7.1: Колокати
- Last updated
- Save as PDF
- Page ID
- 92324

(Орфографічне) слово відіграє центральну роль у корпусній лінгвістиці. Як було запропоновано в розділі 4, це в немалій частині через те, що всі тіла, які б додаткові анотації не були додані, складаються з орфографічно представленої мови. Це дозволяє легко отримати словоформи. Кожна програма узгодження пропонує можливість пошуку рядка символів - насправді деякі обмежуються цим видом запиту.
Однак акцент на словах також обумовлений тим, що результати корпусних лінгвістичних досліджень швидко показали, що слова (окремо і в групах) більш цікаві і показують більш складну поведінку, ніж передбачаються традиційні, орієнтовані на граматику теорії мови. Область, в якій це дуже очевидно, і, отже, стала однією з найбільш досліджених областей у корпусній лінгвістиці, - це спосіб поєднання слів, утворюючи так звані колокації.
Ця глава повністю присвячена обговоренню колокації. Спочатку це буде здаватися дещо різким зміщенням від обговорюваних нами досі тем і явищ — може бути навіть не відразу очевидним, наскільки вони вписуються у визначення корпусної лінгвістики як «дослідження лінгвістичних досліджень» питань, які були оформлені з точки зору умовного. поширення лінгвістичних явищ у мовному корпусі», який був представлений наприкінці глави 2. Однак більш уважний погляд покаже, що вивчення співіснування слів і/або словоформ - це просто особливий випадок саме такого роду дослідницької програми.
7.1 Колокати
Тривіально тексти не є випадковими послідовностями слів. Існує кілька факторів, що впливають на ймовірність появи двох (або більше) слів поруч один з одним.
По-перше, спільне виникнення слів у послідовності обмежується граматичними міркуваннями. Наприклад, за певним артиклем не може слідувати інший певний артикль або дієслово, а лише іменник, прикметник, що модифікує іменник, прислівник, що модифікує такий прикметник, або пост-визначник. Так само перехідне дієслово вимагає прямого об'єкта у вигляді іменникової фрази, тому - за винятком випадків, коли прямий об'єкт є до- або після посади - за ним слідуватиме слово, яке може зустрічатися на початку іменної фрази (наприклад, займенник, визначник, прикметник або іменник).
По-друге, спільне виникнення слів обмежується смисловими міркуваннями. Наприклад, перехідний дієслово пити вимагає прямого об'єкта, що посилається на рідину, тому цілком ймовірно, що за ним слідуватимуть такі слова, як вода, пиво, кава, отрута тощо, і малоймовірно, що за ним слідуватимуть такі слова, як хліб, гітара, камінь, демократія тощо Такі обмеження трактуються як граматичне властивість слів (зване обмеженнями вибору) в деяких теоріях, але вони також можуть бути вираженням наших світових знань, що стосуються діяльності пиття.
Нарешті, і пов'язане з проблемою світового знання, спільна поява слів обмежується актуальними міркуваннями. Слова відбуватимуться в послідовностях, які відповідають змісту, який ми намагаємося висловити, тому цілком ймовірно, що спільні слова змісту будуть надходити з тієї ж області дискурсу.
Однак давно відзначено, що слова не розподіляються випадковим чином навіть в межах граматики, лексичної семантики, світового пізнання, комунікативного наміру. Натомість дане слово матиме спорідненість до одних слів та нездужання до інших, які ми не могли передбачити, враховуючи набір граматичних правил, словник та думку, яку потрібно висловити. Одне з перших принципових обговорень цього явища зустрічається в Ферті (1957). На прикладі слова ass (у значенні «ослик») він обговорює те, яким чином те, що він називає звичними співвідношеннями, сприяють значенню слів:
Одне зі значень дупи - це його звична колокація з безпосередньо передує вам дурним, і з іншими фразами адреси або особистого посилання... Є лише обмежені можливості колокації з попередніми прикметниками, серед яких найпоширенішими є дурні, вперті, дурні, жахливі, зрідка кричущі. Молоді зустрічаються набагато частіше, ніж старі. (Ферт 1957:194f)
Зауважимо, що Ферт, хоча і пише задовго до появи корпусної лінгвістики, явно відноситься до частоти як до характеристики колокацій. Швидко розглядалася можливість використання частоти як частини визначення колокатів, а отже, як способу їх ідентифікації. Halliday (1961) забезпечує те, що, ймовірно, є першим строго кількісним визначенням (див. також Church & Hanks (1990) для більш пізнього всеосяжного кількісного обговорення):
Collocation - це синтагматична асоціація лексичних предметів, кількісних, текстово, оскільки ймовірність того, що там відбудеться, при n видаляє (відстань n лексичних предметів) від елемента x, елементи a, b, c... Будь-який даний елемент, таким чином, входить в діапазон колокації, пункти, з якими він розміщений, варіюються від більш до менш ймовірних... (Відпустка 1961:276)
7.1.1 Колокація як кількісне явище
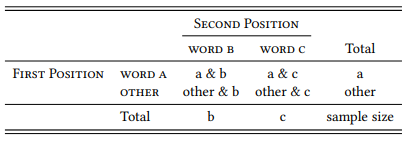
По суті, тоді колокація - це лише особливий випадок кількісного корпусу лінгвістичного дослідження, прийнятого в цій книзі: запитати, чи утворюють два слова колокацію (або: є колокатами один одного), - це запитати, чи зустрічається одне з цих слів у певному положенні частіше, ніж очікувалося випадково за умови, що інше слово зустрічається в структурно або послідовно пов'язаному положенні. Іншими словами, ми можемо вирішити, чи можна розглядати два слова a та b як колокати на основі таблиці надзвичайних ситуацій, подібної до таблиці 7.1. ПЕРША ПОЗИЦІЯ в послідовності трактується як залежна змінна, з двома значеннями: цікавить нас слово (тут: WORD A), і всі ІНШІ слова. ДРУГА ПОЗИЦІЯ розглядається як незалежна змінна, знову ж таки, з двома значеннями: слово, яке нас цікавить (тут: WORD B), і всі ІНШІ слова (звичайно, не має значення, яке слово ми розглядаємо як залежне, а яке як незалежну змінну, якщо тільки наша дослідницька конструкція не передбачає конкретну причину). 1
Таблиця 7.1: Колокація

На основі такої таблиці ми можемо визначити стан колокації даної пари слів. Наприклад, ми можемо запитати, чи був Ферт правий щодо твердження про те, що дурна дупа - це колокація. Необхідні дані наведені в таблиці 7.2: Як обговорювалося вище, залежною змінною є ПЕРША ПОЗИЦІЯ в послідовності, зі значеннями SILLY і ¬SILLY (тобто всі слова, які не є ass); незалежною змінною є SECOND POSITION в послідовності, зі значеннями ASS і ¬ASS.
Таблиця 7.2: Спільна поява дурних і дурних в BNC

Поєднання дурна дупа дуже рідкісна в англійській мові, зустрічається всього сім разів у слові BNC 98 363 783, але очікувані частоти в таблиці 7.2 показують, що це набагато частіше, ніж повинно бути, якщо слова співіснували випадковим чином - в останньому випадку комбінація повинна мати відбувалося всього 0,01 рази (тобто зовсім не). Різниця між спостережуваної і очікуваної частотами вельми істотна (2 = 6033,8, df = 1, p < 0,001). Зауважте, що ми використовуємо тут тест σ 2, тому що ми вже знайомі з ним. Однак це не найкорисніший тест з метою виявлення колокацій, тому кращі варіанти ми обговоримо нижче.
Взагалі кажучи, метою кількісного аналізу колокацій є виявлення для даного слова тих інших слів, які характерні для його контексту вживання. У таблицях 7.1 і 7.2 представлений найбільш простий спосіб зробити це: ми просто порівнюємо частоту, з якою два слова співіснують, з частотами, з якими вони відбуваються в корпусі загалом. Іншими словами, дві умови, за якими ми досліджуємо розподіл слова, є «поруч із заданим іншим словом» та «скрізь». Це означає, що сам корпус функціонує як своєрідне нейтральне умова управління, хоча і дещо нерозбірливе: порівняння частоти слова поруч з якимось іншим словом з його частотою у всій іншій частині корпусу трохи схоже на порівняння експериментальної групи суб'єктів, яким було дано особливе звернення до контрольної групи, що складається з усіх інших людей, які живуть в одному місті.
Часто нас цікавить розподіл слова за двома конкретними умовами - у випадку колокації, розподілом по безпосередніх контекстах двох семантично пов'язаних слів. Може бути більш проникливим порівняти прикметники, що відбуваються поруч з дупою, з тими, що виникають поруч із грубим синонімом ослик або вищий термін тварина. Очевидно, що той факт, що дурне трапляється частіше з дупою, ніж з ослом чи твариною, цікавіший, ніж той факт, що дурне частіше трапляється з дупою, ніж з каменем чи демократією. Так само той факт, що дурне трапляється з дупою частіше, ніж дитяча, цікавіший, ніж той факт, що дурне трапляється з дупою частіше, ніж дорогоцінний або парламентський.
У таких випадках ми можемо змінити таблицю 7.1, як показано в таблиці 7.3, щоб визначити колокати, які значно відрізняються між двома словами. Встановленого терміну для таких колокатів немає, тому ми будемо називати їх диференціальними коллокатами тут 2 (метод заснований на Church et al. 1991).
Таблиця 7.3: Визначення диференціальних колокатів
Оскільки колокація дурна дупа та слово ass взагалі настільки нечасті в BNC, давайте використаємо інший іменник, щоб продемонструвати корисність цього методу, гра слів. Ми можемо говорити про дурну гру (и) або дитячу гру (и), але ми можемо відчути, що остання є більш типовою, ніж перша. Відповідні частоти леми, щоб випробувати це почуття, наведені в таблиці 7.4.
Таблиця 7.4: Дитяча гра проти дурної гри (леми) в BNC

Послідовності дитяча гра (и) і дурна гра (и) обидва відбуваються в BNC. Обидві комбінації, взяті окремо, значно частіші, ніж очікувалося (ви можете перевірити це самостійно, використовуючи частоти таблиці 7.4, загальну частоту леми гри в BNC (20 627) та загальну кількість слів у BNC, наведену в таблиці 7.2 вище). Послідовність леми дурна гра є більш частою, що може привести нас до припущення, що це сильніша колокація. Однак пряме порівняння показує, що це пов'язано з тим, що нерозумно в цілому частіше, ніж дитяче, що робить комбінацію дурної гри більш імовірною, ніж комбінація дитяча гра, навіть якщо три слова були розподілені випадковим чином. Різниця між спостережуваною та очікуваною частотами говорить про те, що дитяча сильніше асоціюється з грою (ами), ніж дурною. Різниця значна (2 = 6,49, df = 1, p < 0,05).
Дослідники розрізняються щодо того, на яких типах спільного виникнення вони зосереджуються при виявленні колокацій. Деякі розглядають спільне виникнення як чисто послідовне явище, що визначає колокати як слова, які спільно зустрічаються частіше, ніж очікувалося в межах заданого проміжку. Деякі дослідники вимагають проміжок 1 (тобто слова повинні зустрічатися безпосередньо поруч один з одним), але багато хто допускає більші прольоти (п'ять слів є відносно типовим розміром прольоту).
Інші дослідники розглядають спільне явище як структурне явище, тобто вони визначають колокати як слова, які зустрічаються частіше, ніж очікувалося, у двох споріднених позиціях у певній граматичній структурі, наприклад, позиції прикметника та іменника у іменних фразах форми [Det Adj N] або дієслово і позиція іменника в перехідних дієслівних словосполученнях виду [V [NP (Det) (Adj) N]]. 3 Однак замість того, щоб обмежувати визначення однією з цих можливостей, здається більш правдоподібним визначити термін належним чином у контексті конкретного дослідницького питання. У наведених вище прикладах ми використовували чисто послідовне визначення, яке просто вимагало, щоб слова відбувалися поруч один з одним, не звертаючи уваги на їх слово-клас або структурні відносини; враховуючи, що ми розглядали комбінації прикметник-іменник, безумовно, було б розумно обмежити наш пошук параметри прикметників, що модифікують іменник ass, незалежно від того, чи втручалися інші прикметники, наприклад, у вирази, такі як дурна стара дупа, яку наш запит пропустив би, якби вони відбулися в BNC (вони цього не роблять).
Мало стати зрозумілим, що конструкції в таблицях 7.1 та 7.3 по суті є варіантами загальної дослідницької конструкції, введеної в попередніх розділах і використовуваної як основа визначення корпусної лінгвістики: вона має дві змінні, ПОЗИЦІЯ 1 та ПОЗИЦІЯ 2, обидві з яких мають два значення, а саме WORD X VS. ІНШІ СЛОВА (або, у випадку диференціальних колокатів, WORD X VS. СЛОВО У). Мета полягає в тому, щоб визначити, чи є значення WORD A частіше для ПОЗИЦІЇ 1 за умови, що СЛОВО B зустрічається в ПОЗИЦІЇ 2, ніж за умови, що інші слова (або конкретне інше слово) зустрічаються в ПОЗИЦІЇ 2.
7.1.2 Методологічні проблеми колокаційних досліджень
Іноді нас може цікавити окрема пара колокатів, таких як дурна дупа, або невеликий набір таких пар, таких як всі пари прикметників-іменник з дупою як іменник. Однак набагато більш імовірно, що нас будуть цікавити великі набори колокованих пар, таких як усі пари прикметник-іменник або навіть усі пари слів у даному корпусі. Це має низку методологічних наслідків щодо практичності, статистичної оцінки та епістемологічного статусу колокаційних досліджень.
а. практичність. У практичному плані аналіз великих чисел потенційних колокацій вимагає створення великої кількості таблиць непередбачених ситуацій і піддання їх тесту 2 або якомусь іншому відповідному статистичному тесту. Це стає неймовірно трудомістким дуже швидко, і тому його потрібно певним чином автоматизувати.
Існують узгоджуючі програми, які пропонують деякі вбудовані статистичні тести, але вони, як правило, досить сильно обмежують наші варіанти, як з точки зору тестів, які вони дозволяють нам виконувати, так і з точки зору даних, на яких проводяться тести. Той, хто вирішить взяти участь у дослідженнях колокації (або деяких з масштабних лексичних областей досліджень, описаних у наступному розділі), повинен ознайомитися хоча б з простими варіантами автоматизації статистичного тестування, пропонованими додатками електронних таблиць. Ще краще, вони повинні інвестувати кілька тижнів (або, в гіршому випадку, місяців), щоб вивчити мову сценаріїв, як Perl, Python або R (останній - це поєднання статистичного програмного забезпечення та середовища програмування, яке ідеально підходить майже для будь-якого завдання, яке ми, ймовірно, зіткнемося як корпусні лінгвісти).
b. статистичне оцінювання. У статистичному плані аналіз великої кількості потенційних колокацій вимагає від нас пам'ятати, що зараз ми проводимо кілька тестів значущості на одному наборі даних. Це означає, що ми повинні коригувати наші рівні значущості. Згадайте приклад монетки-перегортання: ймовірність отримати ряд з однієї голови і дев'яти хвостів дорівнює 0,009765. Якщо ми перевернемо монету десять разів і отримаємо цей результат, ми могли б таким чином відхилити нульову гіпотезу з ймовірністю помилки 0.010744, тобто близько 1 відсотка (тому що нам доведеться додати ймовірність отримання десяти хвостів, 0.000976). Це значно нижче рівня, необхідного для отримання статистичної значущості. Однак, якщо ми виконаємо сто серій з десяти монет-сальто і одна з цих серій складається з однієї голови і дев'яти хвостів (або десяти хвостів), ми не могли б відхилити нульову гіпотезу з тією ж впевненістю, оскільки ймовірність 0,010744 означає, що ми очікуємо, що один такий ряд відбудеться випадково. Це не проблема до тих пір, поки ми не привласнюємо цей один результат зі ста будь-якого особливого значення. Однак, якщо ми повинні були визначити набір з 100 колокацій з p -значеннями 0,001 в корпусі, ми потенційно розглядаємо всі з них як важливі, хоча дуже ймовірно, що принаймні один з них досяг цього рівня значущості випадково.
Щоб цього уникнути, ми повинні виправити наші рівні значущості при виконанні декількох тестів на одному і тому ж наборі даних. Як обговорювалося в розділі 6.6.1 вище, найпростішим способом зробити це є корекція Бонферроні, яка полягає в поділі умовно узгоджених рівнів значущості на кількість тестів, які ми виконуємо. Як зазначається в розділі 6.6.1, це надзвичайно консервативна корекція, яка може ускладнити досягнення значущості будь-якої даної колокації.
Звичайно, питання полягає в тому, наскільки важливою є роль p -значень у дизайні, де нашою головною метою є виявлення колокатів та впорядкування їх з точки зору сили колокації. До цього моменту я зараз перейду, але перш ніж я це зроблю, обговоримо третій із трьох наслідків масштабного тестування на колокацію, методологічний.
c. гносеологічні міркування. До цього моменту ми представили дуже вузький погляд на науковий процес, заснований (загалом) на дослідницькому циклі Попперія, де ми формулюємо дослідницьку гіпотезу, а потім перевіряємо її (або безпосередньо, шукаючи зустрічні приклади, або, частіше, намагаючись відхилити відповідний нуль гіпотеза). Це називається дедуктивним методом. Однак, як коротко обговорюється в розділі 3, існує альтернативний підхід до наукових досліджень, який починається не з гіпотези, а з загальних питань на кшталт «Чи існують зв'язки між конструкціями в моїх даних?» і «Якщо так, то які ці відносини?». Потім дослідження полягає у застосуванні статистичних процедур до великих обсягів даних та вивченні результатів на предмет цікавих закономірностей. Оскільки електронні накопичувачі та обчислювальні потужності стали дешевшими та доступнішими, цей підхід - дослідницький або індуктивний підхід - стає все більш популярним у всіх галузях науки, особливо в соціальних науках. Було б дивно, якби корпусна лінгвістика була винятком, і справді, це не так. Особливо область колокаційних досліджень, як правило, розвідувальна.
В принципі, немає нічого поганого в дослідницьких дослідженнях - навпаки, було б нерозумно не використовувати великі обсяги мовних даних та величезну обчислювальну потужність, яка стала доступною та доступною за останні тридцять років. Насправді іноді важко уявити правдоподібну гіпотезу для колокаційних дослідницьких проектів. Яку гіпотезу ми б сформулювали, перш ніж визначити всі колокації в LOB або якомусь спеціалізованому корпусі (наприклад, корпус ділового листування, корпус зв'язку управління польотом або корпус мови, що вивчає)? 4 Незважаючи на це, зрозуміло, що результати такого колокаційного аналізу дають цікаві дані, як для практичних цілей (побудова словників або навчальних матеріалів для ділової англійської або авіаційної англійської мови), вилучення термінології з метою стандартизації, навчання природничо-мовної. системи обробки) і в теоретичних цілях (розуміння природи ситуаційної варіації мови або навіть природи мови в цілому).
Але є і небезпека: більшість статистичних процедур дадуть певний статистично значущий результат, якщо ми застосуємо їх до досить великого набору даних, і колокаційні методи, безумовно, будуть. Якщо ми не зацікавлені виключно в описі, найважливіше питання полягає в тому, чи є ці результати значущими. Якщо ми почнемо з гіпотези, ми обмежені в нашій інтерпретації даних необхідністю пов'язати наші дані з цією гіпотезою. Якщо ми не почнемо з гіпотези, ми можемо інтерпретувати наші результати без будь-яких обмежень, що, враховуючи схильність людини бачити закономірності всюди, може призвести до дещо довільних пост-hoc інтерпретацій, які можна було б легко змінити, навіть змінити, якщо результати були різними, і тому говорять нас дуже мало про досліджуване явище або мову в цілому. Таким чином, це, мабуть, гарна ідея сформулювати хоча б деякі загальні очікування, перш ніж робити масштабний аналіз колокації.
Навіть якщо ми почнемо із загальних очікувань або навіть з конкретної гіпотези, ми часто виявляємо додаткові факти про наше явище, які виходять за рамки того, що є актуальним у контексті нашого оригінального дослідницького питання. Наприклад, перевіряючи твердження BNC Firth, що найчастіші коллокати дупи є дурними, норовливими, дурними, жахливими та кричущими, і що молодий «набагато частіше», ніж старий, ми виявляємо, що нерозумно - це справді найчастіший прикметник, але цей норовливий, дурний і кричущий взагалі не відбувається, що жахливо відбувається лише один раз, і що молоді та старі обидва трапляються двічі. Натомість часті прикметникові розмови (ігнорування диких, що посідає друге місце, що стосується виключно фактичних ослів), є помпезними і поганими. Помпезний насправді не відповідає семантиці, яку прикметники Ферта пропонують, і може вказувати на те, що семантичний перехід від «дурості» до «самозначущості», можливо, відбувся між 1957 та 1991 роками (коли BNC був зібраний).
Це, звичайно, нова гіпотеза, яку можна (і потрібно) досліджувати, порівнюючи дані 1950-х і 1990-х років. Він має деяку початкову правдоподібність в тому, що прикметники пустують, лицемірні, монокльовані та упевнені також зустрічаються з дупою в BNC, але не згадуються Фертом. Однак важливо розглядати це як гіпотезу, а не результат. Те ж саме стосується поганої дупи, яка говорить про те, що американське почуття дупи («дно») та/або американський прикметник badass (який часто пишеться як два окремі слова), можливо, почали вводити британську англійську мову. Щоб пройти перевірку, ці ідеї - і будь-які ідеї, отримані в результаті дослідницького аналізу даних, повинні бути перетворені на перевірені гіпотези, а задіяні конструкції повинні бути реалізовані. Найважливіше, що вони повинні бути перевірені на новому наборі даних - якби ми проводили циркулярне тестування на тих самих даних, з яких вони були отримані, ми б, очевидно, виявили їх підтвердженими.
7.1.3 Розміри ефектів для колокацій
Як згадувалося вище, тестування значущості (хоча і не без його використання) не обов'язково є нашою першочерговою проблемою при дослідженні колокацій. Натомість дослідникам часто потрібен спосіб оцінки сили зв'язку між двома (або більше) словами, або, по-іншому, розмір ефекту їх спільного виникнення (нагадаємо з глави 6, що значення та розмір ефекту не однакові). Запропоновано та досліджено широкий спектр таких заходів об'єднання. Зазвичай вони розраховуються на основі (деякої або всієї) інформації, що міститься в таблицях надзвичайних ситуацій, як у таблицях 7.1 та 7.3 вище.
Давайте розглянемо деякі з найпопулярніших і/або найкорисніших з цих заходів. Формули я буду представляти з посиланням на таблицю в таблиці 7.5, тобто O 11 означає спостережувану частоту верхньої лівої осередку, Е 11 її очікувану частоту, R 1 перший рядок загальний, C 2 другий стовпець загальний і так далі. Зверніть увагу, що другий стовпець буде позначений ІНШИМИ СЛОВАМИ у випадку звичайних колокацій, а WORD C у випадку диференціальних колокацій. Заходи асоціації можуть застосовуватися до обох видів дизайну.
Таблиця 7.5: Загальна таблиця 2 на 2 для колокаційних досліджень

Тепер все, що нам потрібно - це хороший приклад для демонстрації розрахунків. Давайте використаємо послідовність прикметників-іменників хороший приклад з корпусу LOB (але любителям коней не потрібно боятися, ми повернемося до кінських тварин та їх властивостей нижче).
Таблиця 7.6: Спільне виникнення блага і приклад в LOB

Міри колокаційної сили розрізняються щодо даних, необхідних для їх обчислення, їх обчислювальної інтенсивності та, що найважливіше, якості їх результатів. Зокрема, багато заходів, особливо ті, які легко обчислити, мають проблеми з рідкісними колокаціями, особливо якщо окремі слова, з яких вони складаються, також рідкісні. Після того, як ми запровадили заходи, ми будемо порівнювати їх ефективність з особливим акцентом на те, як вони мають справу (або не справляються) з такими рідкісними подіями.
7.1.3.1 Чі-квадрат
Перша міра асоціації - це старе знайомство: статистика хі-квадрата, яку ми широко використовували в Главі 6 та в розділі 7.1.1 вище. Я не буду демонструвати це знову, але значення хі-квадрата для таблиці 7.6 було б 378,95 (при 1 ступені свободи це означає, що p < 0.001, але нас тут не турбують p -значення).
Нагадаємо, що статистика тесту хі-квадрата - це не розмір ефекту, а те, що її потрібно розділити на загальну таблицю, щоб перетворити її в одиницю. Поки ми отримуємо всі наші дані про колокацію з одного корпусу, це не матиме різниці, оскільки загальна сума таблиці завжди буде однаковою. Однак це не завжди так. Там, де розміри таблиці відрізняються, ми можемо розглянути можливість використання значення phi замість цього. Я не знаю жодних досліджень, що використовують фі як міру асоціації, і насправді сама статистика хі-квадрат також не використовується широко. Це пов'язано з тим, що у нього є серйозна проблема: нагадайте, що вона не може бути застосована, якщо більше 20 відсотків комірок таблиці надзвичайних ситуацій містять очікувані частоти менше 5 (у випадку колокатів це означає, що навіть не одна з чотирьох комірок таблиці 2-на-2). Однією з причин цього є те, що він різко завищує розмір ефекту і значимість таких подій, і рідкісних подій в цілому. Оскільки колокації часто є відносно рідкісними подіями, це робить статистику хі-квадрата поганим вибором як міри асоціації.
7.1.3.2 Взаємна інформація
Взаємна інформація є одним з найстаріших заходів колокації, часто використовується в обчислювальній лінгвістиці і часто реалізується в програмному забезпеченні для колокації. Це наведено в (1) у версії, заснованій на Церкві та Хенксі (1990): 5
(1)
Застосовуючи формулу до нашої таблиці, отримуємо наступне:

У нашому випадку ми розглядаємо випадки, коли WORD A і WORD B відбуваються безпосередньо поруч один з одним, тобто розмір прольоту дорівнює 1. При погляді на більший проміжок (що часто робиться в дослідженнях колокації), ймовірність зіткнутися з певним коллокатом збільшується, оскільки є більше слотів, які потенційно можуть виникнути. Статистику MI можна регулювати для більших розмірів прольоту наступним чином (де S - розмір прольоту):
(2)
Взаємна інформаційна міра страждає від тієї ж проблеми, що й статистика φ 2: вона переоцінює важливість рідкісних подій. Оскільки вона все ще досить широко поширена в колокаційних дослідженнях, нам все ж може знадобитися в ситуаціях, коли ми хочемо порівняти власні дані з результатами опублікованих досліджень. Однак зауважте, що існують версії міри ІМ, які дадуть різні результати, тому нам потрібно переконатися, що ми використовуємо ту саму версію, що і дослідження, з яким ми порівнюємо наші результати. Але якщо немає нагальної причини, ми взагалі не повинні використовувати взаємну інформацію.
7.1.3.3 Випробування на коефіцієнт правдоподібності
Значення G тесту коефіцієнта ймовірності журналу є одним з найпопулярніших - можливо, найпопулярніших - асоціаційних заходів у колокаційних дослідженнях, знайдених у багатьох центральних дослідженнях у цій галузі та часто реалізованого в програмному забезпеченні для колокації. Нижче наведено часто зустрічається форма (Читати & Крессі 1988:134):
(3)
Для того щоб обчислити міру G, обчислюємо для кожної клітинки натуральний логарифм спостережуваної частоти, поділений на очікувану частоту, і множимо його на спостережувану частоту. Потім складаємо результати для всіх чотирьох клітин і множимо результат на дві. Зверніть увагу, що якщо спостережувана частота даної комірки дорівнює нулю, то вираз O i/Ei, звичайно, теж буде дорівнювати нулю. Оскільки логарифм нуля не визначено, це призведе до помилки при обчисленні. Таким чином, log (0) просто визначається як нуль при застосуванні формули в (3).
Застосовуючи формулу в (3) до даних таблиці 7.6, отримуємо наступне:

Значення G давно відомо більш надійним, ніж тест 2 при роботі з невеликими зразками і малими очікуваними частотами (Read & Cressie 1988:134ff). Це призвело до того, що Даннінг (1993) запропонував його як асоціаційний захід спеціально, щоб уникнути завищення рідкісних подій, які страждають на тест 2, взаємну інформацію та інші заходи.
7.1.3.4 Мінімальна чутливість
Мінімальна чутливість була запропонована Педерсеном (1998) як потенційно корисний захід, особливо для виявлення асоціацій між змістом слів:
(4)
Ми просто ділимо спостережувану частоту колокації на частоту першого слова (R 1) та другого слова (C 1) і використовуємо меншу з двох як міру асоціації. Для даних у таблиці 7.6 це дає нам наступне:

Окрім того, що він надзвичайно простий у обчисленні, він має перевагу в діапазоні від нуля (слова ніколи не зустрічаються разом) до 1 (слова завжди трапляються разом); Віхманн також стверджував, що (2008) найкраще корелює з даними часу читання при застосуванні до комбінацій слів та граматичних конструкцій (див. Глава 8). Однак він також схильний переоцінювати важливість рідкісних колокацій.
7.1.3.5 Точний тест Фішера
Точний тест ішера вже згадувався в розділі 6 як альтернатива тесту 2, який обчислює ймовірність помилки безпосередньо шляхом складання ймовірності спостережуваного розподілу та всіх розподілів, які відхиляються від нульової гіпотези далі в тому ж напрямку. Педерсен (1996) пропонує використовувати це значення p як міру асоціації, оскільки воно не робить жодних припущень про нормальність і навіть краще справляється з рідкісними подіями, ніж G. Stefanowitsch & Gries (2003:238—239) додати, що він має перевагу враховувати як величину відхилення від очікуваних частот і розміру вибірки.
Є деякі практичні недоліки точного тесту Фішера. По-перше, це обчислювально-дорого - його неможливо обчислити вручну, за винятком дуже маленьких таблиць, оскільки він передбачає обчислення факторіалів, які дуже швидко стають дуже великими. Заради повноти, ось (одна версія) формула:
(5)
Очевидно, що застосувати цю формулу безпосередньо до даних у таблиці 7.6 неможливо, оскільки ми не можемо реально обчислити факторіали для 236 або 836, не кажучи вже про 1 011 904. Але якби ми могли, ми б виявили, що р -значення для таблиці 7.6 0.000000000001188.
Програми для електронних таблиць зазвичай не пропонують точний тест Фішера, але всі основні програми статистики роблять. Однак, як правило, точне p -значення не повідомляється за межі певної кількості знаків після коми. Це означає, що часто немає способу ранжирування найбільш сильно асоційованих колокатів, оскільки їх p -значення менше цієї межі. Наприклад, у корпусі LOB є більше 100 коллокатів з точним p -значенням Фішера, яке менше найменшого значення, яке здатний обчислити стандартний комп'ютерний чіп, і більше 5000 коллокатів, які мають p -значення, менші за те, що стандартна реалізація точного тесту Фішера в статистичному програмному пакеті R забезпечить. Оскільки в дослідженнях колокацій нам часто потрібно ранжувати колокації за їх силою, це може стати проблемою.
7.1.3.6 Порівняння заходів асоціації
Давайте подивимося, як порівнюються заходи асоціації, використовуючи набір даних з 20 потенційних колокацій. Натхненні дурною дупою Ферта, всі вони є поєднаннями прикметників з кінськими тваринами. У таблиці 7.7 наведені комбінації та їх частоти в BNC, відсортовані за їх необробленою частотою виникнення (прикметники та іменники показані невеликими прописками тут, щоб підкреслити, що вони є значеннями змінних Word A та Word B, але я, як правило, покажу їх курсивом у решті книги відповідно до лінгвістична традиція).
Всі комбінації абсолютно нормальні, граматичні пари прикметник-іменник, значущі не тільки в конкретному контексті їх фактичного виникнення. Однак я підібрав їх таким чином, щоб вони відрізнялися щодо свого статусу як потенційних колокацій (в сенсі типових сполучень слів). Деякі є сполуками або сполуками, як комбінації (кінь-качалка, троянський кінь, і, в спеціалізованому дискурсі, звичайна зебра). Деякі - такі напівідіоматичні комбінації, які мав на увазі Ферт (дурна попка, помпезна попка). Деякі з них є дуже умовними комбінаціями іменників з прикметником, що позначає властивість, специфічну для цього іменника (скаче кінь, бій віслюк, скаче кінь - перший з них є звичайним способом позначення логотипу марки Ferrari). Деякі лише надають поява напівідіоматичних поєднань (стрибали), насправді нетрадиційний варіант підстрибнутого джек-в-офісі; dumb-fuck donkey, насправді вкрай рідкісна фраза, яка зустрічається лише один раз в документованої історії англійської мови, а саме в книга Trail of the Octopus: Від Бейрута до Локербі - Усередині DIA, і це, ймовірно, звучить як ідіома через алітерацію та смислове відношення до дурної дупи; і монокльована дупа, яка приводить до розуму помпезну дупу, але насправді не дуже умовне поєднання). Нарешті, існує ряд повністю композиційних поєднань, які мають сенс, але не мають ніякого особливого статусу (капаризонований мул, новий кінь, старий ослик, молода зебра, великий мул, самка хінні, вимерла квагга ).
Таблиця 7.7: Деякі колокати форми [ADJ N кінський] (BNC)

Крім того, я вибрав їх для представлення різних типів частотних відносин: деякі з них (відносно) часті, деякі з них дуже рідкісні, для деяких з них або прикметник, або іменник, як правило, досить часті, а для деяких з них жоден з двох не частий.
У таблиці 7.8 показано ранжування цих двадцяти колокацій за п'ятьма заходами асоціації, розглянутими вище. Дещо спрощуючи, хороша міра асоціації повинна ранжувати стилізовані комбінації найвищим (кінь-качалка, троянський кінь, дурна дупа, помпезна попка, шутливий кінь, коник, що скаче кінь), характерні звучання, але нетрадиціоналізовані комбінації десь посередині ( підскочили придурки, осел, стара попка, монокльована попка) і композиційні комбінації найнижчі (звичайна зебра, підстрибали придурки, осел трахкає, стара попка, монокольна попка). Звичайну зебру складно передбачити — це стилізований вираз, але не в загальній мові.
Таблиця 7.8: Порівняння обраних заходів асоціації для колокатів форми [ADJ N кінь] (BNC)

Усі асоціації вимірюють тариф досить добре, загалом кажучи, щодо композиційних виразів — вони, як правило, зустрічаються в нижній третині всіх списків. Там, де є винятки, статистика 2, взаємна інформація та мінімальна чутливість рангу рідкісних випадків вище, ніж вони повинні (наприклад, капаризонований мул, вимерла квагга), тоді як G та p -значення точного тестового рангу Фішера часті випадки вище (наприклад, скаче кінь).
Що стосується некомпозиційних випадків, 2 та взаємна інформація досить погані, переоцінюючи рідкісні комбінації, такі як стрибали, тупий віслюк та монокльована дупа, перераховуючи деякі чіткі випадки колокацій набагато далі за списком ( дурна попка, а, у випадку з ІМ, кінь-качалка). Мінімальна чутливість набагато краща, ранжируючи більшість умовлених випадків у верхній половині списку, а нетрадиціоналізовані далі вниз (за винятком підскочиків, де і окремі слова, і їх поєднання дуже рідкісні). G та Fisher p -value тариф найкраще (без відмінностей у їх ранжируванні виразів), перераховуючи узагальнені випадки вгорі та відмінні, але нетрадиціоналізовані випадки посередині.
Щоб продемонструвати проблеми, які можуть спричинити дуже рідкісні події (особливо ті, де і поєднання, і кожне з двох слів в ізоляції дуже рідкісні), уявіть, що хтось використовував фразу tomfool onager колись у BNC. Оскільки ні прикметник tomfool (синонім дурного), ні іменник онагер (назва підроду ослів Equus hemionus, також відомий як азіатська або азіатська дика дупа) не зустрічаються в BNC де-небудь ще, це дасть нам розподіл в таблиці 7.9.
Таблиця 7.9: Фіктивне виникнення онагера tomfool в BNC

Застосування формул, розглянутих вище, до цієї таблиці дає нам значення 2 98 364 000, значення MI 26,55 та мінімальне значення чутливості 1, розміщуючи цю (гіпотетичну) одноразову комбінацію у верхній частині відповідних рейтингів з широким відривом. Знову ж таки, тест коефіцієнта ймовірності журналу та точний тест Фішера набагато кращі, ставлячи на восьме місце в обох списках (G = 36,81, p exact = 1,02 × 10 −8).
Хоча приклад є гіпотетичним, проблема не в цьому. Він виявляє математичну слабкість багатьох часто використовуваних заходів асоціації. З емпіричної точки зору, це не обов'язково було б проблемою, якби такі випадки, як у таблиці 7.9, були рідкісними в мовних тілах. Однак вони не є. Наприклад, корпус LOB містить майже тисячу таких випадків, включаючи деяких законних кандидатів на колокацію (наприклад, трав'яні заварки, casus belli або субтропічний клімат), але в основному композиційні комбінації (невитончена типографія, турбанований головний убір, пісні з Британії попурі), фрагменти іноземних мов (freie Blicke, l'arbre rouge, palomita blanca) та інші речі, які абсолютно явно не те, що ми шукаємо в дослідженнях колокації. Все це буде відбуватися у верхній частині будь-якого списку collocate, створеного за допомогою статистики, наприклад, φ 2, взаємної інформації та мінімальної чутливості. У великих корпусах, які неможливо перевірити на орфографічні помилки та/або помилки, введені токенізацією, цей список також включатиме сотні таких помилок (частота виникнення яких низька саме тому, що вони є помилками).
Підводячи підсумок, виконуючи колокаційні дослідження, ми повинні використовувати найкращі доступні заходи асоціації. На даний момент це значення p точного тесту Фішера (якщо у нас є засоби для його обчислення), або G (якщо ми цього не робимо, або якщо ми віддаємо перевагу використанню широко прийнятої міри асоціації). Ми будемо використовувати G через більшу частину цієї книги, коли ми маємо справу з колокаціями або колакаційними явищами.
1 Зауважте, що ми використовуємо розмір корпусу як загальну таблицю - строго кажучи, ми повинні використовувати загальну кількість послідовностей двох слів (біграм) у корпусі, яка буде нижчою: Останнє слово в кожному файлі нашого корпусу не матиме сліду за ним, тому нам доведеться відняти останнє слово слово кожного файлу — тобто кількість файлів у нашому корпусі — від загальної кількості. Це навряд чи матиме значну різницю в більшості випадків, але чим коротші тексти в нашому корпусі, тим більша різниця буде. Наприклад, у корпусі твітів, які на момент написання статті обмежені 280 символами, може бути краще виправити загальну кількість біграм описаним способом.
2 Gries (2003b) та Gries & Stefanowitsch (2004) використовують термін відмінний collocate, який був прийнятий деякими авторами; однак багато інших авторів використовують термін відмінні collocate набагато ширше для позначення характерних колокатів слова .
3 Зауважте, що такі словокласи, специфічні для класу слів, іноді називають колігаціями, хоча термін колігація зазвичай відноситься до спільного виникнення слова в контексті певних класів слів, що не є однаковим.
4 Звичайно, ми робимо неявне припущення, що будуть колокати - в певному сенсі це гіпотеза, оскільки ми могли б уявити моделі мови, які не передбачали б їх існування (ми можемо стверджувати, наприклад, що принаймні деякі версії генеративної граматики складають такі моделі). Однак, навіть якщо ми приймаємо це як гіпотезу, це, як правило, не те, що ми зацікавлені в такому дослідженні.
5 Логарифм з основою b заданого числа x - це ступінь, до якої b потрібно підняти, щоб отримати x, так, наприклад, log 10 (2) = 0,30103, тому що 10 0,30103 = 2. Більшість калькуляторів пропонують принаймні вибір між натуральним логарифмом, де основою є число е (приблизно 2.7183) і загальним логарифмом, де основою є число 10; багато калькуляторів і всі основні програми електронних таблиць пропонують логарифми з будь-якою базою. У формулі в (1) нам потрібен логарифм з основою 2; якщо такого немає, ми можемо використовувати натуральний логарифм і розділити результат на натуральний логарифм 2:
