6.22: Стиснення та Кодекс Хаффмана
- Page ID
- 33170

- Алгоритм кодування джерела Хаффмана є доказово максимально ефективним.
Теорема про кодування джерела Шеннона має додаткові програми в стисненні даних. Тут у нас є символічне джерело сигналу, як комп'ютерний файл або зображення, що ми хочемо представляти з якомога меншою кількістю бітів. Схеми стиснення, які призначають символи бітовим послідовностям, відомі як без втрат, якщо вони підкоряються теоремі кодування джерела; вони втрачаються, якщо вони використовують менше бітів, ніж ентропія алфавіту. Використання схеми стиснення з втратами означає, що ви не можете відновити символічний сигнал із стисненої версії, не викликаючи певної помилки. Можливо, вам буде цікаво, чому хтось хоче навмисно створювати помилки, але схеми стиснення з втратами часто використовуються там, де ефективність, отримана при представленні сигналу, переважує значення помилок.
Теорема про кодування джерела Шеннона стверджує, що символічні сигнали вимагають в середньому принаймні H (A) кількість бітів для представлення кожного з його значень, які є символами, витягнутими з алфавіту A. У модулі на теоремі кодування джерела ми знаходимо, що використання так званого кодера з фіксованою швидкістю джерела, який виробляє фіксовану кількість бітів/символ, може бути не найефективнішим способом кодування символів у біти. Те, що не обговорюється, є процедура проектування ефективного кодера джерела: один гарантовано видасть найменшу кількість бітів/символ в середньому. Цей вихідний кодер не є унікальним, і один підхід, який досягає цієї межі, є алгоритм кодування джерела Хаффмана.
У перші роки теорії інформації гонка була першою, хто знайшов доказово максимально ефективний алгоритм кодування джерела. Перегони виграв тодішній аспірант MIT Девід Хаффман в 1954 році, який працював над проблемою як проект у своєму курсі теорії інформації. Ми впевнені, що він отримав «А».
- Створіть вертикальну таблицю для символів, найкраща впорядкованість - у порядку зменшення ймовірності.
- Сформуйте бінарне дерево праворуч від таблиці. Бінарне дерево завжди має дві гілки на кожному вузлі. Побудуйте дерево шляхом об'єднання двох символів найменших ймовірностей на кожному рівні, роблячи ймовірність вершини рівною сумі ймовірностей об'єднаних вузлів. Якщо більше двох вузлів/символів мають найменшу ймовірність на заданому рівні, виберіть будь-які два; ваш вибір не вплине\[\overline{B(A)} \nonumber \]
- На кожному вузлі позначте кожну з виходять гілок двійковим числом. Бітова послідовність, отримана від переходу від кореня дерева до символу, є його кодом Хаффмана.
Простий чотирисимвольний алфавіт, що використовується в модулі Entropy та Source Coding, має чотирисимвольний алфавіт з наступними ймовірностями,
\[Pr[a_{0}]=\frac{1}{2} \nonumber \]
\[Pr[a_{1}]=\frac{1}{4} \nonumber \]
\[Pr[a_{2}]=\frac{1}{8} \nonumber \]
\[Pr[a_{3}]=\frac{1}{8} \nonumber \]
і ентропія 1,75 біт. Цей алфавіт має дерево кодування Хаффмана, показане на малюнку 6.22.1
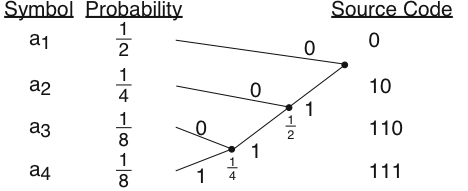
Отриманий таким чином код не є унікальним, оскільки ми могли б позначити гілки, що виходять з кожного вузла по-різному. Середня кількість бітів, необхідних для представлення цього алфавіту, дорівнює 1,75 біт, що є межею ентропії Шеннона для цього вихідного алфавіту. Якби у нас був символічно-значний сигнал
\[s(m)=\left \{ a_{2},a_{3},a_{1},a_{4},a_{1},a_{2,...} \right \} \nonumber \]
Наш код Хаффмана буде виробляти бітовий потік
\[b(n)=101100111010... \nonumber \]
Якби ймовірності алфавіту були різними, явно могло б привести інше дерево, а отже, і інший код. Крім того, ми, можливо, не зможемо досягти межі ентропії. Якби наші символи мали ймовірності
\[Pr[a_{1}]=\frac{1}{2},Pr[a_{2}]=\frac{1}{4},Pr[a_{3}]=\frac{1}{5},\; and\; Pr[a_{4}]=\frac{1}{20} \nonumber \]
Середня кількість бітів/символу, отриманого в результаті алгоритму кодування Хаффмана, дорівнюватиме 1,75 бітам. Однак межа ентропії становить 1,68 біта. Код Хаффмана задовольняє теоремі про кодування джерела - його середня довжина знаходиться в межах одного біта ентропії алфавіту, але ви можете задатися питанням, чи існує кращий код. Девід Хаффман математично показав, що жоден інший код не може досягти більш короткого середнього коду, ніж його. Ми не можемо зробити краще.
Виведіть код Хаффмана для цього другого набору ймовірностей та перевірте заявлену середню довжину коду та ентропію алфавіту.
Рішення
Дерево кодування Хаффмана для другого набору ймовірностей ідентично такому для першого (рис. 6.22.1). Середня довжина коду
\[\frac{1}{2}1+\frac{1}{4}2+\frac{1}{5}3+\frac{1}{20}3=1.75\; bits \nonumber \]
Розрахунок ентропії простий:
\[H(A)=-\left ( \frac{1}{2}\log_{2}\frac{1}{2}+\frac{1}{4}\log_{2}\frac{1}{4}+\frac{1}{5}\log_{2}\frac{1}{5}+\frac{1}{20}\log_{2}\frac{1}{20}\right )=1.68\; bits \nonumber \]