що є чотири атрибути визначені для цього об'єкта a.
В іншій частині цього розділу ми будемо використовувати це представлення агента на основі класів. Технічна архітектура кодів симуляторів залишається такою ж, як і раніше, складається з трьох компонентів: функції ініціалізації, візуалізації та оновлення. Давайте попрацюємо над деякими прикладами, щоб побачити, як можна побудувати ABM в Python.
Модель сегрегації Шеллінга
Існує ідеальна модель для нашої першої вправи ПРО. Вона називається моделлю сегрегації Шеллінга, широко відомою як найперша ПРО, запропонована на початку 1970-х Томасом Шеллінгом, лауреатом Нобелівської премії з економіки 2005 року [85]. Шеллінг створив цю модель для того, щоб дати пояснення того, чому люди з різним етнічним походженням схильні географічно відокремлювати. Тому ця модель була розроблена в розглянутому вище підході В, відтворюючи макровідомі за допомогою гіпотетичних мікро-невідомих. Моделі припущення, які використовували Шеллінг, полягали в наступному:
- Два різних типи агентів розподіляються в скінченному двовимірному просторі.
- У кожній ітерації випадково обраний агент оглядає околиці, і якщо частка агентів одного типу серед сусідів знаходиться нижче порогу, він перестрибує в інше місце, випадково вибране в просторі.
Як бачите, правило даної моделі гранично просте. Головне питання, яке Шеллінг звернувся з цією моделлю, полягало в тому, наскільки високим повинен бути поріг для того, щоб відбулася сегрегація. Може здатися розумним припустити, що сегрегація вимагатиме високогомофільних агентів, тому критичний поріг може бути відносно високим, скажімо, 80% або близько того. Але те, що Шеллінг насправді показав, що критичний поріг може бути набагато нижчим, ніж можна було б очікувати. Це означає, що сегрегація може відбуватися, навіть якщо люди не такі гомофільні. Тим часом, зовсім всупереч нашій інтуїції, високий рівень гомофілії насправді може призвести до змішаного стану суспільства, оскільки агенти продовжують рухатися, не досягаючи нерухомого стану. Ми можемо спостерігати ці виникаючі поведінки в симуляціях.
Ще на початку 1970-х років Шеллінг моделював свою модель на графічному папері, використовуючи копійки та нікелі як два типи агентів (це все ще було ідеально обчислювальним моделюванням!). Але тут ми можемо послабити просторові обмеження та імітувати цю модель у безперервному просторі. Давайте спроектуємо імітаційну модель поетапно, проходячи завдання проектування, перераховані вище.
1. Спроектуйте структуру даних для зберігання атрибутів агентів. У цій моделі кожен агент має атрибут type, а також позицію у двовимірному просторі. Два типи можуть бути представлені 0 і 1, а просторове положення може бути в будь-якому місці в межах одиниці квадрата. Тому ми можемо генерувати кожного агента наступним чином:

Щоб генерувати популяцію агентів, ми можемо написати щось на кшталт:

2. Спроектуйте структуру даних для зберігання станів навколишнього середовища, 3. Опишіть правила того, як середовище поводиться самостійно, & 4. Опишіть правила взаємодії агентів з навколишнім середовищем. Модель Шеллінга не має окремого середовища, яке взаємодіє з агентами, тому ми можемо пропустити ці завдання проектування.
5. Опишіть правила того, як агенти поводяться самостійно. Ми припускаємо, що агенти нічого не роблять самі по собі, тому що їх дії (рухи) запускаються лише взаємодією з іншими агентами. Таким чином, ми можемо ігнорувати це завдання проектування теж.
6. Опишіть правила взаємодії агентів один з одним. Нарешті, є щось, що нам потрібно реалізувати. Припущення моделі говорить, що кожен агент перевіряє, хто знаходиться в його районі, і якщо частка інших агентів того ж типу менше порогу, вона переходить до іншого випадково вибраного місця. Це вимагає виявлення сусідів, що було легко в CA та мережах, оскільки відносини сусідства були явно змодельовані в цих моделюючих рамках. Але в ПРО відносини сусідства можуть бути неявними, що стосується нашої моделі. Тому нам потрібно реалізувати код, який дозволяє кожному агенту знайти, хто знаходиться поруч.
Існує кілька обчислювально-ефективних алгоритмів, доступних для виявлення сусідів, але тут ми використовуємо найпростіший можливий метод: Вичерпний пошук. Ви буквально перевіряєте всі агенти, один за іншим, щоб побачити, чи є вони досить близькими до вогнищевого агента. Це не є обчислювально-ефективним (його обчислювальна кількість збільшується квадратично з збільшенням кількості агентів), але дуже простий і надзвичайно простий у реалізації. Ви можете написати таке вичерпне виявлення сусідів за допомогою розуміння списку Python, наприклад:

Тут ag - вогнищевий агент, сусіди якого шукають. Частина if у осмисленні списку вимірює відстань у квадраті між ag та nb, і якщо вона менше r в квадраті (r - радіус сусідства, який повинен бути визначений раніше в коді) nb включається в результат. Також зверніть увагу, що додаткова умова nb! = ag дається в частині if. Це пов'язано з тим, що якщо nb == ag, відстань завжди дорівнює 0, тому сам ag буде помилково включений як сусід ag.
Як тільки ми отримаємо сусідів для ag, ми можемо обчислити частку інших агентів, тип яких такий же, як у ag, і якщо він менше заданого порогу, позиція ag випадковим чином скидається. Нижче наведено завершений код симулятора, при цьому функція візуалізації також реалізована за допомогою простої функції сюжету:




Коли ви запускаєте цей код, вам слід встановити розмір кроку 50 на вкладці «Налаштування», щоб прискорити моделювання.
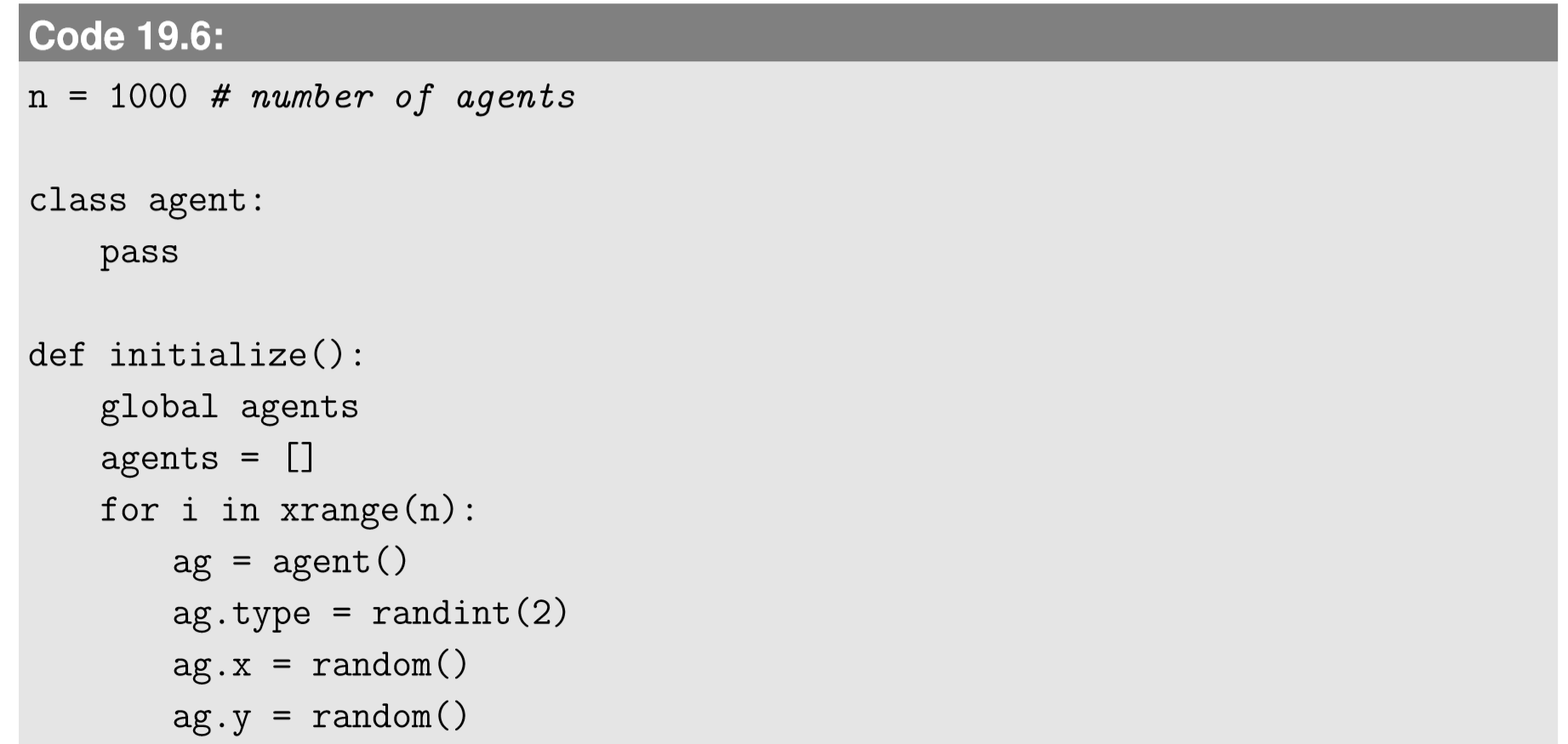
На малюнку 19.2.1 показаний результат з радіусом сусідства r=0,1 і порогом переміщення th = 0,5. Чітко помічено, що агенти самоорганізовуються від спочатку випадкового розподілу до плямистої картини, де два типи чітко відокремлені один від одного.
Проводити моделювання моделі сегрегації Шеллінга з th (поріг переміщення), r (радіус сусідства), та/або n (розмір населення = щільність) змінювалися систематично. Визначте стан, при якому відбувається сегрегація. Перехід поступовий або різкий?
Розробіть метрику, яка характеризує рівень сегрегації з позицій двох типів агентів. Потім побудуйте, як ця метрика змінюється, оскільки значення параметрів змінюються.
Ось деякі інші відомі моделі, які демонструють досить унікальні емерджентні моделі або динамічну поведінку. Вони можуть бути реалізовані як ПРО шляхом зміни коду для моделі сегрегації Шеллінга. Отримуйте задоволення!
Дифузійно-обмежена агрегація (DLA) - це процес зростання кластерів агрегованих частинок, керованих їх випадковою дифузією. Існує два типи частинок, як у моделі сегрегації Шеллінга, але лише один з них може вільно рухатися. Рухомі частинки дифундують у двовимірному просторі випадковим ходінням, тоді як нерухомі частинки нічого не роблять; вони просто залишаються там, де вони є. Якщо рухома частинка «стикається» з нерухомою частинкою (тобто, якщо вони наближаються досить близько один до одного), рухома частинка стає нерухомою і залишається там назавжди. Це єдине правило взаємодії агентів.
Реалізуйте код симулятора моделі DLA. Проведіть моделювання з усіма спочатку рухомими частинками, крім однієї нерухомої «насіннєвої» частинки, розміщеної в центрі простору, і спостерігайте, який просторовий малюнок виходить. Також проведіть моделювання з декількома нерухомими насінням, випадково розташованими в просторі, і спостерігайте за тим, як кілька кластерів взаємодіють один з одним на макроскопічних масштабах.
Для вашої інформації, заповнений код симулятора Python моделі DLA доступний за адресою http://sourceforge.net/projects/pycx/files/, але спочатку слід спробувати реалізувати власний код симулятора.
Це досить просунута, складна вправа про колективну поведінку груп тварин, таких як пташині флоки, рибні школи та рої комах, що є популярним предметом досліджень, який широко моделювався та вивчався за допомогою ПРО. Одна з найбільш ранніх обчислювальних моделей такої колективної поведінки була запропонована комп'ютерним вченим Крейгом Рейнольдсом наприкінці 1980-х років [86]. Рейнольдс придумав набір простих поведінкових правил для агентів, що рухаються в безперервному просторі, які можуть відтворювати дивно природне на вигляд флок поведінку птахів. Його модель називалася пташиноїдами, або коротко «Боіди». Алгоритми, що використовуються в Boids, широко використовуються в індустрії комп'ютерної графіки для автоматичного створення анімації природних рухів тварин у флоках (наприклад, кажанів у фільмах Бетмена). Динаміка боїдів породжується наступними трьома основними поведінковими правилами (рис.19.2.1):
- Агенти згуртованості, як правило, спрямовані до центру маси місцевих сусідів.
- Агенти вирівнювання, як правило, керують, щоб вирівняти свої напрямки із середньою швидкістю місцевих сусідів.
- Агенти поділу намагаються уникати зіткнень з місцевими сусідами.
Спроектуйте ПРО колективної поведінки з цими трьома правилами та реалізуйте його симуляторний код. Проводьте моделювання, систематично змінюючи відносні сильні сторони трьох вищезазначених правил, і дивіться, як змінюється колективна поведінка.
Ви також можете імітувати колективну поведінку населення, в якій кілька типів агентів змішуються між собою. Відомо, що взаємодії між кінетично різними типами роїння можуть виробляти різні нетривіальні динамічні закономірності [87].
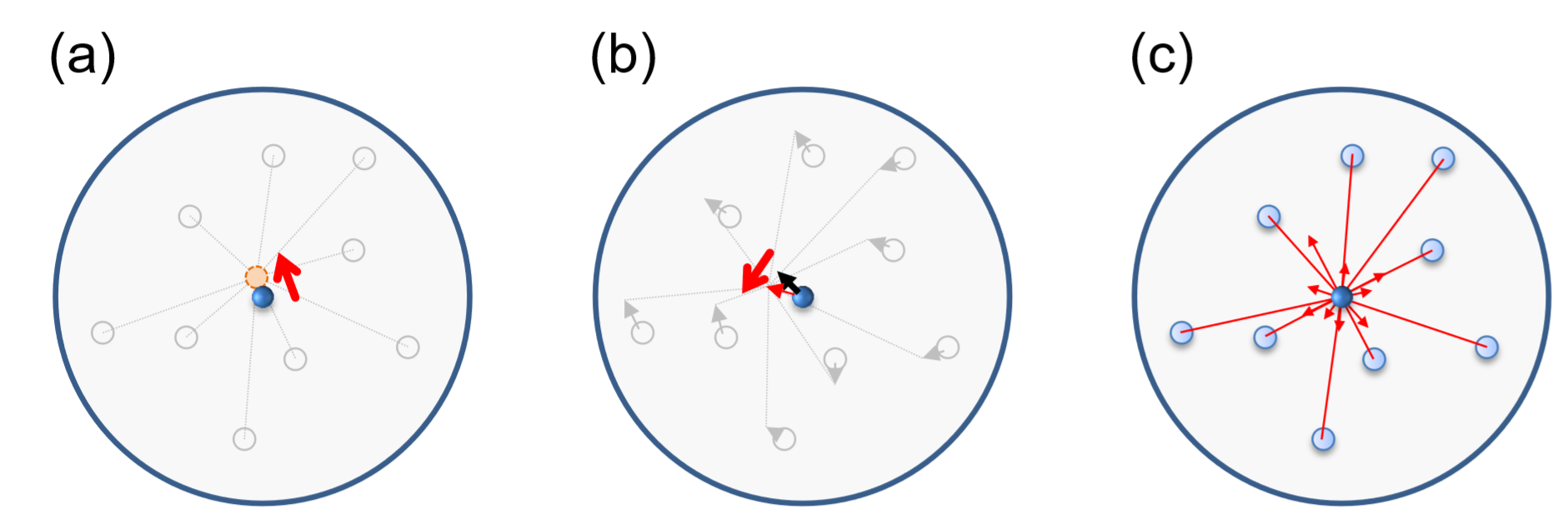 Малюнок\(\PageIndex{2}\) Три основні правила поведінки Боїдів. (а) Згуртованість. (б) Вирівнювання. (c) Поділ.
Малюнок\(\PageIndex{2}\) Три основні правила поведінки Боїдів. (а) Згуртованість. (б) Вирівнювання. (c) Поділ.