4: Дані та бази даних
- Page ID
- 104043

Цілі навчання
Після успішного завершення цієї глави ви зможете:
- Опишіть відмінності між даними, інформацією та знаннями;
- Опишіть, чому технологія баз даних повинна використовуватися для управління ресурсами даних;
- Визначити термін бази даних і визначити кроки до її створення;
- Охарактеризуйте роль системи управління базами даних;
- Опишіть характеристики сховища даних; і
- Визначте інтелектуальний аналіз даних та опишіть його роль в організації.
Вступ
Ви вже познайомилися з першими двома компонентами інформаційних систем: апаратним і програмним забезпеченням. Однак ці два компоненти самі по собі не роблять комп'ютер корисним. Уявіть, якби ви включили комп'ютер, запустили текстовий процесор, але не змогли зберегти документ. Уявіть, якби ви відкрили музичний плеєр, але не було музики для відтворення. Уявіть, що ви відкриваєте веб-браузер, але веб-сторінок не було. Без даних апаратні та програмні засоби не дуже корисні! Дані є третім компонентом інформаційної системи.
Дані, інформація та знання
Існує багато визначень та теорій щодо даних, інформації та знань. Ці три терміни часто використовуються як взаємозамінні, хоча вони відрізняються своєю природою. Визначено та ілюструємо три терміни з точки зору інформаційних систем.
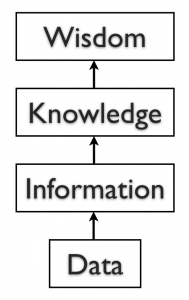 Дані є необробленими фактами і можуть бути позбавлені контексту або наміру. Наприклад, замовлення на продаж комп'ютерів - це фрагмент даних. Дані можуть бути кількісними або якісними. Кількісні дані - це числові, результат вимірювання, підрахунку або будь-якого іншого математичного розрахунку. Якісні дані носять описовий характер. «Рубіново-червоний», колір Ford Focus 2013 року, є прикладом якісних даних. Число також може бути якісним: якщо я скажу вам, що моє улюблене число - 5, це якісні дані, оскільки це описові, а не результат вимірювання чи математичного розрахунку.
Дані є необробленими фактами і можуть бути позбавлені контексту або наміру. Наприклад, замовлення на продаж комп'ютерів - це фрагмент даних. Дані можуть бути кількісними або якісними. Кількісні дані - це числові, результат вимірювання, підрахунку або будь-якого іншого математичного розрахунку. Якісні дані носять описовий характер. «Рубіново-червоний», колір Ford Focus 2013 року, є прикладом якісних даних. Число також може бути якісним: якщо я скажу вам, що моє улюблене число - 5, це якісні дані, оскільки це описові, а не результат вимірювання чи математичного розрахунку.
Інформація - це оброблювані дані, які мають контекст, актуальність та мету. Наприклад, щомісячні продажі, розраховані на основі зібраних щоденних даних продажів за минулий рік, є інформацією. Інформація, як правило, передбачає маніпулювання необробленими даними для отримання вказівки величини, тенденцій, закономірностей у даних для певної мети.
Знання в певній області - це людські переконання або уявлення про відносини між фактами або поняттями, що мають відношення до цієї області. Наприклад, задуманий взаємозв'язок між якістю товару і продажами - це знання. Знання можна розглядати як інформацію, яка полегшує дії.
Після того, як ми розмістили наші дані в контекст, агрегували та проаналізували їх, ми можемо використовувати їх для прийняття рішень для нашої організації. Можна сказати, що таке споживання інформації виробляє знання. Ці знання можна використовувати для прийняття рішень, встановлення політики та навіть сприяння інноваціям.
Явні знання зазвичай стосуються знань, які можуть бути виражені словами або цифрами. Навпаки, мовчазне знання включає в себе прозріння та інтуїцію, і їх важко передати іншій людині за допомогою простих комунікацій.
Очевидно, що коли інформація або явні знання захоплюються і зберігаються в комп'ютері, це стане даними, якщо контекст або намір позбавлені.
Останнім кроком вгору по інформаційних сходах є крок від знань (знаючи багато про тему) до мудрості. Можна сказати, що хтось має мудрість, коли він може об'єднати свої знання та досвід, щоб отримати більш глибоке розуміння теми. Часто потрібно багато років, щоб розвинути мудрість на ту чи іншу тему, і вимагає терпіння.
Великі дані
Майже всі програмні програми вимагають даних, щоб зробити щось корисне. Наприклад, якщо ви редагуєте документ у текстовому процесорі, наприклад Microsoft Word, документ, над яким ви працюєте, є даними. Програмне забезпечення для обробки текстів може маніпулювати даними: створювати новий документ, дублювати документ або змінювати документ. Деякі інші приклади даних: музичний файл MP3, відеофайл, електронна таблиця, веб-сторінка, публікація в соціальних мережах та електронна книга.
Останнім часом великі дані привертають увагу всіх типів організацій. Під терміном розуміються такі масово великі набори даних, що звичайні технології обробки даних не мають достатньої потужності для їх аналізу. Наприклад, Walmart повинен обробляти мільйони транзакцій клієнтів щогодини по всьому світу. Зберігання та аналіз такої кількості даних не під силу традиційним інструментам управління даними. Розуміння та розробка найкращих інструментів та методів управління та аналізу цих великих наборів даних є проблемою, яку намагаються вирішити уряди та підприємства.
Бази даних
Метою багатьох інформаційних систем є перетворення даних в інформацію з метою отримання знань, які можуть бути використані для прийняття рішень. Для цього система повинна вміти приймати дані, дозволяти користувачеві ставити дані в контекст та надавати інструменти для агрегації та аналізу. База даних призначена саме для таких цілей.
Чому бази даних?
Дані є цінним ресурсом в організації. Однак багато людей мало знають про технологію баз даних, але використовують інструменти, що не належать до баз даних, такі як електронна таблиця Excel або документ Word, для зберігання та маніпулювання бізнес-даними або використовують погано розроблені бази даних для бізнес-процесів. В результаті дані є надлишковими, неузгодженими, неточними та пошкодженими. Для невеликого набору даних використання інструментів, що не є базами даних, таких як електронні таблиці, може не викликати серйозних проблем. Однак для великої організації пошкоджені дані можуть привести до серйозних помилок і руйнівних наслідків. Загальні дефекти в управлінні ресурсами даних пояснюються наступним чином.
(1) Відсутність контролю надлишкових даних
Люди часто зберігають надлишкові дані для зручності. Надлишкові дані можуть зробити набір даних неузгодженим. Ми використовуємо наочний приклад, щоб пояснити, чому надлишкові дані шкідливі. Припустимо, в РАГСі є два окремі файли, які зберігають дані учнів: один - зареєстрований реєстр учнів, який записує всіх учнів, які зареєстрували та оплатили навчання, а інший - реєстр учнів, який записує всіх учнів, які отримали оцінки.

Як видно з двох електронних таблиць, ця система управління даними має проблеми. Те, що «Студентка 4567 - Мері Браун, а її спеціальність - фінанси» зберігається не раз. Такі випадки називаються надмірністю даних. Надлишкові дані часто роблять доступ до даних зручним, але можуть бути шкідливими. Наприклад, якщо Мері Браун змінює ім'я або свою спеціальність, то всі її імена і майора, що зберігаються в системі, повинні бути змінені зовсім. Для невеликих систем передачі даних така проблема виглядає банально. Однак, коли система даних величезна, внесення змін до всіх надлишкових даних важко, якщо не неможливо. В результаті надмірності даних може бути пошкоджений весь набір даних.
(2) Порушення цілісності даних
Цілісність даних означає узгодженість між збереженими даними. Ми використовуємо наведений вище наочний приклад, щоб пояснити концепцію цілісності даних і як цілісність даних може бути порушена, якщо система даних є недосконалою. Ви можете виявити, що Алекс Вілсон отримав оцінку в MKT211; однак ви не можете знайти Алекса Вілсона в студентському реєстрі. Тобто два реєстри не є послідовними. Припустимо, у нас є контроль цілісності даних для забезпечення дотримання правил, скажімо, «жоден студент не може отримати оцінку, якщо вона/він не зареєструвався і не заплатив навчання», тоді таке порушення цілісності даних ніколи не може статися.
(3) Покладаючись на людську пам'ять для зберігання та пошуку необхідних даних
Третя поширена помилка в управлінні ресурсами даних - надмірне використання людської пам'яті для пошуку даних. Людина може запам'ятати, які дані зберігаються і де зберігаються дані, але також може помилятися. Якщо частина даних зберігається в незапам'ятованому місці, він фактично був втрачений. В результаті покладатися на людську пам'ять для зберігання та пошуку необхідних даних, весь набір даних з часом стає дезорганізованим.
Щоб уникнути перерахованих вище загальних недоліків в управлінні ресурсами даних, повинна бути застосована технологія баз даних. База даних - це організована сукупність пов'язаних даних. Це організована колекція, тому що в базі даних всі дані описуються і пов'язані з іншими даними. Для цілей цього тексту ми будемо розглядати тільки комп'ютеризовані бази даних.
Хоча це не добре для заміни баз даних, електронні таблиці можуть бути ідеальними інструментами для аналізу даних, що зберігаються в базі даних. Пакет електронних таблиць може бути підключений до певної таблиці або запиту в базі даних і використовується для створення діаграм або аналізу цих даних.
Моделі даних та реляційні бази даних
Бази даних можуть бути організовані різними способами за допомогою різних моделей. Модель даних бази даних являє собою логічну структуру елементів даних та їх взаємозв'язків. Існувало кілька моделей даних. Починаючи з 1980-х років, реляційна модель даних була популяризована. В даний час реляційні системи баз даних зазвичай використовуються в бізнес-організаціях за деякими винятками. Реляційна модель даних проста в розумінні та використанні.
У реляційній базі даних дані організовуються в таблиці (або відносини). Кожна таблиця має набір полів, які визначають структуру даних, що зберігаються в таблиці. Запис - це один екземпляр набору полів у таблиці. Щоб візуалізувати це, подумайте про записи як рядки (або кортеж) таблиці, а поля як стовпці таблиці.
У наведеному нижче прикладі ми маємо таблицю даних студента, причому кожен рядок представляє запис учня, а кожен стовпець представляє один файл запису учня. Спеціальне поле або комбінація полів, що визначає унікальну запис, називається первинним ключем (або ключем). Ключем зазвичай є унікальний ідентифікаційний номер записів.

Проектування бази даних
Припустимо, університет хоче створити шкільну базу даних для відстеження даних. Після опитування кількох людей команда дизайнерів дізнається, що мета впровадження системи полягає в тому, щоб краще зрозуміти успішність студентів та академічні ресурси. З цього команда вирішує, що система повинна відстежувати учнів, їх оцінки, курси та класи. Використовуючи цю інформацію, команда конструкторів визначає, що необхідно створити такі таблиці:
- СТУДЕНТ: ім'я студента, спеціальність та електронна пошта.
- КУРС: назва курсу, можливість зарахування.
- КЛАС: ця таблиця буде співвідносити СТУДЕНТ з КУРСОМ, що дозволяє нам мати будь-якого даного студента, щоб зареєструвати кілька курсів і отримати оцінку для кожного курсу.
- КЛАС: розташування в класі, тип класу та місткість класу
Тепер, коли команда дизайнерів визначила, які таблиці створити, їм потрібно визначити конкретні елементи даних, які буде містити кожна таблиця. Для цього потрібно ідентифікувати поля, які будуть в кожній таблиці. Наприклад, назва курсу буде одним з полів у таблиці COURSE. Нарешті, оскільки це буде реляційна база даних, кожна таблиця повинна мати спільне поле хоча б з однією іншою таблицею (іншими словами, вони повинні мати зв'язки між собою).
Первинний ключ повинен бути обраний для кожної таблиці в реляційній базі даних. Цей ключ є унікальним ідентифікатором для кожного запису в таблиці. Наприклад, у таблиці STUDENT можна використовувати ім'я учня як спосіб ідентифікації студента. Однак більш ніж імовірно, що деякі студенти мають одне і те ж ім'я. Адреса електронної пошти студента може бути хорошим вибором для первинного ключа, оскільки адреси електронної пошти унікальні. Однак первинний ключ не може змінитися, тому це означатиме, що якщо студенти змінили свою адресу електронної пошти, нам доведеться видалити їх з бази даних, а потім повторно вставити їх - не приваблива пропозиція. Наше рішення полягає в тому, щоб використовувати студентський ідентифікатор як первинний ключ таблиці STUDENT. Ми також зробимо це для столу COURSE та столу CLASSROOM. Це рішення досить поширене і є причиною того, що у вас так багато ідентифікаторів! Первинний ключ таблиці може бути лише одним полем, але також може бути комбінацією двох або більше полів. Наприклад, комбінація StudentID і CourseID таблиці GRADE може бути первинним ключем таблиці GRADE, а це означає, що оцінка отримує конкретний студент за конкретний курс.
Наступним кроком проектування бази даних є виявлення та встановлення взаємозв'язків між таблицями, щоб ви могли зібрати дані разом значущими способами. Взаємозв'язок між двома таблицями реалізується за допомогою зовнішнього ключа. Зовнішній ключ - це поле в одній таблиці, яке підключається до даних первинного ключа в вихідній таблиці. Наприклад, ClassroomID в таблиці COURSE - це зовнішній ключ, який підключається до первинного ключа ClassroomID в таблиці CLASSROOM. Завдяки такому дизайну ми не тільки маємо спосіб організувати всі необхідні нам дані і успішно поєднали всю таблицю разом, щоб задовольнити вимоги, але також запобігли введенню недійсних даних в базу даних. Ви можете побачити остаточний дизайн бази даних на малюнку нижче:

Нормалізація
При розробці бази даних однією важливою концепцією, яку слід розуміти, є нормалізація. Простіше кажучи, нормалізувати базу даних означає спроектувати її таким чином, щоб: 1) зменшити надмірність даних; і 2) забезпечити цілісність даних.
У проектуванні шкільної бази даних команда дизайнерів працювала над досягненням цих цілей. Наприклад, для відстеження оцінок, простим (і неправильним) рішенням, можливо, було створити поле Студент в таблиці COURSE, а потім просто перерахувати імена всіх учнів там. Однак ця конструкція означатиме, що якщо студент приймає два або більше курсів, то його або її дані доведеться вводити двічі або більше разів. Це означає, що дані надлишкові. Натомість дизайнери вирішили цю проблему, представивши таблицю GRADE.
У такому дизайні, коли студент реєструється в шкільній системі перед проходженням курсу, ми спочатку повинні додати учня до таблиці STUDENT, де вводяться його ідентифікатор, ім'я, спеціальність та електронна адреса. Тепер ми додамо новий запис, щоб позначити, що студент проходить певний курс. Це досягається шляхом додавання запису з StudentD і CourseID в таблиці GRADE. Якщо цей студент проходить другий курс, нам не потрібно дублювати запис імені студента, спеціальності та електронної пошти; натомість нам потрібно лише зробити ще один запис у таблиці GRADE ID другого курсу та студентського посвідчення.
Дизайн бази даних Школи також дозволяє легко змінювати дизайн без серйозних змін у існуючій структурі. Наприклад, якщо команді дизайнерів було запропоновано додати функціональність до системи для відстеження інструкторів, які викладають курси, ми могли б легко досягти цього, додавши таблицю ПРОФЕСОР (подібно до таблиці STUDENT), а потім додавши нове поле до таблиці COURSE, щоб тримати ідентифікатор професора.
Типи даних
При визначенні полів в таблиці бази даних ми повинні дати кожному полю тип даних. Наприклад, поле StudentName є текстовим рядком, тоді як EnrollmentCapacity — число. Більшість сучасних баз даних дозволяють зберігати кілька різних типів даних. Деякі з найбільш поширених типів даних наведено тут:
- Текст: для зберігання коротких нечислових даних, як правило, менше 256 символів. Конструктор баз даних може визначити максимальну довжину тексту.
- Number: для зберігання чисел. Зазвичай існує кілька різних типів чисел, які можна вибрати, залежно від того, наскільки великою буде найбільша кількість.
- Boolean: тип даних з лише двома можливими значеннями, такими як 0 або 1, «true» або «false», «yes» або «no».
- Дата/час: спеціальна форма типу числових даних, яку можна інтерпретувати як число або час.
- Валюта: спеціальна форма типу числових даних, яка форматує всі значення з показником валюти і двома знаками після коми.
- Текст абзацу: цей тип даних дозволяє використовувати текст довше 256 символів.
- Об'єкт: цей тип даних дозволяє зберігати дані, які неможливо ввести за допомогою клавіатури, наприклад зображення або музичний файл.
Є дві важливі причини того, що ми повинні правильно визначити тип даних поля. По-перше, тип даних повідомляє базі даних, які функції можна виконувати з даними. Наприклад, якщо ми хочемо виконувати математичні функції з одним з полів, ми повинні обов'язково повідомити базі даних, що поле є числовим типом даних. Наприклад, ми можемо відняти пропускну здатність курсу з місткості в класі, щоб дізнатися кількість доступних додаткових місць.
Друга важлива причина визначення типу даних полягає в тому, щоб для наших даних було виділено належну кількість місця для зберігання. Наприклад, якщо поле StudentName визначено як тип даних Text (50), це означає, що для кожного імені, яке ми хочемо зберегти, виділяється 50 символів. Якщо ім'я учня довше 50 символів, база даних буде скорочувати його.
Системи управління базами даних

На комп'ютері база даних виглядає як один або кілька файлів. Для того, щоб дані в базі даних зберігалися, читалися, змінювалися, додавалися або видалялися, програмна програма повинна отримати доступ до них. Багато програмних додатків мають таку здатність: iTunes може читати свою базу даних, щоб дати вам список своїх пісень (і грати пісні); програмне забезпечення вашого мобільного телефону може взаємодіяти зі списком контактів. Але як щодо додатків для створення або управління базою даних? Яке програмне забезпечення ви можете використовувати для створення бази даних, зміни структури бази даних або просто зробити аналіз? Це мета категорії програмних додатків під назвою системи управління базами даних (СУБД).
Пакети СУБД, як правило, надають інтерфейс для перегляду та зміни дизайну бази даних, створення запитів та розробки звітів. Більшість таких пакетів призначені для роботи з певним типом бази даних, але, як правило, сумісні з широким спектром баз даних.
База даних, яка може бути використана лише одним користувачем одночасно, не збирається задовольняти потреби більшості організацій. Оскільки комп'ютери стали мережевими і тепер приєднуються по всьому світу через Інтернет, з'явився клас бази даних, доступ до якого можуть отримати два, десять або навіть мільйон людей. Ці бази даних іноді встановлюються на одному комп'ютері для доступу групи людей в одному місці. Інший раз вони встановлюються на декількох серверах по всьому світу, призначені для доступу мільйонів. На підприємствах реляційні СУБД будуються і підтримуються такими компаніями, як Oracle, Microsoft SQL Server та IBM Db2. MySQL з відкритим вихідним кодом також є базою даних підприємства.
Microsoft Access і Open Office Base є прикладами систем управління персональними базами даних. Ці системи в основному використовуються для розробки та аналізу однокористувацьких баз даних. Ці бази даних не призначені для спільного використання в мережі або в Інтернеті, а замість цього встановлюються на конкретному пристрої і працюють з одним користувачем одночасно. Apache OpenOffice.org Base (див. знімок екрана) можна використовувати для створення, зміни та аналізу баз даних у форматі відкритої бази даних (ODB). СУБД Microsoft Access використовується для роботи з базами даних у власному форматі Microsoft Access Database. І Access, і Base мають можливість читати і записувати в інші формати баз даних, а також.
Мова структурованих запитів
Як тільки у вас є база даних, розроблена і завантажена з даними, як ви будете робити щось корисне з нею? Основним способом роботи з реляційною базою даних є використання Structured Query Language, SQL (вимовляється «продовження» або просто зазначено як S-Q-L). Майже всі програми, які працюють з базами даних (наприклад, системи управління базами даних, розглянуті нижче) використовують SQL як спосіб аналізу та маніпулювання реляційними даними. Як випливає з назви, SQL - це мова, яка може використовуватися для роботи з реляційною базою даних. Від
простий запит даних для складної операції оновлення, SQL є опорою програмістів і адміністраторів баз даних. Щоб дати вам зрозуміти, як може виглядати SQL, ось кілька прикладів використання нашої бази даних School:
Наступний запит буде отримати майора студента Джон Сміт з таблиці STUDENT:
SELECT StudentMajor FROM STUDENT WHERE StudentName = ‘John Smith’;
Наступний запит приведе до переліку загальної кількості учнів у таблиці STUDENT:
SELECT COUNT(*) FROM STUDENT;
SQL може бути вбудований у багатьох комп'ютерних мовах, які використовуються для розробки незалежних від платформи веб-додатків. Поглиблений опис роботи SQL виходить за рамки цього вступного тексту, але ці приклади повинні дати вам уявлення про силу використання SQL для маніпулювання реляційними базами даних. Багато СУБД, такі як Microsoft Access, дозволяють використовувати QBE (Query-by-example), графічний інструмент запиту, для отримання даних за допомогою візуалізованих команд. QBE генерує SQL для вас, і простий у використанні. У порівнянні з SQL, QBE має обмежені функціональні можливості і не може працювати без середовища СУБД.
Інші типи баз даних
Модель реляційної бази даних є найбільш часто використовуваною моделлю бази даних сьогодні. Однак існує багато інших моделей баз даних, які забезпечують різні сильні сторони, ніж реляційна модель. Ієрархічна модель бази даних, популярна в 1960-х і 1970-х роках, об'єднала дані в ієрархію, дозволяючи батьківський/дочірній зв'язок між даними. Документоорієнтована модель дозволила забезпечити більш неструктуроване зберігання даних шляхом розміщення даних у «документах», якими потім можна було б маніпулювати.
Мабуть, найцікавішою новою розробкою є концепція NoSQL (від словосполучення «не тільки SQL»). NoSQL виникла через необхідність вирішення проблеми масштабних баз даних, розкинутих на декількох серверах або навіть по всьому світу. Щоб реляційна база даних працювала належним чином, важливо, щоб лише одна людина могла одночасно маніпулювати фрагментом даних, концепцією, відомою як блокування записів. Але з сьогоднішніми масштабними базами даних (подумайте Google і Amazon) це просто неможливо. База даних NoSQL може працювати з даними більш вільним способом, дозволяючи більш неструктурованому середовищі, передаючи зміни даних з плином часу на всі сервери, які є частиною бази даних.
Як зазначалося раніше, модель реляційної бази даних погано масштабується. Термін масштаб тут відноситься до бази даних стає все більшим і більшим, розподіляється на більшій кількості комп'ютерів, підключених через мережу. Деякі компанії прагнуть надати масштабні рішення для баз даних, перейшовши від реляційної моделі до інших, більш гнучких моделей. Наприклад, Google зараз пропонує App Engine Datastore, який заснований на NoSQL. Розробники можуть використовувати App Engine Datastore для розробки додатків, які отримують доступ до даних з будь-якої точки світу. Amazon.com пропонує кілька служб баз даних для корпоративного використання, включаючи Amazon RDS, який є службою реляційних баз даних, і Amazon DynamoDB, корпоративне рішення NoSQL.
Бічна панель: Що таке метадані?
Під терміном метадані можна розуміти «дані про дані». Прикладами метаданих бази даних є:
- кількість записів
- тип даних поля
- розмір поля
- опис поля
- значення поля за замовчуванням
- правила використання.
Коли розробляється база даних, створюється «словник даних» для зберігання метаданих, визначаючи поля та структуру бази даних.
Пошук цінності в даних: бізнес-аналітика
Зі зростанням Big Data та безліччю нових інструментів та методів, що знаходяться в їх розпорядженні, підприємства вчаться використовувати інформацію на свою користь. Термін бізнес-аналітика використовується для опису процесу, який організації використовують для збору даних, які вони збирають, та аналізу їх в надії отримати конкурентну перевагу. Окрім використання власних даних, що зберігаються у сховищах даних (див. Нижче), фірми часто купують інформацію у брокерів даних, щоб отримати велике уявлення про свої галузі та економіку. Результати цих аналізів можуть стимулювати організаційні стратегії та забезпечити конкурентну перевагу.
Візуалізація даних
Візуалізація даних - це графічне представлення інформації та даних. Ці графічні зображення (такі як діаграми, графіки та карти) можуть швидко узагальнити дані таким чином, що є більш інтуїтивним і може призвести до нових уявлень і розуміння. Подібно до того, як зображення пейзажу може передати набагато більше, ніж абзац тексту, який намагається описати його, графічне зображення даних може швидко мати значення великих обсягів даних. Багато разів візуалізація даних є першим кроком до більш глибокого аналізу та розуміння даних, зібраних організацією. Приклади програмного забезпечення для візуалізації даних включають Tableau та Google Data Studio.
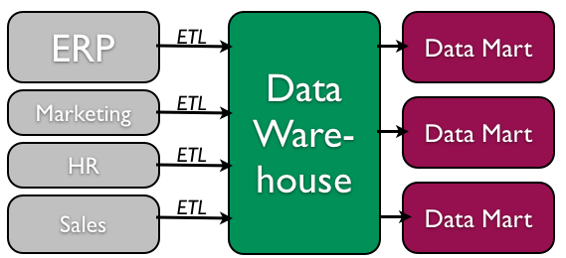
Сховища даних
Оскільки організації почали використовувати бази даних як центральну частину своєї діяльності, необхідність повного розуміння та використання даних, які вони збирають, стає все більш очевидною. Однак безпосередньо аналіз даних, необхідних для щоденних операцій, не є гарною ідеєю; ми не хочемо оподатковувати операції компанії більше, ніж нам потрібно. Крім того, організації також хочуть аналізувати дані в історичному сенсі: Як дані, які ми маємо сьогодні, порівнюються з тим самим набором даних цього разу минулого місяця чи минулого року? З цих потреб виникло поняття сховища даних.
Концепція сховища даних проста: витягти дані з однієї або декількох баз даних організації і завантажити їх в сховище даних (яке саме по собі є іншою базою даних) для зберігання і аналізу. Однак виконання цього поняття не таке вже й просте. Сховище даних повинно бути спроектовано так, щоб воно відповідало наступним критеріям:
- Він використовує неопераційні дані. Це означає, що сховище даних використовує копію даних з активних баз даних, які компанія використовує в своїх повсякденних операціях, тому сховище даних повинно регулярно, за розкладом витягувати дані з існуючих баз даних.
- Дані є варіантами часу. Це означає, що всякий раз, коли дані завантажуються в сховище даних, він отримує мітку часу, яка дозволяє проводити порівняння між різними періодами часу.
- Дані стандартизовані. Оскільки дані в сховищі даних зазвичай надходять з декількох різних джерел, можливо, що дані не використовують однакові визначення або одиниці. Наприклад, кожна база даних використовує власний формат дат (наприклад, mm/dd/yy, або dd/mm/yy, або yy/mm/dd тощо). Для того, щоб сховище даних збігалося з датами, потрібно було б узгодити стандартний формат дати і всі дані, завантажені в сховище даних, повинні бути перетворені для використання цього стандартного формату. Цей процес називається витягування-трансформація-навантаження (ETL).
Існує дві початкові школи думки при проектуванні сховища даних: знизу вгору і зверху вниз. Підхід «знизу вгору» починається зі створення невеликих сховищ даних, які називаються мартами даних, для вирішення конкретних бізнес-проблем. Оскільки ці марти даних створюються, їх можна об'єднати у велике сховище даних. Підхід «зверху вниз» передбачає, що ми повинні почати зі створення загальнокорпоративного сховища даних, а потім, коли конкретні потреби бізнесу визначаються, створити менші вітрини даних зі сховища даних.
Переваги сховищ даних
Організації знаходять сховища даних досить вигідними по ряду причин:
- Процес розробки сховища даних змушує організацію краще розуміти дані, які вона зараз збирає, і, що не менш важливо, які дані не збираються.
- Сховище даних забезпечує централізоване уявлення про всі дані, що збираються по всьому підприємству, і забезпечує засіб для визначення даних, які є суперечливими.
- Після того, як всі дані будуть визначені як послідовні, організація може генерувати «одну версію істини». Це важливо, коли компанія хоче повідомити про себе послідовну статистику, таку як дохід або кількість співробітників.
- Маючи сховище даних, знімки даних можуть бути зроблені з часом. Це створює історичний запис даних, що дозволяє проводити аналіз тенденцій.
- Сховище даних надає інструменти для об'єднання даних, які можуть надавати нову інформацію та аналіз.
Інтелектуальний аналіз даних та машинне навчання
Інтелектуальний аналіз даних - це процес аналізу даних для пошуку раніше невідомих та цікавих тенденцій, закономірностей та асоціацій для прийняття рішень. Як правило, інтелектуальний аналіз даних здійснюється за допомогою автоматизованих засобів проти надзвичайно великих наборів даних, таких як сховище даних. Деякі приклади інтелектуального аналізу даних включають:
- Аналіз продажів з великої продуктової мережі може визначити, що молоко купується частіше на наступний день після дощів у містах з населенням менше 50 000.
- Банк може виявити, що заявники на позику, банківські рахунки яких показують певні моделі депозитів та зняття коштів, не є хорошими кредитними ризиками.
- Бейсбольна команда може виявити, що колегіальні гравці бейсболу з конкретними статистикою в попаданні, пітчинг, і fielding зробити для більш успішних гравців вищої ліги.
Один з методів інтелектуального аналізу даних, який організація може використовувати для проведення цих аналізів, називається машинним навчанням. Машинне навчання використовується для аналізу даних та побудови моделей, не будучи явно запрограмованим для цього. Існують дві основні галузі машинного навчання: навчання під керівництвом та навчання без нагляду.
Контрольоване навчання відбувається, коли організація має дані про минулу діяльність, яка відбулася, і хоче повторити її. Наприклад, якщо вони хочуть створити нову маркетингову кампанію для певної лінійки продуктів, вони можуть переглянути дані минулих маркетингових кампаній, щоб побачити, хто з їх споживачів відгукнувся найбільш сприятливо. Після аналізу створюється модель машинного навчання, яка може бути використана для ідентифікації цих нових клієнтів. Це називається «контрольованим» навчанням, оскільки ми направляємо (контролюємо) аналіз на результат (у нашому прикладі: споживачі, які сприятливо реагують). Методи навчання під наглядом включають такі аналізи, як дерева рішень, нейронні мережі, класифікатори та логістична регресія.
Навчання без нагляду відбувається, коли організація має дані і хоче зрозуміти відносини між різними точками даних. Наприклад, якщо роздрібний продавець хоче зрозуміти закономірності закупівель своїх клієнтів, можна розробити модель навчання без нагляду, щоб з'ясувати, які товари найчастіше купуються разом або як групувати своїх клієнтів за історією покупок. Це називається «неконтрольованим» навчанням, тому що не очікується жодного конкретного результату. Методи навчання без нагляду включають кластеризацію та правила асоціації.
Проблеми конфіденційності
Зростаюча потужність інтелектуального аналізу даних викликало занепокоєння у багатьох, особливо в області конфіденційності. У сучасному цифровому світі стає простіше, ніж будь-коли, брати дані з розрізнених джерел і поєднувати їх для проведення нових форм аналізу. Насправді навколо цієї технології виникла ціла галузь: брокери даних. Ці фірми поєднують загальнодоступні дані з інформацією, отриманою від уряду та інших джерел, щоб створити величезні сховища даних про людей та компанії, які вони потім можуть продавати. Ця тема буде розглянута набагато докладніше в главі 12 — главі про етичні проблеми інформаційних систем.
Бічна панель: Що таке наука про дані? Що таке аналітика даних?
Термін «наука про дані» - популярний термін, призначений для опису аналізу великих наборів даних для пошуку нових знань. Протягом останніх кількох років вона вважається однією з найкращих галузей кар'єри, в яку можна потрапити завдяки вибуховому зростанню та високим зарплатам. Хоча вчений даних робить багато різних речей, їх фокус, як правило, на аналізі великих наборів даних, використовуючи різні методи програмування та програмні засоби для створення нових знань для їх організації. Науковці з даних мають кваліфікацію в техніках машинного навчання та візуалізації даних. Сфера науки про дані постійно змінюється, і вчені даних знаходяться на передовій роботи в таких областях, як штучний інтелект і нейронні мережі.
Управління знаннями
Закінчуємо главу обговоренням концепції управління знаннями (КМ). Всі компанії накопичують знання протягом свого існування. Деякі з цих знань записуються або зберігаються, але не організовано. Значна частина цих знань не записана; натомість вони зберігаються всередині керівників своїх співробітників. Управління знаннями - це процес створення, формалізації захоплення, індексації, зберігання та обміну знаннями компанії, щоб отримати вигоду з досвіду та розуміння, які компанія захопила за час свого існування.
Резюме
У цьому розділі ми дізналися про роль, яку відіграють дані та бази даних в контексті інформаційних систем. Дані складаються з фактів світу. Якщо ви обробляєте дані в певному контексті, то у вас є інформація. Знання отримують, коли інформація споживається і використовується для прийняття рішень. База даних - це організована сукупність пов'язаних даних. Реляційні бази даних є найбільш широко використовуваним типом бази даних, де дані структуровані в таблиці і всі таблиці повинні бути пов'язані один з одним за допомогою унікальних ідентифікаторів. Система управління базами даних (СУБД) - це програмний додаток, який використовується для створення та управління базами даних, і може мати форму персональної СУБД, використовуваної однією людиною, або СУБД підприємства, які можуть використовуватися декількома користувачами. Сховище даних - це особлива форма бази даних, яка бере дані з інших баз даних на підприємстві і організовує їх для аналізу. Інтелектуальний аналіз даних - це процес пошуку закономірностей та взаємозв'язків у великих масивах даних. Багато підприємств використовують бази даних, сховища даних та методи інтелектуального аналізу даних, щоб виробляти бізнес-аналітику та отримати конкурентну перевагу.
Навчальні питання
- У чому різниця між даними, інформацією та знаннями?
- Поясніть своїми словами, як компонент даних відноситься до апаратних і програмних компонентів інформаційних систем.
- У чому різниця між кількісними даними і якісними даними? В яких ситуаціях число 42 можна вважати якісними даними?
- Які характеристики реляційної бази даних?
- Коли використання персональної СУБД має сенс?
- У чому різниця між електронною таблицею та базою даних? Перерахуйте три відмінності між ними.
- Опишіть, що означає термін нормалізація.
- Чому важливо визначити тип даних поля при проектуванні реляційної бази даних?
- Назвіть базу даних, з якою ви часто взаємодієте. Якими були б деякі з імен полів?
- Що таке метадані?
- Назвіть три переваги використання сховища даних.
- Що таке інтелектуальний аналіз даних?
- Своїми словами поясніть різницю між контрольованим навчанням та навчанням без нагляду. Наведіть приклад кожного (не з книги).
Вправи
- Перегляньте дизайн бази даних Школи раніше в цьому розділі. Переглядаючи наведені списки типів даних, які типи даних ви б присвоїли кожному з полів у кожній з таблиць. Яку довжину ви б присвоїли текстовим полям?
- Завантажте Apache OpenOffice.org і скористайтеся інструментом бази даних, щоб відкрити файл «Student Clubs.odb», доступний тут. Знайдіть деякий час, щоб дізнатися, як змінити структуру бази даних, а потім подивитися, чи можете ви додати необхідні елементи для підтримки відстеження викладачів, як описано в кінці розділу Нормалізація в главі. Ось посилання на документацію «Початок роботи».
- Використовуючи Microsoft Access, завантажте файл бази даних вичерпної статистики бейсболу з сайту Seanlahman.com. (Якщо у вас немає Microsoft Access, ви можете завантажити скорочену версію файлу тут, сумісну з Apache Open Office). Перегляньте структуру таблиць, включених до бази даних. Придумайте три різні експерименти з інтелектуального аналізу даних, які ви хотіли б спробувати, і поясніть, які поля в яких таблицях доведеться аналізувати.
- Проведіть оригінальні дослідження та знайдіть два приклади інтелектуального аналізу даних. Підсумуйте кожен приклад, а потім напишіть про те, що спільного у двох прикладів.
- Провести окремі незалежні дослідження процесу бізнес-аналітики. Використовуючи принаймні два наукові або практичні джерела, напишіть двосторінковий документ, що дає приклади того, як використовується бізнес-аналітика.
- Провести незалежні дослідження новітніх технологій, що використовуються для управління знаннями. Використовуючи принаймні два наукові або практичні джерела, напишіть двосторінковий документ з прикладами програмних додатків або нових технологій, що використовуються в цій галузі.